 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEARL: Training Socratic Tutors with Pedagogically Aligned Reinforcement Learning
May 28, 2026Large Language Models (LLMs) have shown promise as educational tutors, yet effective tutoring requires more than solving problems: it must provide progressive Socratic guidance and balance multiple pedagogical objectives across multi-turn interactions. However, training such tutors remains challenging due to limited-fidelity and weakly controllable student simulation, under-specified pedagogical reward modeling, and unstable multi-objective optimization. To overcome these limitations, we propose PEARL, a pedagogically aligned reinforcement learning framework for training Socratic tutoring agents, consisting of three key components. First, we introduce a controllable student simulator that decouples latent cognitive states from response generation to model diverse abilities and misconceptions. Second, we develop a generative reward model that jointly evaluates pedagogical quality and objective correctness for policy optimization. Finally, we propose a stable multi-objective RL scheme that discretizes rewards within each dimension and aggregates normalized advantages across dimensions, preventing high-variance objectives from dominating updates. Experiments on multiple benchmarks show that PEARL achieves the best performance among open-source models and remains competitive with leading proprietary LLMs, despite using only a 30B policy model.
Step Potential Advantage Estimation: Harnessing Intermediate Confidence and Correctness for Efficient Mathematical Reasoning
Jan 07, 2026Reinforcement Learning with Verifiable Rewards (RLVR) elicits long chain-of-thought reasoning in large language models (LLMs), but outcome-based rewards lead to coarse-grained advantage estimation. While existing approaches improve RLVR via token-level entropy or sequence-level length control, they lack a semantically grounded, step-level measure of reasoning progress. As a result, LLMs fail to distinguish necessary deduction from redundant verification: they may continue checking after reaching a correct solution and, in extreme cases, overturn a correct trajectory into an incorrect final answer. To remedy the lack of process supervision, we introduce a training-free probing mechanism that extracts intermediate confidence and correctness and combines them into a Step Potential signal that explicitly estimates the reasoning state at each step. Building on this signal, we propose Step Potential Advantage Estimation (SPAE), a fine-grained credit assignment method that amplifies potential gains, penalizes potential drops, and applies penalty after potential saturates to encourage timely termination. Experiments across multiple benchmarks show SPAE consistently improves accuracy while substantially reducing response length, outperforming strong RL baselines and recent efficient reasoning and token-level advantage estimation methods. The code is available at https://github.com/cii030/SPAE-RL.
Enhancing the Geometric Problem-Solving Ability of Multimodal LLMs via Symbolic-Neural Integration
Apr 17, 2025Recent advances in Multimodal Large Language Models (MLLMs) have achieved remarkable progress in general domains and demonstrated promise in multimodal mathematical reasoning. However, applying MLLMs to geometry problem solving (GPS) remains challenging due to lack of accurate step-by-step solution data and severe hallucinations during reasoning. In this paper, we propose GeoGen, a pipeline that can automatically generates step-wise reasoning paths for geometry diagrams. By leveraging the precise symbolic reasoning, \textbf{GeoGen} produces large-scale, high-quality question-answer pairs. To further enhance the logical reasoning ability of MLLMs, we train \textbf{GeoLogic}, a Large Language Model (LLM) using synthetic data generated by GeoGen. Serving as a bridge between natural language and symbolic systems, GeoLogic enables symbolic tools to help verifying MLLM outputs, making the reasoning process more rigorous and alleviating hallucinations. Experimental results show that our approach consistently improves the performance of MLLMs, achieving remarkable results on benchmarks for geometric reasoning tasks. This improvement stems from our integration of the strengths of LLMs and symbolic systems, which enables a more reliable and interpretable approach for the GPS task. Codes are available at https://github.com/ycpNotFound/GeoGen.
Skeleton and Font Generation Network for Zero-shot Chinese Character Generation
Jan 14, 2025



Automatic font generation remains a challenging research issue, primarily due to the vast number of Chinese characters, each with unique and intricate structures. Our investigation of previous studies reveals inherent bias capable of causing structural changes in characters. Specifically, when generating a Chinese character similar to, but different from, those in the training samples, the bias is prone to either correcting or ignoring these subtle variations. To address this concern, we propose a novel Skeleton and Font Generation Network (SFGN) to achieve a more robust Chinese character font generation. Our approach includes a skeleton builder and font generator. The skeleton builder synthesizes content features using low-resource text input, enabling our technique to realize font generation independently of content image inputs. Unlike previous font generation methods that treat font style as a global embedding, we introduce a font generator to align content and style features on the radical level, which is a brand-new perspective for font generation. Except for common characters, we also conduct experiments on misspelled characters, a substantial portion of which slightly differs from the common ones. Our approach visually demonstrates the efficacy of generated images and outperforms current state-of-the-art font generation methods. Moreover, we believe that misspelled character generation have significant pedagogical implications and verify such supposition through experiments. We used generated misspelled characters as data augmentation in Chinese character error correction tasks, simulating the scenario where students learn handwritten Chinese characters with the help of misspelled characters. The significantly improved performance of error correction tasks demonstrates the effectiveness of our proposed approach and the value of misspelled character generation.
RFL: Simplifying Chemical Structure Recognition with Ring-Free Language
Dec 10, 2024



