 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effectiveness of Approximate Regularized Replay for Efficient Supervised Fine-Tuning of Large Language Models
Dec 26, 2025Although parameter-efficient fine-tuning methods, such as LoRA, only modify a small subset of parameters, they can have a significant impact on the model. Our instruction-tuning experiments show that LoRA-based supervised fine-tuning can catastrophically degrade model capabilities, even when trained on very small datasets for relatively few steps. With that said, we demonstrate that while the most straightforward approach (that is likely the most used in practice) fails spectacularly, small tweaks to the training procedure with very little overhead can virtually eliminate the problem. Particularly, in this paper we consider a regularized approximate replay approach which penalizes KL divergence with respect to the initial model and interleaves in data for next token prediction from a different, yet similar, open access corpus to what was used in pre-training. When applied to Qwen instruction-tuned models, we find that this recipe preserves general knowledge in the model without hindering plasticity to new tasks by adding a modest amount of computational overhead.
Language Models Coupled with Metacognition Can Outperform Reasoning Models
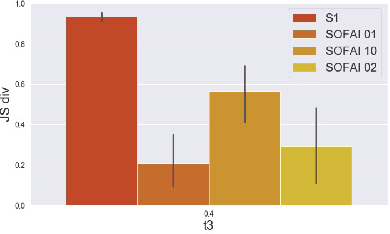
Aug 25, 2025Large language models (LLMs) excel in speed and adaptability across various reasoning tasks, but they often struggle when strict logic or constraint enforcement is required. In contrast, Large Reasoning Models (LRMs) are specifically designed for complex, step-by-step reasoning, although they come with significant computational costs and slower inference times. To address these trade-offs, we employ and generalize the SOFAI (Slow and Fast AI) cognitive architecture into SOFAI-LM, which coordinates a fast LLM with a slower but more powerful LRM through metacognition. The metacognitive module actively monitors the LLM's performance and provides targeted, iterative feedback with relevant examples. This enables the LLM to progressively refine its solutions without requiring the need for additional model fine-tuning. Extensive experiments on graph coloring and code debugging problems demonstrate that our feedback-driven approach significantly enhances the problem-solving capabilities of the LLM. In many instances, it achieves performance levels that match or even exceed those of standalone LRMs while requiring considerably less time. Additionally, when the LLM and feedback mechanism alone are insufficient, we engage the LRM by providing appropriate information collected during the LLM's feedback loop, tailored to the specific characteristics of the problem domain and leads to improved overall performance. Evaluations on two contrasting domains: graph coloring, requiring globally consistent solutions, and code debugging, demanding localized fixes, demonstrate that SOFAI-LM enables LLMs to match or outperform standalone LRMs in accuracy while maintaining significantly lower inference time.
Can Large Language Models Adapt to Other Agents In-Context?
Dec 27, 2024As the research community aims to build better AI assistants that are more dynamic and personalized to the diversity of humans that they interact with, there is increased interest in evaluating the theory of mind capabilities of large language models (LLMs). Indeed, several recent studies suggest that LLM theory of mind capabilities are quite impressive, approximating human-level performance. Our paper aims to rebuke this narrative and argues instead that past studies were not directly measuring agent performance, potentially leading to findings that are illusory in nature as a result. We draw a strong distinction between what we call literal theory of mind i.e. measuring the agent's ability to predict the behavior of others and functional theory of mind i.e. adapting to agents in-context based on a rational response to predictions of their behavior. We find that top performing open source LLMs may display strong capabilities in literal theory of mind, depending on how they are prompted, but seem to struggle with functional theory of mind -- even when partner policies are exceedingly simple. Our work serves to highlight the double sided nature of inductive bias in LLMs when adapting to new situations. While this bias can lead to strong performance over limited horizons, it often hinders convergence to optimal long-term behavior.
Quantifying artificial intelligence through algebraic generalization
Nov 08, 2024The rapid development of modern artificial intelligence (AI) systems has created an urgent need for their scientific quantification. While their fluency across a variety of domains is impressive, modern AI systems fall short on tests requiring symbolic processing and abstraction - a glaring limitation given the necessity for interpretable and reliable technology. Despite a surge of reasoning benchmarks emerging from the academic community, no comprehensive and theoretically-motivated framework exists to quantify reasoning (and more generally, symbolic ability) in AI systems. Here, we adopt a framework from computational complexity theory to explicitly quantify symbolic generalization: algebraic circuit complexity. Many symbolic reasoning problems can be recast as algebraic expressions. Thus, algebraic circuit complexity theory - the study of algebraic expressions as circuit models (i.e., directed acyclic graphs) - is a natural framework to study the complexity of symbolic computation. The tools of algebraic circuit complexity enable the study of generalization by defining benchmarks in terms of their complexity-theoretic properties (i.e., the difficulty of a problem). Moreover, algebraic circuits are generic mathematical objects; for a given algebraic circuit, an arbitrarily large number of samples can be generated for a specific circuit, making it an optimal testbed for the data-hungry machine learning algorithms that are used today. Here, we adopt tools from algebraic circuit complexity theory, apply it to formalize a science of symbolic generalization, and address key theoretical and empirical challenges for its successful application to AI science and its impact on the broader community.
