 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Geometric Problem-Solving Ability of Multimodal LLMs via Symbolic-Neural Integration
Apr 17, 2025Recent advances in Multimodal Large Language Models (MLLMs) have achieved remarkable progress in general domains and demonstrated promise in multimodal mathematical reasoning. However, applying MLLMs to geometry problem solving (GPS) remains challenging due to lack of accurate step-by-step solution data and severe hallucinations during reasoning. In this paper, we propose GeoGen, a pipeline that can automatically generates step-wise reasoning paths for geometry diagrams. By leveraging the precise symbolic reasoning, \textbf{GeoGen} produces large-scale, high-quality question-answer pairs. To further enhance the logical reasoning ability of MLLMs, we train \textbf{GeoLogic}, a Large Language Model (LLM) using synthetic data generated by GeoGen. Serving as a bridge between natural language and symbolic systems, GeoLogic enables symbolic tools to help verifying MLLM outputs, making the reasoning process more rigorous and alleviating hallucinations. Experimental results show that our approach consistently improves the performance of MLLMs, achieving remarkable results on benchmarks for geometric reasoning tasks. This improvement stems from our integration of the strengths of LLMs and symbolic systems, which enables a more reliable and interpretable approach for the GPS task. Codes are available at https://github.com/ycpNotFound/GeoGen.
Navigation-GPT: A Robust and Adaptive Framework Utilizing Large Language Models for Navigation Applications
Feb 23, 2025Existing navigation decision support systems often perform poorly when handling non-predefined navigation scenarios. Leveraging the generalization capabilities of large language model (LLM) in handling unknown scenarios, this research proposes a dual-core framework for LLM applications to address this issue. Firstly, through ReAct-based prompt engineering, a larger LLM core decomposes intricate navigation tasks into manageable sub-tasks, which autonomously invoke corresponding external tools to gather relevant information, using this feedback to mitigate the risk of LLM hallucinations. Subsequently, a fine-tuned and compact LLM core, acting like a first-mate is designed to process such information and unstructured external data, then to generates context-aware recommendations, ultimately delivering lookout insights and navigation hints that adhere to the International Regulations for Preventing Collisions at Sea (COLREGs) and other rules. Extensive experiments demonstrate the proposed framework not only excels in traditional ship collision avoidance tasks but also adapts effectively to unstructured, non-predefined, and unpredictable scenarios. A comparative analysis with DeepSeek-R1, GPT-4o and other SOTA models highlights the efficacy and rationality of the proposed framework. This research bridges the gap between conventional navigation systems and LLMs, offering a framework to enhance safety and operational efficiency across diverse navigation applications.
The USTC-NERCSLIP Systems for the CHiME-8 NOTSOFAR-1 Challenge
Sep 03, 2024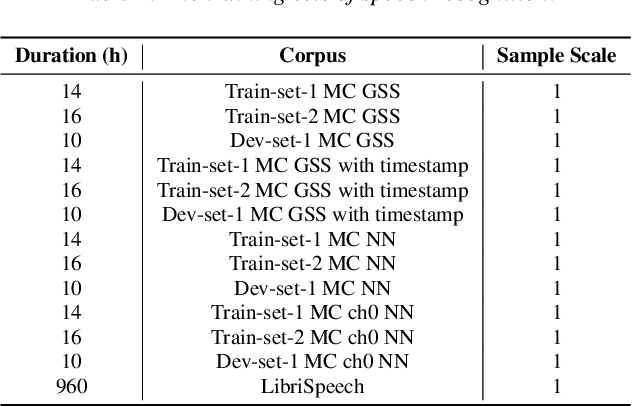
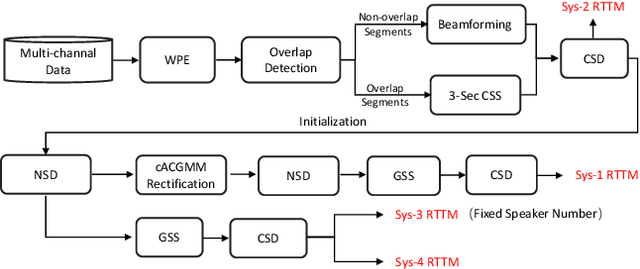
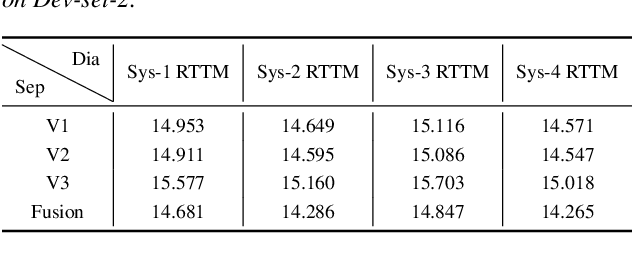
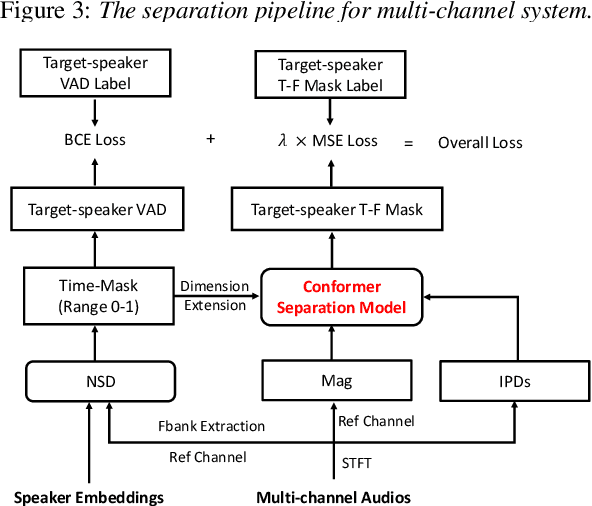
This technical report outlines our submission system for the CHiME-8 NOTSOFAR-1 Challenge. The primary difficulty of this challenge is the dataset recorded across various conference rooms, which captures real-world complexities such as high overlap rates, background noises, a variable number of speakers, and natural conversation styles. To address these issues, we optimized the system in several aspects: For front-end speech signal processing, we introduced a data-driven joint training method for diarization and separation (JDS) to enhance audio quality. Additionally, we also integrated traditional guided source separation (GSS) for multi-channel track to provide complementary information for the JDS. For back-end speech recognition, we enhanced Whisper with WavLM, ConvNeXt, and Transformer innovations, applying multi-task training and Noise KLD augmentation, to significantly advance ASR robustness and accuracy. Our system attained a Time-Constrained minimum Permutation Word Error Rate (tcpWER) of 14.265% and 22.989% on the CHiME-8 NOTSOFAR-1 Dev-set-2 multi-channel and single-channel tracks, respectively.