The primary objective of Optical Chemical Structure Recognition is to identify chemical structure images into corresponding markup sequences. However, the complex two-dimensional structures of molecules, particularly those with rings and multiple branches, present significant challenges for current end-to-end methods to learn one-dimensional markup directly. To overcome this limitation, we propose a novel Ring-Free Language (RFL), which utilizes a divide-and-conquer strategy to describe chemical structures in a hierarchical form. RFL allows complex molecular structures to be decomposed into multiple parts, ensuring both uniqueness and conciseness while enhancing readability. This approach significantly reduces the learning difficulty for recognition models. Leveraging RFL, we propose a universal Molecular Skeleton Decoder (MSD), which comprises a skeleton generation module that progressively predicts the molecular skeleton and individual rings, along with a branch classification module for predicting branch information. Experimental results demonstrate that the proposed RFL and MSD can be applied to various mainstream methods, achieving superior performance compared to state-of-the-art approaches in both printed and handwritten scenarios. The code is available at https://github.com/JingMog/RFL-MSD.
See then Tell: Enhancing Key Information Extraction with Vision Grounding
Sep 29, 2024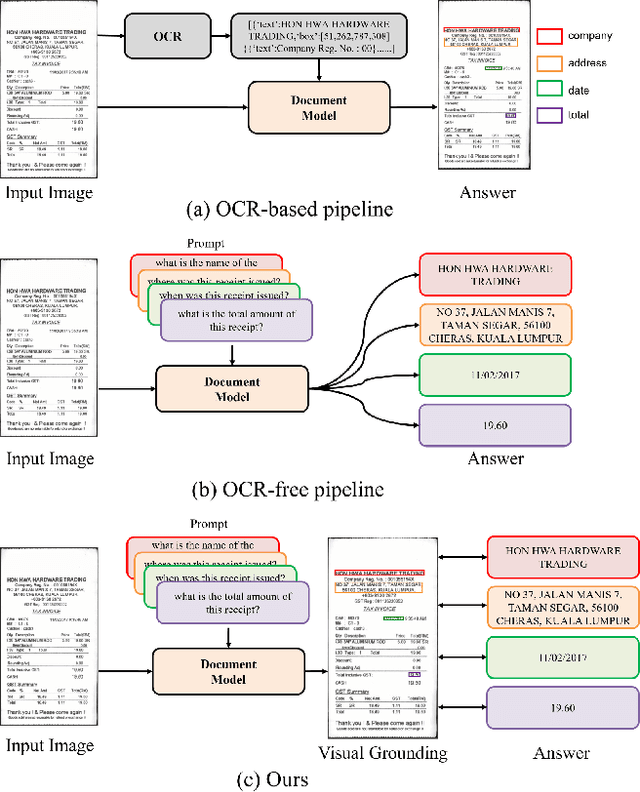
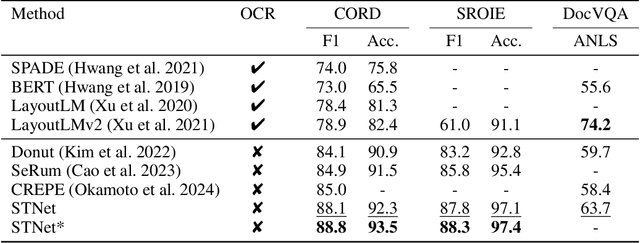
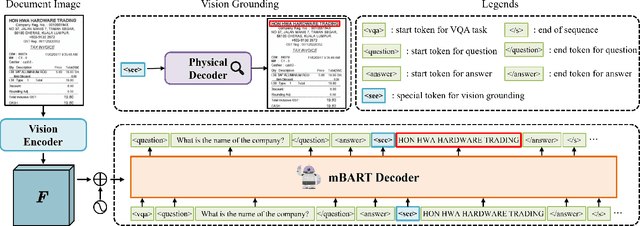

In the digital era, the ability to understand visually rich documents that integrate text, complex layouts, and imagery is critical. Traditional Key Information Extraction (KIE) methods primarily rely on Optical Character Recognition (OCR), which often introduces significant latency, computational overhead, and errors. Current advanced image-to-text approaches, which bypass OCR, typically yield plain text outputs without corresponding vision grounding. In this paper, we introduce STNet (See then Tell Net), a novel end-to-end model designed to deliver precise answers with relevant vision grounding. Distinctively, STNet utilizes a unique <see> token to observe pertinent image areas, aided by a decoder that interprets physical coordinates linked to this token. Positioned at the outset of the answer text, the <see> token allows the model to first see--observing the regions of the image related to the input question--and then tell--providing articulated textual responses. To enhance the model's seeing capabilities, we collect extensive structured table recognition datasets. Leveraging the advanced text processing prowess of GPT-4, we develop the TVG (TableQA with Vision Grounding) dataset, which not only provides text-based Question Answering (QA) pairs but also incorporates precise vision grounding for these pairs. Our approach demonstrates substantial advancements in KIE performance, achieving state-of-the-art results on publicly available datasets such as CORD, SROIE, and DocVQA. The code will also be made publicly available.
DocMamba: Efficient Document Pre-training with State Space Model
Sep 18, 2024



