 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure-Aware Bimanual Teleoperation via Conservative Value Guided Assistance
Feb 01, 2026Teleoperation of high-precision manipulation is con-strained by tight success tolerances and complex contact dy-namics, which make impending failures difficult for human operators to anticipate under partial observability. This paper proposes a value-guided, failure-aware framework for bimanual teleoperation that provides compliant haptic assistance while pre-serving continuous human authority. The framework is trained entirely from heterogeneous offline teleoperation data containing both successful and failed executions. Task feasibility is mod-eled as a conservative success score learned via Conservative Value Learning, yielding a risk-sensitive estimate that remains reliable under distribution shift. During online operation, the learned success score regulates the level of assistance, while a learned actor provides a corrective motion direction. Both are integrated through a joint-space impedance interface on the master side, yielding continuous guidance that steers the operator away from failure-prone actions without overriding intent. Experimental results on contact-rich manipulation tasks demonstrate improved task success rates and reduced operator workload compared to conventional teleoperation and shared-autonomy baselines, indicating that conservative value learning provides an effective mechanism for embedding failure awareness into bilateral teleoperation. Experimental videos are available at https://www.youtube.com/watch?v=XDTsvzEkDRE
UniBiDex: A Unified Teleoperation Framework for Robotic Bimanual Dexterous Manipulation
Jan 08, 2026We present UniBiDex a unified teleoperation framework for robotic bimanual dexterous manipulation that supports both VRbased and leaderfollower input modalities UniBiDex enables realtime contactrich dualarm teleoperation by integrating heterogeneous input devices into a shared control stack with consistent kinematic treatment and safety guarantees The framework employs nullspace control to optimize bimanual configurations ensuring smooth collisionfree and singularityaware motion across tasks We validate UniBiDex on a longhorizon kitchentidying task involving five sequential manipulation subtasks demonstrating higher task success rates smoother trajectories and improved robustness compared to strong baselines By releasing all hardware and software components as opensource we aim to lower the barrier to collecting largescale highquality human demonstration datasets and accelerate progress in robot learning.
iFlyBot-VLM Technical Report
Nov 07, 2025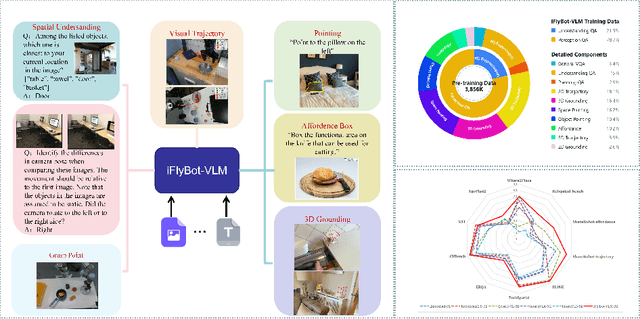

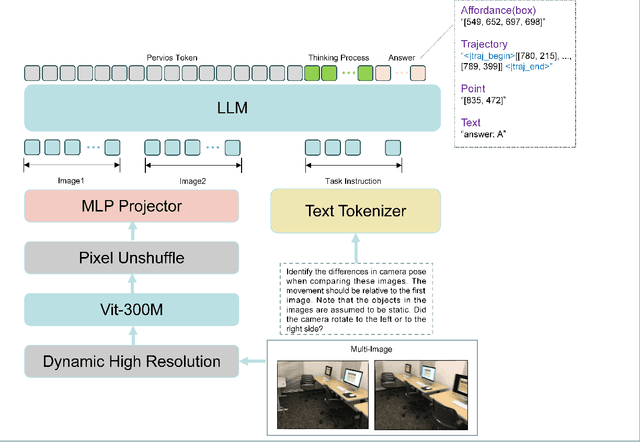
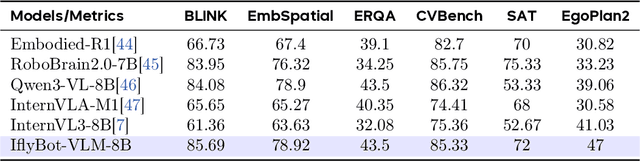
We introduce iFlyBot-VLM, a general-purpose Vision-Language Model (VLM) used to improve the domain of Embodied Intelligence. The central objective of iFlyBot-VLM is to bridge the cross-modal semantic gap between high-dimensional environmental perception and low-level robotic motion control. To this end, the model abstracts complex visual and spatial information into a body-agnostic and transferable Operational Language, thereby enabling seamless perception-action closed-loop coordination across diverse robotic platforms. The architecture of iFlyBot-VLM is systematically designed to realize four key functional capabilities essential for embodied intelligence: 1) Spatial Understanding and Metric Reasoning; 2) Interactive Target Grounding; 3) Action Abstraction and Control Parameter Generation; 4) Task Planning and Skill Sequencing. We envision iFlyBot-VLM as a scalable and generalizable foundation model for embodied AI, facilitating the progression from specialized task-oriented systems toward generalist, cognitively capable agents. We conducted evaluations on 10 current mainstream embodied intelligence-related VLM benchmark datasets, such as Blink and Where2Place, and achieved optimal performance while preserving the model's general capabilities. We will publicly release both the training data and model weights to foster further research and development in the field of Embodied Intelligence.