A Four-Stage Data Augmentation Approach to ResNet-Conformer Based Acoustic Modeling for Sound Event Localization and Detection
Jan 08, 2021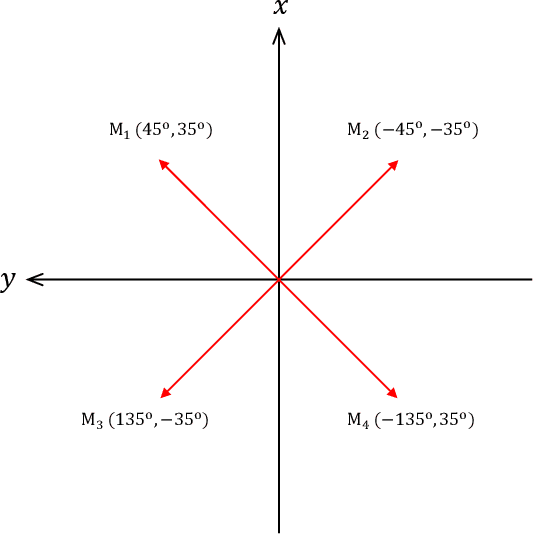
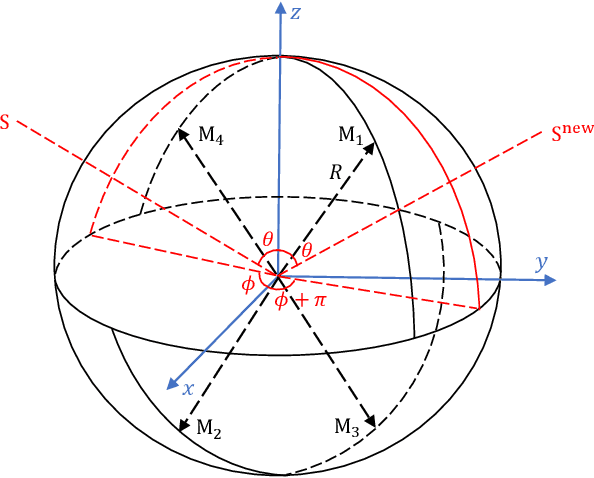
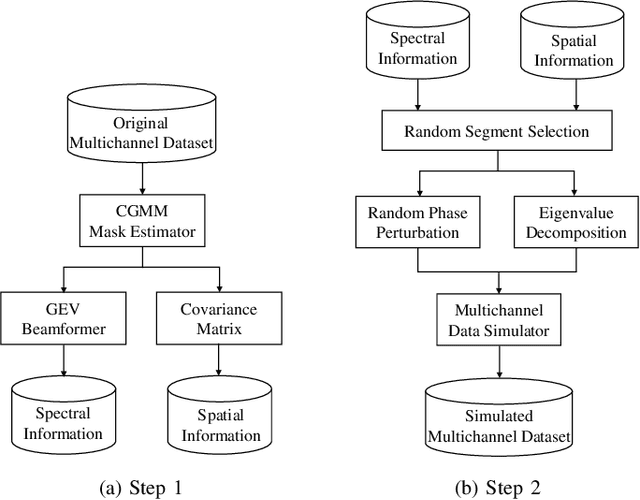

In this paper, we propose a novel four-stage data augmentation approach to ResNet-Conformer based acoustic modeling for sound event localization and detection (SELD). First, we explore two spatial augmentation techniques, namely audio channel swapping (ACS) and multi-channel simulation (MCS), to deal with data sparsity in SELD. ACS and MDS focus on augmenting the limited training data with expanding direction of arrival (DOA) representations such that the acoustic models trained with the augmented data are robust to localization variations of acoustic sources. Next, time-domain mixing (TDM) and time-frequency masking (TFM) are also investigated to deal with overlapping sound events and data diversity. Finally, ACS, MCS, TDM and TFM are combined in a step-by-step manner to form an effective four-stage data augmentation scheme. Tested on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2020 data sets, our proposed augmentation approach greatly improves the system performance, ranking our submitted system in the first place in the SELD task of DCASE 2020 Challenge. Furthermore, we employ a ResNet-Conformer architecture to model both global and local context dependencies of an audio sequence to yield further gains over those architectures used in the DCASE 2020 SELD evaluations.