The Importance of Positional Encoding Initialization in Transformers for Relational Reasoning
Jun 12, 2024Relational reasoning refers to the ability to infer and understand the relations between multiple entities. In humans, this ability underpins many higher cognitive functions, such as problem solving and decision-making, and has been reliably linked to fluid intelligence. Despite machine learning models making impressive advances across various domains, such as natural language processing and vision, the extent to which such models can perform relational reasoning tasks remains unclear. Here we study the importance of positional encoding (PE) for relational reasoning in the Transformer, and find that a learnable PE outperforms all other commonly-used PEs (e.g., absolute, relative, rotary, etc.). Moreover, we find that when using a PE with a learnable parameter, the choice of initialization greatly influences the learned representations and its downstream generalization performance. Specifically, we find that a learned PE initialized from a small-norm distribution can 1) uncover ground-truth position information, 2) generalize in the presence of noisy inputs, and 3) produce behavioral patterns that are consistent with human performance. Our results shed light on the importance of learning high-performing and robust PEs during relational reasoning tasks, which will prove useful for tasks in which ground truth positions are not provided or not known.
EXPLORER: Exploration-guided Reasoning for Textual Reinforcement Learning
Mar 15, 2024Text-based games (TBGs) have emerged as an important collection of NLP tasks, requiring reinforcement learning (RL) agents to combine natural language understanding with reasoning. A key challenge for agents attempting to solve such tasks is to generalize across multiple games and demonstrate good performance on both seen and unseen objects. Purely deep-RL-based approaches may perform well on seen objects; however, they fail to showcase the same performance on unseen objects. Commonsense-infused deep-RL agents may work better on unseen data; unfortunately, their policies are often not interpretable or easily transferable. To tackle these issues, in this paper, we present EXPLORER which is an exploration-guided reasoning agent for textual reinforcement learning. EXPLORER is neurosymbolic in nature, as it relies on a neural module for exploration and a symbolic module for exploitation. It can also learn generalized symbolic policies and perform well over unseen data. Our experiments show that EXPLORER outperforms the baseline agents on Text-World cooking (TW-Cooking) and Text-World Commonsense (TWC) games.
On the generalization capacity of neural networks during generic multimodal reasoning
Jan 26, 2024The advent of the Transformer has led to the development of large language models (LLM), which appear to demonstrate human-like capabilities. To assess the generality of this class of models and a variety of other base neural network architectures to multimodal domains, we evaluated and compared their capacity for multimodal generalization. We introduce a multimodal question-answer benchmark to evaluate three specific types of out-of-distribution (OOD) generalization performance: distractor generalization (generalization in the presence of distractors), systematic compositional generalization (generalization to new task permutations), and productive compositional generalization (generalization to more complex tasks structures). We found that across model architectures (e.g., RNNs, Transformers, Perceivers, etc.), models with multiple attention layers, or models that leveraged cross-attention mechanisms between input domains, fared better. Our positive results demonstrate that for multimodal distractor and systematic generalization, either cross-modal attention or models with deeper attention layers are key architectural features required to integrate multimodal inputs. On the other hand, neither of these architectural features led to productive generalization, suggesting fundamental limitations of existing architectures for specific types of multimodal generalization. These results demonstrate the strengths and limitations of specific architectural components underlying modern neural models for multimodal reasoning. Finally, we provide Generic COG (gCOG), a configurable benchmark with several multimodal generalization splits, for future studies to explore.
AI Planning Annotation for Sample Efficient Reinforcement Learning
Mar 01, 2022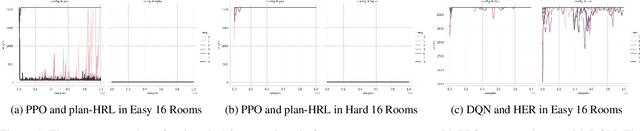

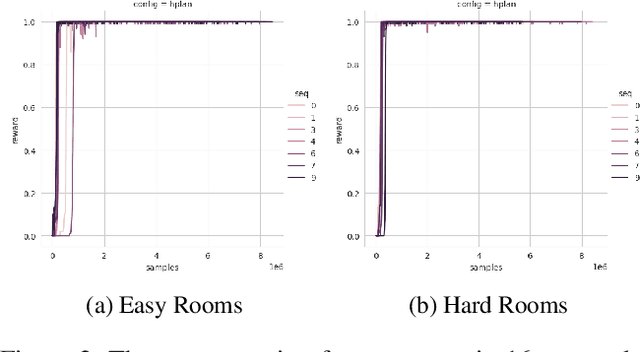
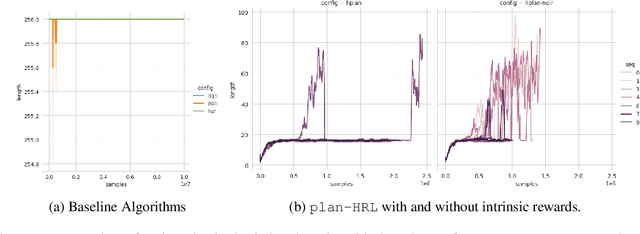
AI planning and Reinforcement Learning (RL) both solve sequential decision-making problems under the different formulations. AI Planning requires operator models, but then allows efficient plan generation. RL requires no operator model, instead learns a policy to guide an agent to high reward states. Planning can be brittle in the face of noise whereas RL is more tolerant. However, RL requires a large number of training examples to learn the policy. In this work, we aim to bring AI planning and RL closer by showing that a suitably defined planning model can be used to improve the efficiency of RL. Specifically, we show that the options in the hierarchical RL can be derived from a planning task and integrate planning and RL algorithms for training option policy functions. Our experiments demonstrate an improved sample efficiency on a variety of RL environments over the previous state-of-the-art.