One-DoF Robotic Design of Overconstrained Limbs with Energy-Efficient, Self-Collision-Free Motion
Sep 26, 2025While it is expected to build robotic limbs with multiple degrees of freedom (DoF) inspired by nature, a single DoF design remains fundamental, providing benefits that include, but are not limited to, simplicity, robustness, cost-effectiveness, and efficiency. Mechanisms, especially those with multiple links and revolute joints connected in closed loops, play an enabling factor in introducing motion diversity for 1-DoF systems, which are usually constrained by self-collision during a full-cycle range of motion. This study presents a novel computational approach to designing one-degree-of-freedom (1-DoF) overconstrained robotic limbs for a desired spatial trajectory, while achieving energy-efficient, self-collision-free motion in full-cycle rotations. Firstly, we present the geometric optimization problem of linkage-based robotic limbs in a generalized formulation for self-collision-free design. Next, we formulate the spatial trajectory generation problem with the overconstrained linkages by optimizing the similarity and dynamic-related metrics. We further optimize the geometric shape of the overconstrained linkage to ensure smooth and collision-free motion driven by a single actuator. We validated our proposed method through various experiments, including personalized automata and bio-inspired hexapod robots. The resulting hexapod robot, featuring overconstrained robotic limbs, demonstrated outstanding energy efficiency during forward walking.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025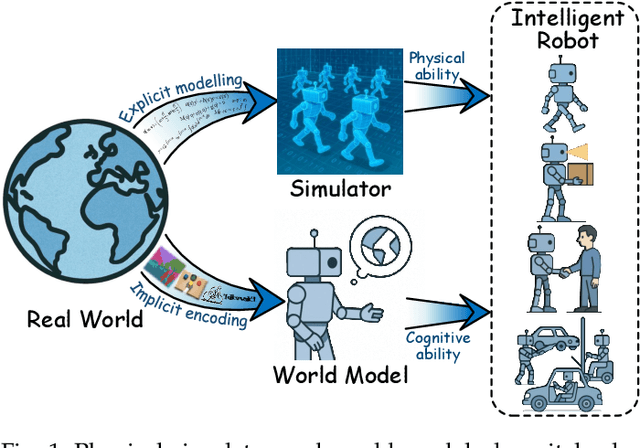
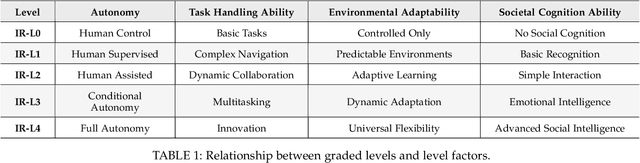
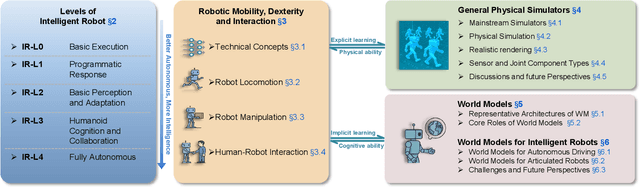

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
SViP: Sequencing Bimanual Visuomotor Policies with Object-Centric Motion Primitives
Jun 23, 2025Imitation learning (IL), particularly when leveraging high-dimensional visual inputs for policy training, has proven intuitive and effective in complex bimanual manipulation tasks. Nonetheless, the generalization capability of visuomotor policies remains limited, especially when small demonstration datasets are available. Accumulated errors in visuomotor policies significantly hinder their ability to complete long-horizon tasks. To address these limitations, we propose SViP, a framework that seamlessly integrates visuomotor policies into task and motion planning (TAMP). SViP partitions human demonstrations into bimanual and unimanual operations using a semantic scene graph monitor. Continuous decision variables from the key scene graph are employed to train a switching condition generator. This generator produces parameterized scripted primitives that ensure reliable performance even when encountering out-of-the-distribution observations. Using only 20 real-world demonstrations, we show that SViP enables visuomotor policies to generalize across out-of-distribution initial conditions without requiring object pose estimators. For previously unseen tasks, SViP automatically discovers effective solutions to achieve the goal, leveraging constraint modeling in TAMP formulism. In real-world experiments, SViP outperforms state-of-the-art generative IL methods, indicating wider applicability for more complex tasks. Project website: https://sites.google.com/view/svip-bimanual
iPad: Iterative Proposal-centric End-to-End Autonomous Driving
May 21, 2025End-to-end (E2E) autonomous driving systems offer a promising alternative to traditional modular pipelines by reducing information loss and error accumulation, with significant potential to enhance both mobility and safety. However, most existing E2E approaches directly generate plans based on dense bird's-eye view (BEV) grid features, leading to inefficiency and limited planning awareness. To address these limitations, we propose iterative Proposal-centric autonomous driving (iPad), a novel framework that places proposals - a set of candidate future plans - at the center of feature extraction and auxiliary tasks. Central to iPad is ProFormer, a BEV encoder that iteratively refines proposals and their associated features through proposal-anchored attention, effectively fusing multi-view image data. Additionally, we introduce two lightweight, proposal-centric auxiliary tasks - mapping and prediction - that improve planning quality with minimal computational overhead. Extensive experiments on the NAVSIM and CARLA Bench2Drive benchmarks demonstrate that iPad achieves state-of-the-art performance while being significantly more efficient than prior leading methods.
