 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Better at Working With You: Compiling User Corrections into Runtime Enforcement for Coding Agents
Jun 11, 2026Interactive LLM agents are becoming part of daily work, but they do not reliably become easier to work with over time: a correction remembered in one session may still be violated in the next. We study this gap between preference access and preference compliance. In tasks derived from anonymized real-user friction cases, Mem0 memory still leaves 57.5% of applicable preference checks violated. We introduce Test-time Rule Acquisition and Compiled Enforcement (TRACE), a drop-in skill-layer pipeline for coding-agent runtimes that mines user corrections, rewrites them as atomic rules, and compiles them into runtime checks that must pass before an agent completes future tasks. Unlike runtime checks written ahead of time by developers, TRACE skills come from the user's own chat corrections. We evaluate TRACE with simulated user-in-the-loop experiments on ClawArena coding-agent tasks and MemoryArena-derived memory-intensive tasks. On ClawArena, TRACE reduces held-out preference violation from 100.0% to 37.6% on in-distribution tasks and from 100.0% to 2.0% on out-of-distribution tasks. On MemoryArena-derived tasks, TRACE reduces in-distribution violation from 100.0% to 60.5% while matching or exceeding the strongest memory baseline on task pass. These results suggest that compiling corrections into runtime enforcement can address a repeated-friction failure mode that memory alone does not reliably solve, reducing the need for users to restate the same correction across future sessions. Experiment code is available at https://github.com/YujunZhou/TRACE_exp, and the deployable skill is available at https://github.com/YujunZhou/tellonce.
CHORUS: Decentralized Multi-Embodiment Collaboration with One VLA Policy
Jun 10, 2026Multi-robot collaboration allows robots to efficiently take on a wide range of tasks, from moving a couch through a doorway to assembling structures on a construction site. However, achieving such coordination in mobile multi-robot settings remains challenging: centralized methods conditioned on the combined observations of a team scale poorly with team size, and decentralized methods that train one policy per robot often require explicit alignment procedures or information sharing at inference time to overcome partial observability. Our key insight is that the visuomotor priors of pretrained vision-language-action (VLA) models should enable reactive, decentralized collaboration from each robot's local observations alone, without these inference-time assumptions. We propose CHORUS, a framework that adapts a single VLA backbone to control diverse, multi-robot teams. At inference time, each robot runs an independent copy of CHORUS, conditioned only on its own observations and a robot-identifying prompt. In real-world experiments including mobile tape measurement, library book handovers, and laundry basket lifting, CHORUS achieves a 64% point improvement over decentralized, from-scratch models, improves reactivity to teammate behavior by 40% points, and outperforms centralized baselines. Together, these results show that a shared VLA backbone is capable of achieving decentralized multi-robot collaboration, without per-robot policies or inter-robot communication at inference.
EXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models
May 25, 2026The ability to efficiently and reliably learn new tasks has been a foundational challenge in robotics. Vision-Language-Action (VLA) models have demonstrated strong generalization across diverse manipulation tasks, yet pretrained policies consistently fall short of the reliability required for real-world deployment. Reinforcement learning (RL) fine-tuning offers a promising path to bridge this gap, but existing approaches either train from scratch without fully leveraging pretrained priors, or fine-tune VLAs without achieving the sample efficiency and success rates that practical deployment demands. We present EXPO-FT, a system for stable, sample-efficient RL finetuning of pretrained VLA policies that closes this gap. Our system solves a suite of challenging manipulation tasks, including routing string lights and inserting the plug to light it up, striking a pool ball into a pocket, and inserting a flower into a wine bottle, each requiring combinations of high precision, dynamic actions, and robustness to varied initial states. Our system achieves perfect task performance (30/30 successes) across all evaluated tasks within an average of 19.1 minutes of online robot data, outperforming both prior RL-from-scratch and VLA finetuning approaches. We release an open-source codebase with the aim of facilitating broader adoption of RL finetuning of VLA models in robotics.
