 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Differential-information Driven Binary Vision Transformer
Jul 03, 2025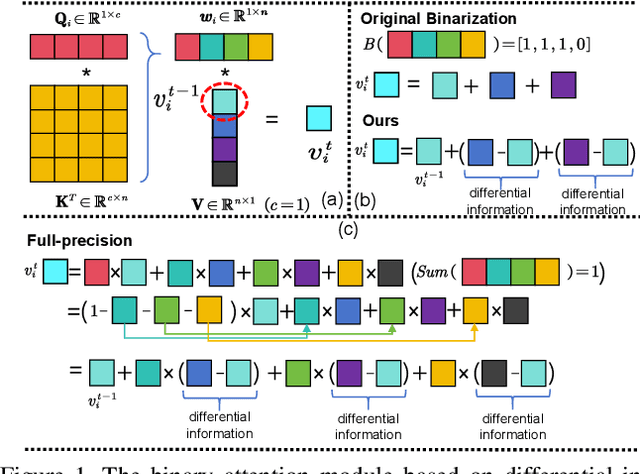
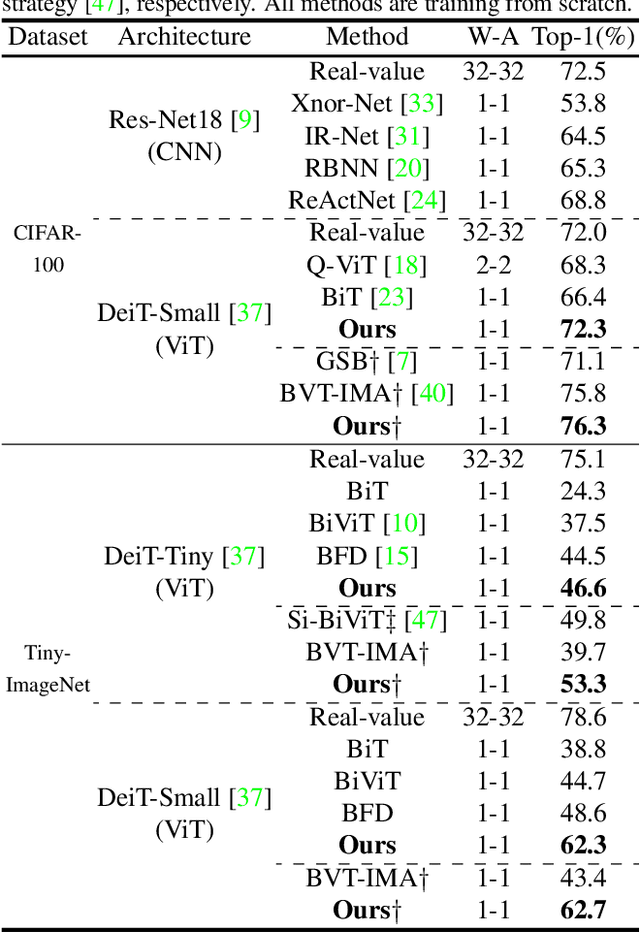
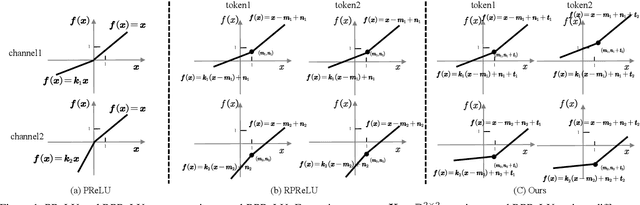

