 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-line Policy Improvement using Monte-Carlo Search
Jan 09, 2025


We present a Monte-Carlo simulation algorithm for real-time policy improvement of an adaptive controller. In the Monte-Carlo simulation, the long-term expected reward of each possible action is statistically measured, using the initial policy to make decisions in each step of the simulation. The action maximizing the measured expected reward is then taken, resulting in an improved policy. Our algorithm is easily parallelizable and has been implemented on the IBM SP1 and SP2 parallel-RISC supercomputers. We have obtained promising initial results in applying this algorithm to the domain of backgammon. Results are reported for a wide variety of initial policies, ranging from a random policy to TD-Gammon, an extremely strong multi-layer neural network. In each case, the Monte-Carlo algorithm gives a substantial reduction, by as much as a factor of 5 or more, in the error rate of the base players. The algorithm is also potentially useful in many other adaptive control applications in which it is possible to simulate the environment.
* Accompanied by oral presentation by Gregory Galperin at NeurIPS 1996 (then known as NIPS*96)
Learning in Factored Domains with Information-Constrained Visual Representations
Mar 30, 2023Humans learn quickly even in tasks that contain complex visual information. This is due in part to the efficient formation of compressed representations of visual information, allowing for better generalization and robustness. However, compressed representations alone are insufficient for explaining the high speed of human learning. Reinforcement learning (RL) models that seek to replicate this impressive efficiency may do so through the use of factored representations of tasks. These informationally simplistic representations of tasks are similarly motivated as the use of compressed representations of visual information. Recent studies have connected biological visual perception to disentangled and compressed representations. This raises the question of how humans learn to efficiently represent visual information in a manner useful for learning tasks. In this paper we present a model of human factored representation learning based on an altered form of a $\beta$-Variational Auto-encoder used in a visual learning task. Modelling results demonstrate a trade-off in the informational complexity of model latent dimension spaces, between the speed of learning and the accuracy of reconstructions.
Game-Theoretical Perspectives on Active Equilibria: A Preferred Solution Concept over Nash Equilibria
Oct 28, 2022
Multiagent learning settings are inherently more difficult than single-agent learning because each agent interacts with other simultaneously learning agents in a shared environment. An effective approach in multiagent reinforcement learning is to consider the learning process of agents and influence their future policies toward desirable behaviors from each agent's perspective. Importantly, if each agent maximizes its long-term rewards by accounting for the impact of its behavior on the set of convergence policies, the resulting multiagent system reaches an active equilibrium. While this new solution concept is general such that standard solution concepts, such as a Nash equilibrium, are special cases of active equilibria, it is unclear when an active equilibrium is a preferred equilibrium over other solution concepts. In this paper, we analyze active equilibria from a game-theoretic perspective by closely studying examples where Nash equilibria are known. By directly comparing active equilibria to Nash equilibria in these examples, we find that active equilibria find more effective solutions than Nash equilibria, concluding that an active equilibrium is the desired solution for multiagent learning settings.
