 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentics 2.0: Logical Transduction Algebra for Agentic Data Workflows
Mar 04, 2026Agentic AI is rapidly transitioning from research prototypes to enterprise deployments, where requirements extend to meet the software quality attributes of reliability, scalability, and observability beyond plausible text generation. We present Agentics 2.0, a lightweight, Python-native framework for building high-quality, structured, explainable, and type-safe agentic data workflows. At the core of Agentics 2.0, the logical transduction algebra formalizes a large language model inference call as a typed semantic transformation, which we call a transducible function that enforces schema validity and the locality of evidence. The transducible functions compose into larger programs via algebraically grounded operators and execute as stateless asynchronous calls in parallel in asynchronous Map-Reduce programs. The proposed framework provides semantic reliability through strong typing, semantic observability through evidence tracing between slots of the input and output types, and scalability through stateless parallel execution. We instantiate reusable design patterns and evaluate the programs in Agentics 2.0 on challenging benchmarks, including DiscoveryBench for data-driven discovery and Archer for NL-to-SQL semantic parsing, demonstrating state-of-the-art performance.
Q-function Decomposition with Intervention Semantics with Factored Action Spaces
Apr 30, 2025Many practical reinforcement learning environments have a discrete factored action space that induces a large combinatorial set of actions, thereby posing significant challenges. Existing approaches leverage the regular structure of the action space and resort to a linear decomposition of Q-functions, which avoids enumerating all combinations of factored actions. In this paper, we consider Q-functions defined over a lower dimensional projected subspace of the original action space, and study the condition for the unbiasedness of decomposed Q-functions using causal effect estimation from the no unobserved confounder setting in causal statistics. This leads to a general scheme which we call action decomposed reinforcement learning that uses the projected Q-functions to approximate the Q-function in standard model-free reinforcement learning algorithms. The proposed approach is shown to improve sample complexity in a model-based reinforcement learning setting. We demonstrate improvements in sample efficiency compared to state-of-the-art baselines in online continuous control environments and a real-world offline sepsis treatment environment.
FactReasoner: A Probabilistic Approach to Long-Form Factuality Assessment for Large Language Models
Feb 25, 2025


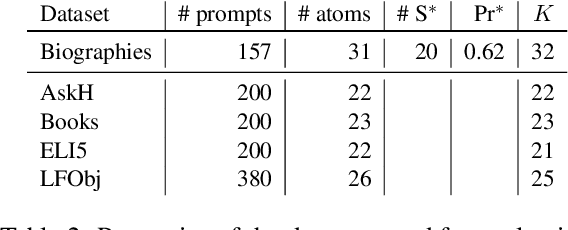
Large language models (LLMs) have demonstrated vast capabilities on generative tasks in recent years, yet they struggle with guaranteeing the factual correctness of the generated content. This makes these models unreliable in realistic situations where factually accurate responses are expected. In this paper, we propose FactReasoner, a new factuality assessor that relies on probabilistic reasoning to assess the factuality of a long-form generated response. Specifically, FactReasoner decomposes the response into atomic units, retrieves relevant contexts for them from an external knowledge source, and constructs a joint probability distribution over the atoms and contexts using probabilistic encodings of the logical relationships (entailment, contradiction) between the textual utterances corresponding to the atoms and contexts. FactReasoner then computes the posterior probability of whether atomic units in the response are supported by the retrieved contexts. Our experiments on labeled and unlabeled benchmark datasets demonstrate clearly that FactReasoner improves considerably over state-of-the-art prompt-based approaches in terms of both factual precision and recall.
Rationalization Models for Text-to-SQL
Feb 10, 2025We introduce a framework for generating Chain-of-Thought (CoT) rationales to enhance text-to-SQL model fine-tuning. These rationales consist of intermediate SQL statements and explanations, serving as incremental steps toward constructing the final SQL query. The process begins with manually annotating a small set of examples, which are then used to prompt a large language model in an iterative, dynamic few-shot knowledge distillation procedure from a teacher model. A rationalization model is subsequently trained on the validated decomposed queries, enabling extensive synthetic CoT annotations for text-to-SQL datasets. To evaluate the approach, we fine-tune small language models with and without these rationales on the BIRD dataset. Results indicate that step-by-step query generation improves execution accuracy, especially for moderately and highly complex queries, while also enhancing explainability.
Some Orders Are Important: Partially Preserving Orders in Top-Quality Planning
Apr 01, 2024


