 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Structure to Detail: Hierarchical Distillation for Efficient Diffusion Model
Nov 12, 2025The inference latency of diffusion models remains a critical barrier to their real-time application. While trajectory-based and distribution-based step distillation methods offer solutions, they present a fundamental trade-off. Trajectory-based methods preserve global structure but act as a "lossy compressor", sacrificing high-frequency details. Conversely, distribution-based methods can achieve higher fidelity but often suffer from mode collapse and unstable training. This paper recasts them from independent paradigms into synergistic components within our novel Hierarchical Distillation (HD) framework. We leverage trajectory distillation not as a final generator, but to establish a structural ``sketch", providing a near-optimal initialization for the subsequent distribution-based refinement stage. This strategy yields an ideal initial distribution that enhances the ceiling of overall performance. To further improve quality, we introduce and refine the adversarial training process. We find standard discriminator structures are ineffective at refining an already high-quality generator. To overcome this, we introduce the Adaptive Weighted Discriminator (AWD), tailored for the HD pipeline. By dynamically allocating token weights, AWD focuses on local imperfections, enabling efficient detail refinement. Our approach demonstrates state-of-the-art performance across diverse tasks. On ImageNet $256\times256$, our single-step model achieves an FID of 2.26, rivaling its 250-step teacher. It also achieves promising results on the high-resolution text-to-image MJHQ benchmark, proving its generalizability. Our method establishes a robust new paradigm for high-fidelity, single-step diffusion models.
DAWN: Dynamic Frame Avatar with Non-autoregressive Diffusion Framework for Talking Head Video Generation
Oct 17, 2024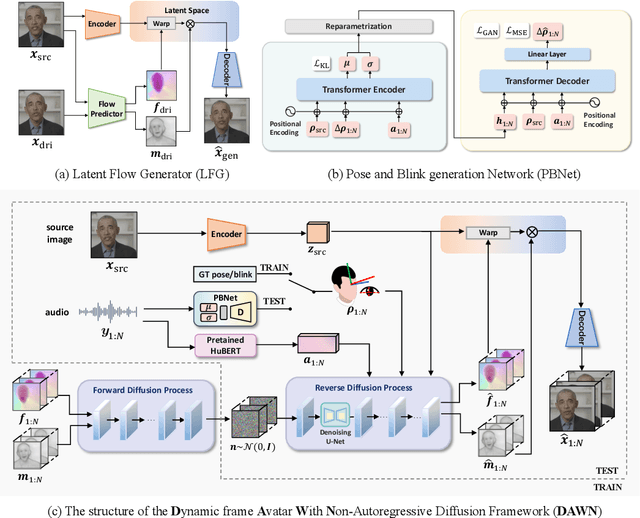
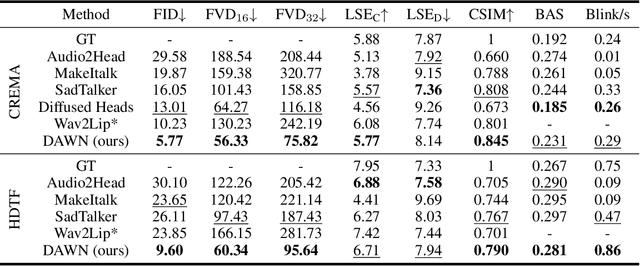


Talking head generation intends to produce vivid and realistic talking head videos from a single portrait and speech audio clip. Although significant progress has been made in diffusion-based talking head generation, almost all methods rely on autoregressive strategies, which suffer from limited context utilization beyond the current generation step, error accumulation, and slower generation speed. To address these challenges, we present DAWN (Dynamic frame Avatar With Non-autoregressive diffusion), a framework that enables all-at-once generation of dynamic-length video sequences. Specifically, it consists of two main components: (1) audio-driven holistic facial dynamics generation in the latent motion space, and (2) audio-driven head pose and blink generation. Extensive experiments demonstrate that our method generates authentic and vivid videos with precise lip motions, and natural pose/blink movements. Additionally, with a high generation speed, DAWN possesses strong extrapolation capabilities, ensuring the stable production of high-quality long videos. These results highlight the considerable promise and potential impact of DAWN in the field of talking head video generation. Furthermore, we hope that DAWN sparks further exploration of non-autoregressive approaches in diffusion models. Our code will be publicly at https://github.com/Hanbo-Cheng/DAWN-pytorch.
Bidirectional Trained Tree-Structured Decoder for Handwritten Mathematical Expression Recognition
Dec 31, 2023The Handwritten Mathematical Expression Recognition (HMER) task is a critical branch in the field of OCR. Recent studies have demonstrated that incorporating bidirectional context information significantly improves the performance of HMER models. However, existing methods fail to effectively utilize bidirectional context information during the inference stage. Furthermore, current bidirectional training methods are primarily designed for string decoders and cannot adequately generalize to tree decoders, which offer superior generalization capabilities and structural analysis capacity. In order to overcome these limitations, we propose the Mirror-Flipped Symbol Layout Tree (MF-SLT) and Bidirectional Asynchronous Training (BAT) structure. Our method extends the bidirectional training strategy to the tree decoder, allowing for more effective training by leveraging bidirectional information. Additionally, we analyze the impact of the visual and linguistic perception of the HMER model separately and introduce the Shared Language Modeling (SLM) mechanism. Through the SLM, we enhance the model's robustness and generalization when dealing with visual ambiguity, particularly in scenarios with abundant training data. Our approach has been validated through extensive experiments, demonstrating its ability to achieve new state-of-the-art results on the CROHME 2014, 2016, and 2019 datasets, as well as the HME100K dataset. The code used in our experiments will be publicly available.