Combining Fast and Slow Thinking for Human-like and Efficient Navigation in Constrained Environments
Jan 18, 2022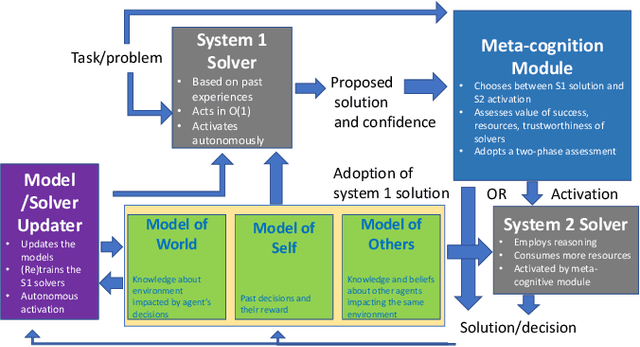
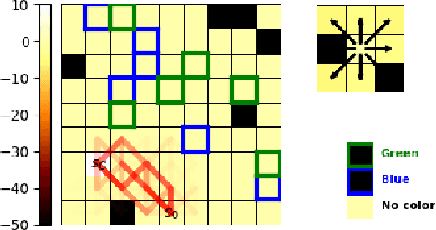

Current AI systems lack several important human capabilities, such as adaptability, generalizability, self-control, consistency, common sense, and causal reasoning. We believe that existing cognitive theories of human decision making, such as the thinking fast and slow theory, can provide insights on how to advance AI systems towards some of these capabilities. In this paper, we propose a general architecture that is based on fast/slow solvers and a metacognitive component. We then present experimental results on the behavior of an instance of this architecture, for AI systems that make decisions about navigating in a constrained environment. We show how combining the fast and slow decision modalities allows the system to evolve over time and gradually pass from slow to fast thinking with enough experience, and that this greatly helps in decision quality, resource consumption, and efficiency.
Thinking Fast and Slow in AI: the Role of Metacognition
Oct 05, 2021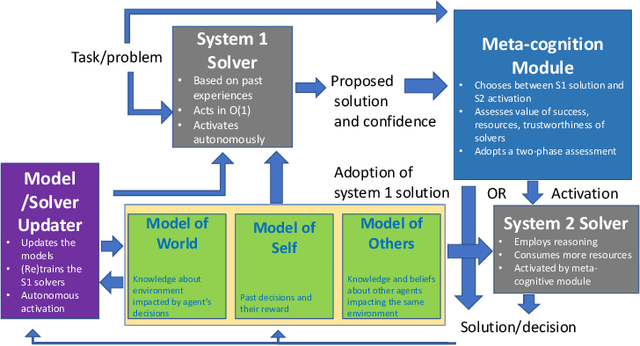
AI systems have seen dramatic advancement in recent years, bringing many applications that pervade our everyday life. However, we are still mostly seeing instances of narrow AI: many of these recent developments are typically focused on a very limited set of competencies and goals, e.g., image interpretation, natural language processing, classification, prediction, and many others. Moreover, while these successes can be accredited to improved algorithms and techniques, they are also tightly linked to the availability of huge datasets and computational power. State-of-the-art AI still lacks many capabilities that would naturally be included in a notion of (human) intelligence. We argue that a better study of the mechanisms that allow humans to have these capabilities can help us understand how to imbue AI systems with these competencies. We focus especially on D. Kahneman's theory of thinking fast and slow, and we propose a multi-agent AI architecture where incoming problems are solved by either system 1 (or "fast") agents, that react by exploiting only past experience, or by system 2 (or "slow") agents, that are deliberately activated when there is the need to reason and search for optimal solutions beyond what is expected from the system 1 agent. Both kinds of agents are supported by a model of the world, containing domain knowledge about the environment, and a model of "self", containing information about past actions of the system and solvers' skills.