The ability to generate multiple plans is central to using planning in real-life applications. Top-quality planners generate sets of such top-cost plans, allowing flexibility in determining equivalent ones. In terms of the order between actions in a plan, the literature only considers two extremes -- either all orders are important, making each plan unique, or all orders are unimportant, treating two plans differing only in the order of actions as equivalent. To allow flexibility in selecting important orders, we propose specifying a subset of actions the orders between which are important, interpolating between the top-quality and unordered top-quality planning problems. We explore the ways of adapting partial order reduction search pruning techniques to address this new computational problem and present experimental evaluations demonstrating the benefits of exploiting such techniques in this setting.
Unifying and Certifying Top-Quality Planning
Mar 05, 2024
The growing utilization of planning tools in practical scenarios has sparked an interest in generating multiple high-quality plans. Consequently, a range of computational problems under the general umbrella of top-quality planning were introduced over a short time period, each with its own definition. In this work, we show that the existing definitions can be unified into one, based on a dominance relation. The different computational problems, therefore, simply correspond to different dominance relations. Given the unified definition, we can now certify the top-quality of the solutions, leveraging existing certification of unsolvability and optimality. We show that task transformations found in the existing literature can be employed for the efficient certification of various top-quality planning problems and propose a novel transformation to efficiently certify loopless top-quality planning.
Foundation Model Sherpas: Guiding Foundation Models through Knowledge and Reasoning
Feb 02, 2024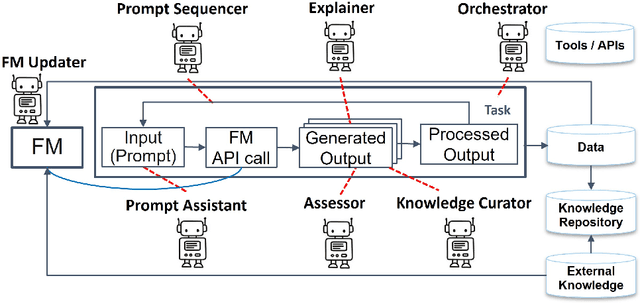


Foundation models (FMs) such as large language models have revolutionized the field of AI by showing remarkable performance in various tasks. However, they exhibit numerous limitations that prevent their broader adoption in many real-world systems, which often require a higher bar for trustworthiness and usability. Since FMs are trained using loss functions aimed at reconstructing the training corpus in a self-supervised manner, there is no guarantee that the model's output aligns with users' preferences for a specific task at hand. In this survey paper, we propose a conceptual framework that encapsulates different modes by which agents could interact with FMs and guide them suitably for a set of tasks, particularly through knowledge augmentation and reasoning. Our framework elucidates agent role categories such as updating the underlying FM, assisting with prompting the FM, and evaluating the FM output. We also categorize several state-of-the-art approaches into agent interaction protocols, highlighting the nature and extent of involvement of the various agent roles. The proposed framework provides guidance for future directions to further realize the power of FMs in practical AI systems.
AI Planning Annotation for Sample Efficient Reinforcement Learning
Mar 01, 2022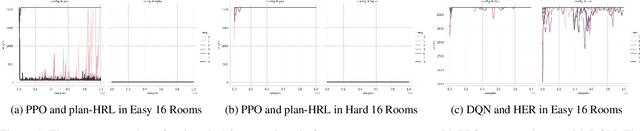

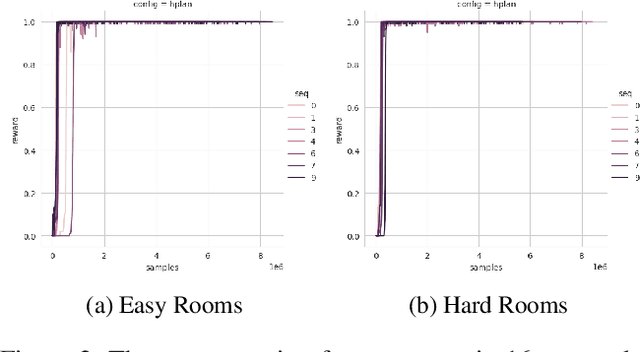
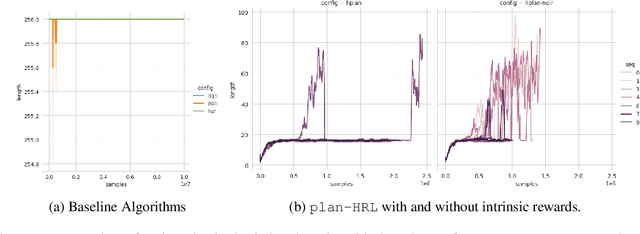
AI planning and Reinforcement Learning (RL) both solve sequential decision-making problems under the different formulations. AI Planning requires operator models, but then allows efficient plan generation. RL requires no operator model, instead learns a policy to guide an agent to high reward states. Planning can be brittle in the face of noise whereas RL is more tolerant. However, RL requires a large number of training examples to learn the policy. In this work, we aim to bring AI planning and RL closer by showing that a suitably defined planning model can be used to improve the efficiency of RL. Specifically, we show that the options in the hierarchical RL can be derived from a planning task and integrate planning and RL algorithms for training option policy functions. Our experiments demonstrate an improved sample efficiency on a variety of RL environments over the previous state-of-the-art.