AnomaMind: Agentic Time Series Anomaly Detection with Tool-Augmented Reasoning
Feb 14, 2026Time series anomaly detection is critical in many real-world applications, where effective solutions must localize anomalous regions and support reliable decision-making under complex settings. However, most existing methods frame anomaly detection as a purely discriminative prediction task with fixed feature inputs, rather than an evidence-driven diagnostic process. As a result, they often struggle when anomalies exhibit strong context dependence or diverse patterns. We argue that these limitations stem from the lack of adaptive feature preparation, reasoning-aware detection, and iterative refinement during inference. To address these challenges, we propose AnomaMind, an agentic time series anomaly detection framework that reformulates anomaly detection as a sequential decision-making process. AnomaMind operates through a structured workflow that progressively localizes anomalous intervals in a coarse-to-fine manner, augments detection through multi-turn tool interactions for adaptive feature preparation, and refines anomaly decisions via self-reflection. The workflow is supported by a set of reusable tool engines, enabling context-aware diagnostic analysis. A key design of AnomaMind is an explicitly designed hybrid inference mechanism for tool-augmented anomaly detection. In this mechanism, general-purpose models are responsible for autonomous tool interaction and self-reflective refinement, while core anomaly detection decisions are learned through reinforcement learning under verifiable workflow-level feedback, enabling task-specific optimization within a flexible reasoning framework. Extensive experiments across diverse settings demonstrate that AnomaMind consistently improves anomaly detection performance. The code is available at https://anonymous.4open.science/r/AnomaMind.
Cast-R1: Learning Tool-Augmented Sequential Decision Policies for Time Series Forecasting
Feb 14, 2026Time series forecasting has long been dominated by model-centric approaches that formulate prediction as a single-pass mapping from historical observations to future values. Despite recent progress, such formulations often struggle in complex and evolving settings, largely because most forecasting models lack the ability to autonomously acquire informative evidence, reason about potential future changes, or revise predictions through iterative decision processes. In this work, we propose Cast-R1, a learned time series forecasting framework that reformulates forecasting as a sequential decision-making problem. Cast-R1 introduces a memory-based state management mechanism that maintains decision-relevant information across interaction steps, enabling the accumulation of contextual evidence to support long-horizon reasoning. Building on this formulation, forecasting is carried out through a tool-augmented agentic workflow, in which the agent autonomously interacts with a modular toolkit to extract statistical features, invoke lightweight forecasting models for decision support, perform reasoning-based prediction, and iteratively refine forecasts through self-reflection. To train Cast-R1, we adopt a two-stage learning strategy that combines supervised fine-tuning with multi-turn reinforcement learning, together with a curriculum learning scheme that progressively increases task difficulty to improve policy learning. Extensive experiments on multiple real-world time series datasets demonstrate the effectiveness of Cast-R1. We hope this work provides a practical step towards further exploration of agentic paradigms for time series modeling. Our code is available at https://github.com/Xiaoyu-Tao/Cast-R1-TS.
Capability-Oriented Training Induced Alignment Risk
Feb 12, 2026While most AI alignment research focuses on preventing models from generating explicitly harmful content, a more subtle risk is emerging: capability-oriented training induced exploitation. We investigate whether language models, when trained with reinforcement learning (RL) in environments with implicit loopholes, will spontaneously learn to exploit these flaws to maximize their reward, even without any malicious intent in their training. To test this, we design a suite of four diverse "vulnerability games", each presenting a unique, exploitable flaw related to context-conditional compliance, proxy metrics, reward tampering, and self-evaluation. Our experiments show that models consistently learn to exploit these vulnerabilities, discovering opportunistic strategies that significantly increase their reward at the expense of task correctness or safety. More critically, we find that these exploitative strategies are not narrow "tricks" but generalizable skills; they can be transferred to new tasks and even "distilled" from a capable teacher model to other student models through data alone. Our findings reveal that capability-oriented training induced risks pose a fundamental challenge to current alignment approaches, suggesting that future AI safety work must extend beyond content moderation to rigorously auditing and securing the training environments and reward mechanisms themselves. Code is available at https://github.com/YujunZhou/Capability_Oriented_Alignment_Risk.
