 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Spatial Cues in Modular Speaker Diarization for Multi-channel Multi-party Meetings
Sep 25, 2024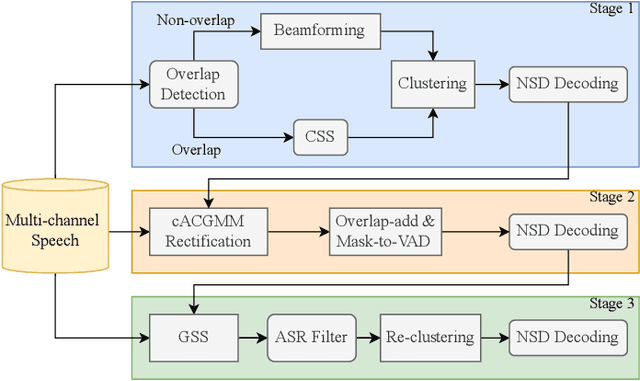
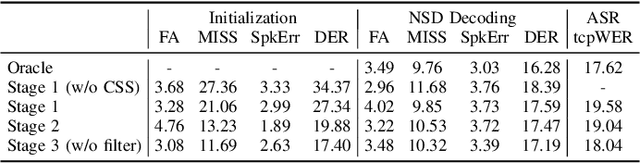


Although fully end-to-end speaker diarization systems have made significant progress in recent years, modular systems often achieve superior results in real-world scenarios due to their greater adaptability and robustness. Historically, modular speaker diarization methods have seldom discussed how to leverage spatial cues from multi-channel speech. This paper proposes a three-stage modular system to enhance single-channel neural speaker diarization systems and recognition performance by utilizing spatial cues from multi-channel speech to provide more accurate initialization for each stage of neural speaker diarization (NSD) decoding: (1) Overlap detection and continuous speech separation (CSS) on multi-channel speech are used to obtain cleaner single speaker speech segments for clustering, followed by the first NSD decoding pass. (2) The results from the first pass initialize a complex Angular Central Gaussian Mixture Model (cACGMM) to estimate speaker-wise masks on multi-channel speech, and through Overlap-add and Mask-to-VAD, achieve initialization with lower speaker error (SpkErr), followed by the second NSD decoding pass. (3) The second decoding results are used for guided source separation (GSS), recognizing and filtering short segments containing less one word to obtain cleaner speech segments, followed by re-clustering and the final NSD decoding pass. We presented the progressively explored evaluation results from the CHiME-8 NOTSOFAR-1 (Natural Office Talkers in Settings Of Far-field Audio Recordings) challenge, demonstrating the effectiveness of our system and its contribution to improving recognition performance. Our final system achieved the first place in the challenge.
The USTC-NERCSLIP Systems for the CHiME-8 NOTSOFAR-1 Challenge
Sep 03, 2024
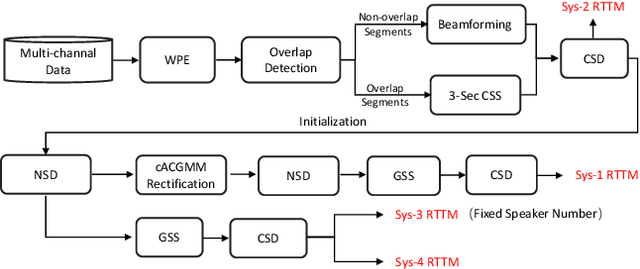
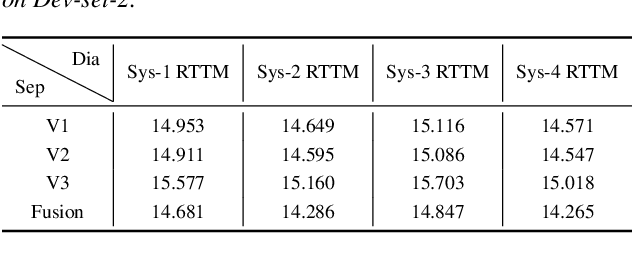
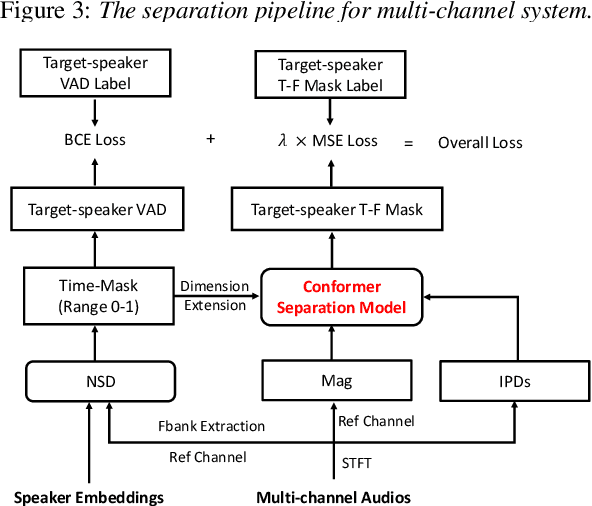
This technical report outlines our submission system for the CHiME-8 NOTSOFAR-1 Challenge. The primary difficulty of this challenge is the dataset recorded across various conference rooms, which captures real-world complexities such as high overlap rates, background noises, a variable number of speakers, and natural conversation styles. To address these issues, we optimized the system in several aspects: For front-end speech signal processing, we introduced a data-driven joint training method for diarization and separation (JDS) to enhance audio quality. Additionally, we also integrated traditional guided source separation (GSS) for multi-channel track to provide complementary information for the JDS. For back-end speech recognition, we enhanced Whisper with WavLM, ConvNeXt, and Transformer innovations, applying multi-task training and Noise KLD augmentation, to significantly advance ASR robustness and accuracy. Our system attained a Time-Constrained minimum Permutation Word Error Rate (tcpWER) of 14.265% and 22.989% on the CHiME-8 NOTSOFAR-1 Dev-set-2 multi-channel and single-channel tracks, respectively.
Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding with Sequence-to-Sequence Architecture
Sep 17, 2023



We propose a novel neural speaker diarization system using memory-aware multi-speaker embedding with sequence-to-sequence architecture (NSD-MS2S), which integrates the strengths of memory-aware multi-speaker embedding (MA-MSE) and sequence-to-sequence (Seq2Seq) architecture, leading to improvement in both efficiency and performance. Next, we further decrease the memory occupation of decoding by incorporating input features fusion and then employ a multi-head attention mechanism to capture features at different levels. NSD-MS2S achieved a macro diarization error rate (DER) of 15.9% on the CHiME-7 EVAL set, which signifies a relative improvement of 49% over the official baseline system, and is the key technique for us to achieve the best performance for the main track of CHiME-7 DASR Challenge. Additionally, we introduce a deep interactive module (DIM) in MA-MSE module to better retrieve a cleaner and more discriminative multi-speaker embedding, enabling the current model to outperform the system we used in the CHiME-7 DASR Challenge. Our code will be available at https://github.com/liyunlongaaa/NSD-MS2S.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023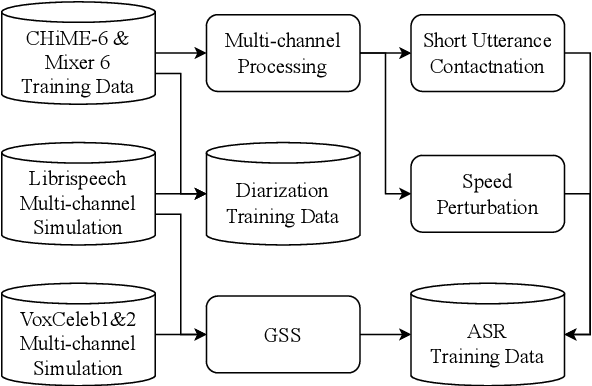
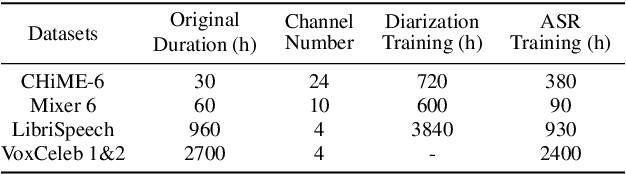
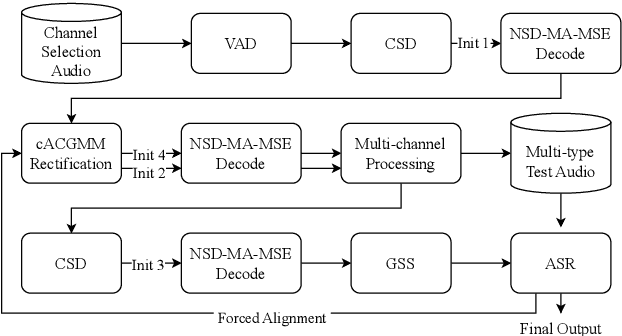
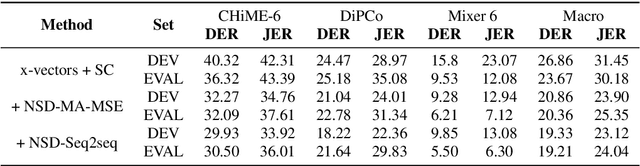
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.