In recent years, visually-rich document understanding has attracted increasing attention. Transformer-based pre-trained models have become the mainstream approach, yielding significant performance gains in this field. However, the self-attention mechanism's quadratic computational complexity hinders their efficiency and ability to process long documents. In this paper, we present DocMamba, a novel framework based on the state space model. It is designed to reduce computational complexity to linear while preserving global modeling capabilities. To further enhance its effectiveness in document processing, we introduce the Segment-First Bidirectional Scan (SFBS) to capture contiguous semantic information. Experimental results demonstrate that DocMamba achieves new state-of-the-art results on downstream datasets such as FUNSD, CORD, and SORIE, while significantly improving speed and reducing memory usage. Notably, experiments on the HRDoc confirm DocMamba's potential for length extrapolation. The code will be available online.
SRFUND: A Multi-Granularity Hierarchical Structure Reconstruction Benchmark in Form Understanding
Jun 13, 2024Accurately identifying and organizing textual content is crucial for the automation of document processing in the field of form understanding. Existing datasets, such as FUNSD and XFUND, support entity classification and relationship prediction tasks but are typically limited to local and entity-level annotations. This limitation overlooks the hierarchically structured representation of documents, constraining comprehensive understanding of complex forms. To address this issue, we present the SRFUND, a hierarchically structured multi-task form understanding benchmark. SRFUND provides refined annotations on top of the original FUNSD and XFUND datasets, encompassing five tasks: (1) word to text-line merging, (2) text-line to entity merging, (3) entity category classification, (4) item table localization, and (5) entity-based full-document hierarchical structure recovery. We meticulously supplemented the original dataset with missing annotations at various levels of granularity and added detailed annotations for multi-item table regions within the forms. Additionally, we introduce global hierarchical structure dependencies for entity relation prediction tasks, surpassing traditional local key-value associations. The SRFUND dataset includes eight languages including English, Chinese, Japanese, German, French, Spanish, Italian, and Portuguese, making it a powerful tool for cross-lingual form understanding. Extensive experimental results demonstrate that the SRFUND dataset presents new challenges and significant opportunities in handling diverse layouts and global hierarchical structures of forms, thus providing deep insights into the field of form understanding. The original dataset and implementations of baseline methods are available at https://sprateam-ustc.github.io/SRFUND
Quality-aware Masked Diffusion Transformer for Enhanced Music Generation
May 24, 2024



In recent years, diffusion-based text-to-music (TTM) generation has gained prominence, offering a novel approach to synthesizing musical content from textual descriptions. Achieving high accuracy and diversity in this generation process requires extensive, high-quality data, which often constitutes only a fraction of available datasets. Within open-source datasets, the prevalence of issues like mislabeling, weak labeling, unlabeled data, and low-quality music waveform significantly hampers the development of music generation models. To overcome these challenges, we introduce a novel quality-aware masked diffusion transformer (QA-MDT) approach that enables generative models to discern the quality of input music waveform during training. Building on the unique properties of musical signals, we have adapted and implemented a MDT model for TTM task, while further unveiling its distinct capacity for quality control. Moreover, we address the issue of low-quality captions with a caption refinement data processing approach. Our demo page is shown in https://qa-mdt.github.io/. Code on https://github.com/ivcylc/qa-mdt
SEMv3: A Fast and Robust Approach to Table Separation Line Detection
May 20, 2024Table structure recognition (TSR) aims to parse the inherent structure of a table from its input image. The `"split-and-merge" paradigm is a pivotal approach to parse table structure, where the table separation line detection is crucial. However, challenges such as wireless and deformed tables make it demanding. In this paper, we adhere to the "split-and-merge" paradigm and propose SEMv3 (SEM: Split, Embed and Merge), a method that is both fast and robust for detecting table separation lines. During the split stage, we introduce a Keypoint Offset Regression (KOR) module, which effectively detects table separation lines by directly regressing the offset of each line relative to its keypoint proposals. Moreover, in the merge stage, we define a series of merge actions to efficiently describe the table structure based on table grids. Extensive ablation studies demonstrate that our proposed KOR module can detect table separation lines quickly and accurately. Furthermore, on public datasets (e.g. WTW, ICDAR-2019 cTDaR Historical and iFLYTAB), SEMv3 achieves state-of-the-art (SOTA) performance. The code is available at https://github.com/Chunchunwumu/SEMv3.