The binarization of vision transformers (ViTs) offers a promising approach to addressing the trade-off between high computational/storage demands and the constraints of edge-device deployment. However, existing binary ViT methods often suffer from severe performance degradation or rely heavily on full-precision modules. To address these issues, we propose DIDB-ViT, a novel binary ViT that is highly informative while maintaining the original ViT architecture and computational efficiency. Specifically, we design an informative attention module incorporating differential information to mitigate information loss caused by binarization and enhance high-frequency retention. To preserve the fidelity of the similarity calculations between binary Q and K tensors, we apply frequency decomposition using the discrete Haar wavelet and integrate similarities across different frequencies. Additionally, we introduce an improved RPReLU activation function to restructure the activation distribution, expanding the model's representational capacity. Experimental results demonstrate that our DIDB-ViT significantly outperforms state-of-the-art network quantization methods in multiple ViT architectures, achieving superior image classification and segmentation performance.
BHViT: Binarized Hybrid Vision Transformer
Mar 05, 2025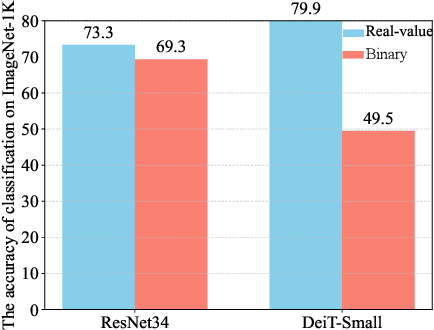
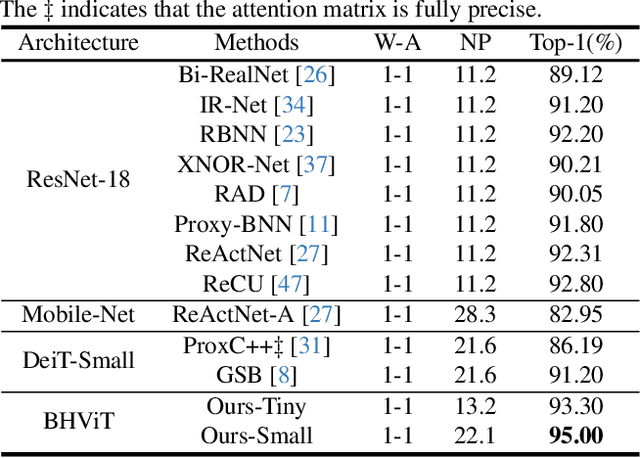
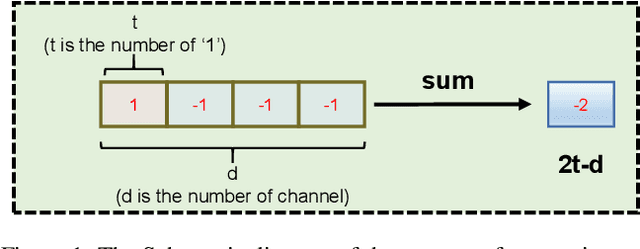

Model binarization has made significant progress in enabling real-time and energy-efficient computation for convolutional neural networks (CNN), offering a potential solution to the deployment challenges faced by Vision Transformers (ViTs) on edge devices. However, due to the structural differences between CNN and Transformer architectures, simply applying binary CNN strategies to the ViT models will lead to a significant performance drop. To tackle this challenge, we propose BHViT, a binarization-friendly hybrid ViT architecture and its full binarization model with the guidance of three important observations. Initially, BHViT utilizes the local information interaction and hierarchical feature aggregation technique from coarse to fine levels to address redundant computations stemming from excessive tokens. Then, a novel module based on shift operations is proposed to enhance the performance of the binary Multilayer Perceptron (MLP) module without significantly increasing computational overhead. In addition, an innovative attention matrix binarization method based on quantization decomposition is proposed to evaluate the token's importance in the binarized attention matrix. Finally, we propose a regularization loss to address the inadequate optimization caused by the incompatibility between the weight oscillation in the binary layers and the Adam Optimizer. Extensive experimental results demonstrate that our proposed algorithm achieves SOTA performance among binary ViT methods.
Pathfinder for Low-altitude Aircraft with Binary Neural Network
Sep 13, 2024



A prior global topological map (e.g., the OpenStreetMap, OSM) can boost the performance of autonomous mapping by a ground mobile robot. However, the prior map is usually incomplete due to lacking labeling in partial paths. To solve this problem, this paper proposes an OSM maker using airborne sensors carried by low-altitude aircraft, where the core of the OSM maker is a novel efficient pathfinder approach based on LiDAR and camera data, i.e., a binary dual-stream road segmentation model. Specifically, a multi-scale feature extraction based on the UNet architecture is implemented for images and point clouds. To reduce the effect caused by the sparsity of point cloud, an attention-guided gated block is designed to integrate image and point-cloud features. For enhancing the efficiency of the model, we propose a binarization streamline to each model component, including a variant of vision transformer (ViT) architecture as the encoder of the image branch, and new focal and perception losses to optimize the model training. The experimental results on two datasets demonstrate that our pathfinder method achieves SOTA accuracy with high efficiency in finding paths from the low-level airborne sensors, and we can create complete OSM prior maps based on the segmented road skeletons. Code and data are available at:https://github.com/IMRL/Pathfinder}{https://github.com/IMRL/Pathfinder.