SteerVLA: Steering Vision-Language-Action Models in Long-Tail Driving Scenarios
Feb 09, 2026A fundamental challenge in autonomous driving is the integration of high-level, semantic reasoning for long-tail events with low-level, reactive control for robust driving. While large vision-language models (VLMs) trained on web-scale data offer powerful common-sense reasoning, they lack the grounded experience necessary for safe vehicle control. We posit that an effective autonomous agent should leverage the world knowledge of VLMs to guide a steerable driving policy toward robust control in driving scenarios. To this end, we propose SteerVLA, which leverages the reasoning capabilities of VLMs to produce fine-grained language instructions that steer a vision-language-action (VLA) driving policy. Key to our method is this rich language interface between the high-level VLM and low-level VLA, which allows the high-level policy to more effectively ground its reasoning in the control outputs of the low-level policy. To provide fine-grained language supervision aligned with vehicle control, we leverage a VLM to augment existing driving data with detailed language annotations, which we find to be essential for effective reasoning and steerability. We evaluate SteerVLA on a challenging closed-loop benchmark, where it outperforms state-of-the-art methods by 4.77 points in overall driving score and by 8.04 points on a long-tail subset. The project website is available at: https://steervla.github.io/.
Resting Neurons, Active Insights: Improving Input Sparsification for Large Language Models
Dec 14, 2025Large Language Models (LLMs) achieve state-of-the-art performance across a wide range of applications, but their massive scale poses significant challenges for both efficiency and interpretability. Structural pruning, which reduces model size by removing redundant computational units such as neurons, has been widely explored as a solution, and this study devotes to input sparsification, an increasingly popular technique that improves efficiency by selectively activating only a subset of entry values for each input. However, existing approaches focus primarily on computational savings, often overlooking the representational consequences of sparsification and leaving a noticeable performance gap compared to full models. In this work, we first reinterpret input sparsification as a form of dynamic structural pruning. Motivated by the spontaneous baseline firing rates observed in biological neurons, we introduce a small set of trainable spontaneous neurons that act as compensatory units to stabilize activations in sparsified LLMs. Experiments demonstrate that these auxiliary neurons substantially reduce the sparsification-induced performance gap while generalizing effectively across tasks.
AlphaCast: A Human Wisdom-LLM Intelligence Co-Reasoning Framework for Interactive Time Series Forecasting
Nov 12, 2025Time series forecasting plays a critical role in high-stakes domains such as energy, healthcare, and climate. Although recent advances have improved accuracy, most approaches still treat forecasting as a static one-time mapping task, lacking the interaction, reasoning, and adaptability of human experts. This gap limits their usefulness in complex real-world environments. To address this, we propose AlphaCast, a human wisdom-large language model (LLM) intelligence co-reasoning framework that redefines forecasting as an interactive process. The key idea is to enable step-by-step collaboration between human wisdom and LLM intelligence to jointly prepare, generate, and verify forecasts. The framework consists of two stages: (1) automated prediction preparation, where AlphaCast builds a multi-source cognitive foundation comprising a feature set that captures key statistics and time patterns, a domain knowledge base distilled from corpora and historical series, a contextual repository that stores rich information for each time window, and a case base that retrieves optimal strategies via pattern clustering and matching; and (2) generative reasoning and reflective optimization, where AlphaCast integrates statistical temporal features, prior knowledge, contextual information, and forecasting strategies, triggering a meta-reasoning loop for continuous self-correction and strategy refinement. Extensive experiments on short- and long-term datasets show that AlphaCast consistently outperforms state-of-the-art baselines in predictive accuracy. Code is available at this repository: https://github.com/SkyeGT/AlphaCast_Official .
