 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular BEV Perception of Road Scenes via Front-to-Top View Projection
Nov 15, 2022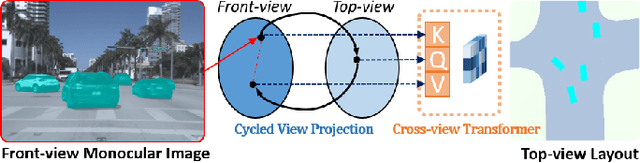



HD map reconstruction is crucial for autonomous driving. LiDAR-based methods are limited due to expensive sensors and time-consuming computation. Camera-based methods usually need to perform road segmentation and view transformation separately, which often causes distortion and missing content. To push the limits of the technology, we present a novel framework that reconstructs a local map formed by road layout and vehicle occupancy in the bird's-eye view given a front-view monocular image only. We propose a front-to-top view projection (FTVP) module, which takes the constraint of cycle consistency between views into account and makes full use of their correlation to strengthen the view transformation and scene understanding. In addition, we also apply multi-scale FTVP modules to propagate the rich spatial information of low-level features to mitigate spatial deviation of the predicted object location. Experiments on public benchmarks show that our method achieves the state-of-the-art performance in the tasks of road layout estimation, vehicle occupancy estimation, and multi-class semantic estimation. For multi-class semantic estimation, in particular, our model outperforms all competitors by a large margin. Furthermore, our model runs at 25 FPS on a single GPU, which is efficient and applicable for real-time panorama HD map reconstruction.
From Contexts to Locality: Ultra-high Resolution Image Segmentation via Locality-aware Contextual Correlation
Sep 06, 2021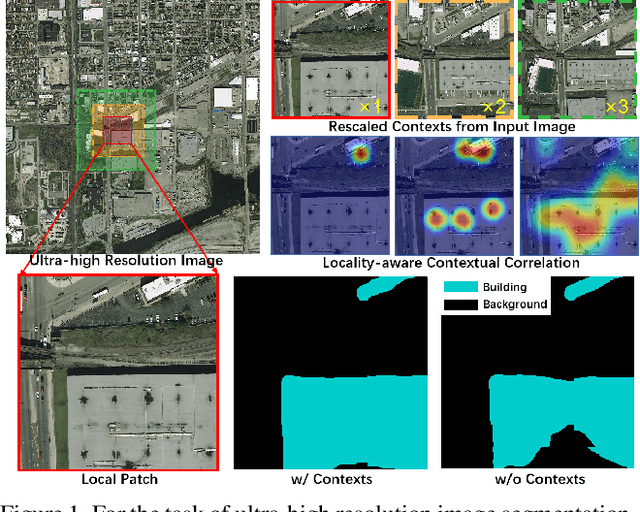
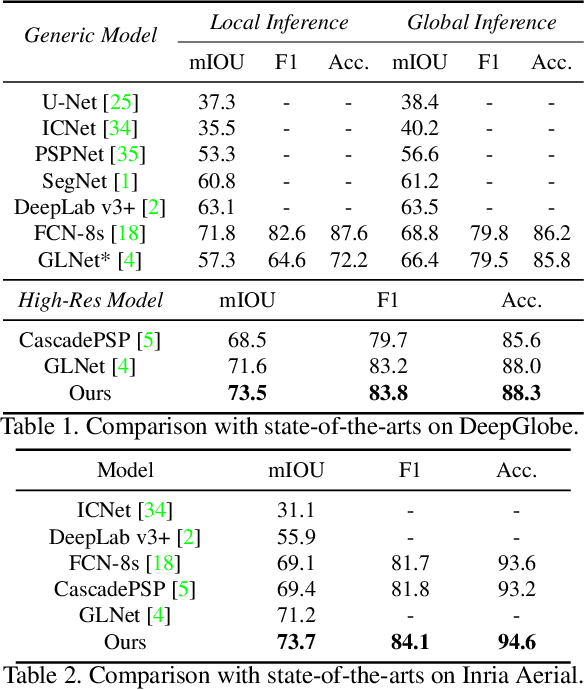
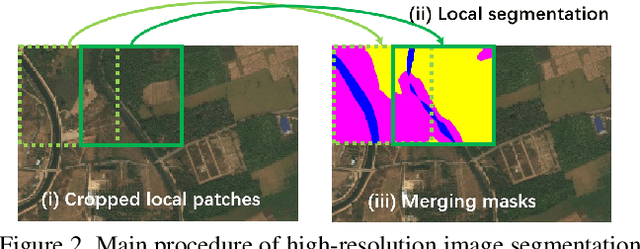
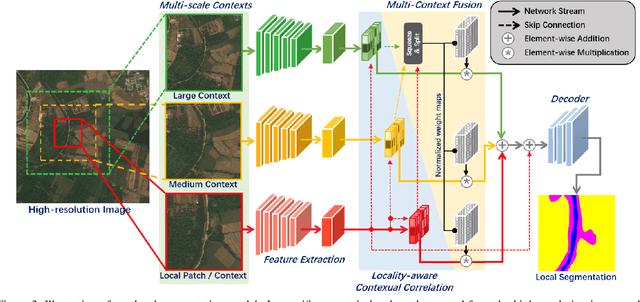
Ultra-high resolution image segmentation has raised increasing interests in recent years due to its realistic applications. In this paper, we innovate the widely used high-resolution image segmentation pipeline, in which an ultra-high resolution image is partitioned into regular patches for local segmentation and then the local results are merged into a high-resolution semantic mask. In particular, we introduce a novel locality-aware contextual correlation based segmentation model to process local patches, where the relevance between local patch and its various contexts are jointly and complementarily utilized to handle the semantic regions with large variations. Additionally, we present a contextual semantics refinement network that associates the local segmentation result with its contextual semantics, and thus is endowed with the ability of reducing boundary artifacts and refining mask contours during the generation of final high-resolution mask. Furthermore, in comprehensive experiments, we demonstrate that our model outperforms other state-of-the-art methods in public benchmarks. Our released codes are available at https://github.com/liqiokkk/FCtL.