Internal State Estimation in Groups via Active Information Gathering
May 15, 2025Accurately estimating human internal states, such as personality traits or behavioral patterns, is critical for enhancing the effectiveness of human-robot interaction, particularly in group settings. These insights are key in applications ranging from social navigation to autism diagnosis. However, prior methods are limited by scalability and passive observation, making real-time estimation in complex, multi-human settings difficult. In this work, we propose a practical method for active human personality estimation in groups, with a focus on applications related to Autism Spectrum Disorder (ASD). Our method combines a personality-conditioned behavior model, based on the Eysenck 3-Factor theory, with an active robot information gathering policy that triggers human behaviors through a receding-horizon planner. The robot's belief about human personality is then updated via Bayesian inference. We demonstrate the effectiveness of our approach through simulations, user studies with typical adults, and preliminary experiments involving participants with ASD. Our results show that our method can scale to tens of humans and reduce personality prediction error by 29.2% and uncertainty by 79.9% in simulation. User studies with typical adults confirm the method's ability to generalize across complex personality distributions. Additionally, we explore its application in autism-related scenarios, demonstrating that the method can identify the difference between neurotypical and autistic behavior, highlighting its potential for diagnosing ASD. The results suggest that our framework could serve as a foundation for future ASD-specific interventions.
GauSS-MI: Gaussian Splatting Shannon Mutual Information for Active 3D Reconstruction
Apr 29, 2025



This research tackles the challenge of real-time active view selection and uncertainty quantification on visual quality for active 3D reconstruction. Visual quality is a critical aspect of 3D reconstruction. Recent advancements such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have notably enhanced the image rendering quality of reconstruction models. Nonetheless, the efficient and effective acquisition of input images for reconstruction-specifically, the selection of the most informative viewpoint-remains an open challenge, which is crucial for active reconstruction. Existing studies have primarily focused on evaluating geometric completeness and exploring unobserved or unknown regions, without direct evaluation of the visual uncertainty within the reconstruction model. To address this gap, this paper introduces a probabilistic model that quantifies visual uncertainty for each Gaussian. Leveraging Shannon Mutual Information, we formulate a criterion, Gaussian Splatting Shannon Mutual Information (GauSS-MI), for real-time assessment of visual mutual information from novel viewpoints, facilitating the selection of next best view. GauSS-MI is implemented within an active reconstruction system integrated with a view and motion planner. Extensive experiments across various simulated and real-world scenes showcase the superior visual quality and reconstruction efficiency performance of the proposed system.
CRUST-Bench: A Comprehensive Benchmark for C-to-safe-Rust Transpilation
Apr 21, 2025C-to-Rust transpilation is essential for modernizing legacy C code while enhancing safety and interoperability with modern Rust ecosystems. However, no dataset currently exists for evaluating whether a system can transpile C into safe Rust that passes a set of test cases. We introduce CRUST-Bench, a dataset of 100 C repositories, each paired with manually-written interfaces in safe Rust as well as test cases that can be used to validate correctness of the transpilation. By considering entire repositories rather than isolated functions, CRUST-Bench captures the challenges of translating complex projects with dependencies across multiple files. The provided Rust interfaces provide explicit specifications that ensure adherence to idiomatic, memory-safe Rust patterns, while the accompanying test cases enforce functional correctness. We evaluate state-of-the-art large language models (LLMs) on this task and find that safe and idiomatic Rust generation is still a challenging problem for various state-of-the-art methods and techniques. We also provide insights into the errors LLMs usually make in transpiling code from C to safe Rust. The best performing model, OpenAI o1, is able to solve only 15 tasks in a single-shot setting. Improvements on CRUST-Bench would lead to improved transpilation systems that can reason about complex scenarios and help in migrating legacy codebases from C into languages like Rust that ensure memory safety. You can find the dataset and code at https://github.com/anirudhkhatry/CRUST-bench.