High-Fidelity Differential-information Driven Binary Vision Transformer
Jul 03, 2025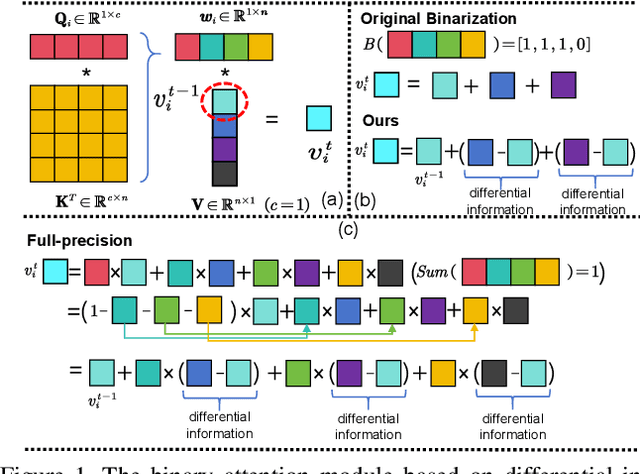
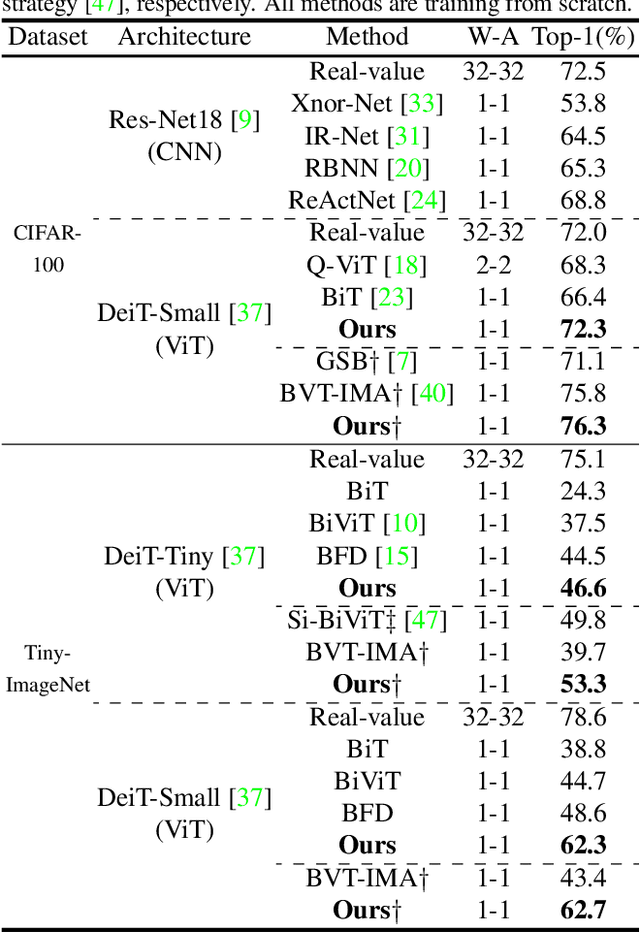
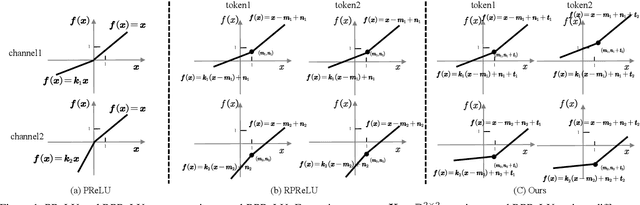

The binarization of vision transformers (ViTs) offers a promising approach to addressing the trade-off between high computational/storage demands and the constraints of edge-device deployment. However, existing binary ViT methods often suffer from severe performance degradation or rely heavily on full-precision modules. To address these issues, we propose DIDB-ViT, a novel binary ViT that is highly informative while maintaining the original ViT architecture and computational efficiency. Specifically, we design an informative attention module incorporating differential information to mitigate information loss caused by binarization and enhance high-frequency retention. To preserve the fidelity of the similarity calculations between binary Q and K tensors, we apply frequency decomposition using the discrete Haar wavelet and integrate similarities across different frequencies. Additionally, we introduce an improved RPReLU activation function to restructure the activation distribution, expanding the model's representational capacity. Experimental results demonstrate that our DIDB-ViT significantly outperforms state-of-the-art network quantization methods in multiple ViT architectures, achieving superior image classification and segmentation performance.