Influencing Long-Term Behavior in Multiagent Reinforcement Learning
Mar 07, 2022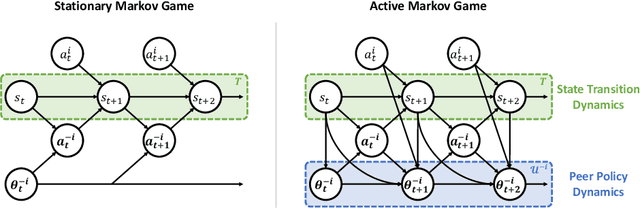
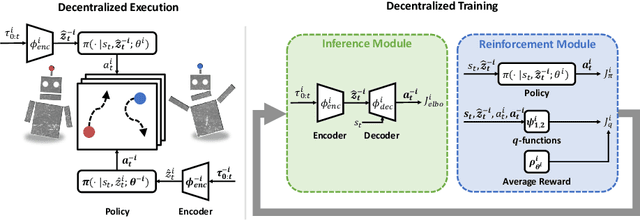
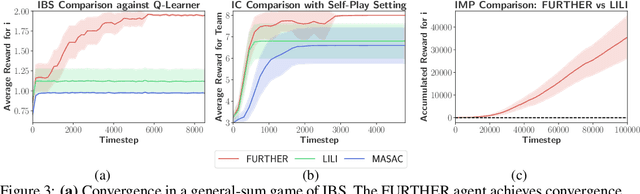
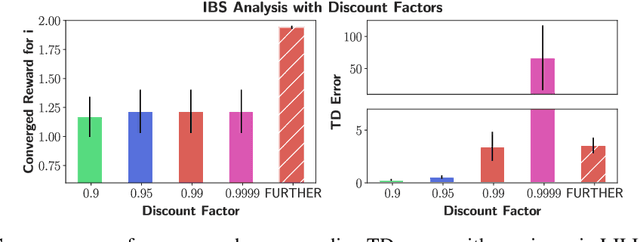
The main challenge of multiagent reinforcement learning is the difficulty of learning useful policies in the presence of other simultaneously learning agents whose changing behaviors jointly affect the environment's transition and reward dynamics. An effective approach that has recently emerged for addressing this non-stationarity is for each agent to anticipate the learning of other interacting agents and influence the evolution of their future policies towards desirable behavior for its own benefit. Unfortunately, all previous approaches for achieving this suffer from myopic evaluation, considering only a few or a finite number of updates to the policies of other agents. In this paper, we propose a principled framework for considering the limiting policies of other agents as the time approaches infinity. Specifically, we develop a new optimization objective that maximizes each agent's average reward by directly accounting for the impact of its behavior on the limiting set of policies that other agents will take on. Thanks to our farsighted evaluation, we demonstrate better long-term performance than state-of-the-art baselines in various domains, including the full spectrum of general-sum, competitive, and cooperative settings.
AI Planning Annotation for Sample Efficient Reinforcement Learning
Mar 01, 2022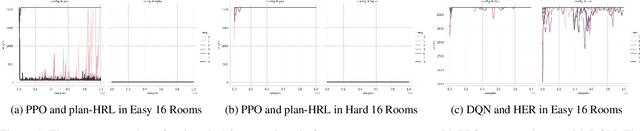

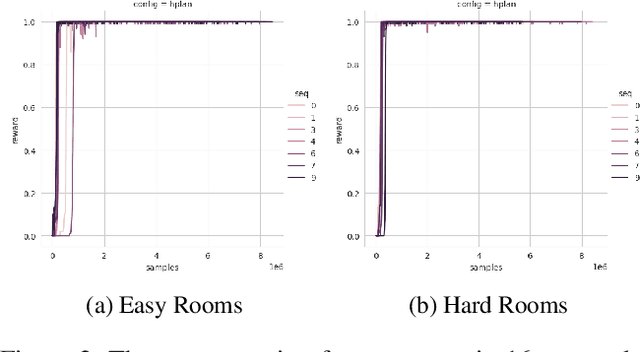
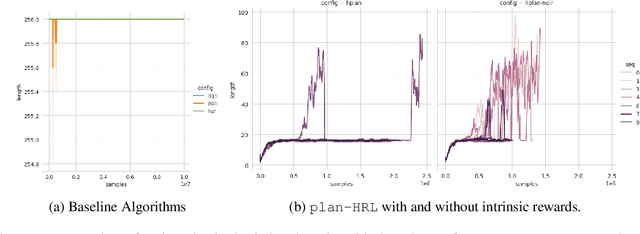
AI planning and Reinforcement Learning (RL) both solve sequential decision-making problems under the different formulations. AI Planning requires operator models, but then allows efficient plan generation. RL requires no operator model, instead learns a policy to guide an agent to high reward states. Planning can be brittle in the face of noise whereas RL is more tolerant. However, RL requires a large number of training examples to learn the policy. In this work, we aim to bring AI planning and RL closer by showing that a suitably defined planning model can be used to improve the efficiency of RL. Specifically, we show that the options in the hierarchical RL can be derived from a planning task and integrate planning and RL algorithms for training option policy functions. Our experiments demonstrate an improved sample efficiency on a variety of RL environments over the previous state-of-the-art.
Context-Specific Representation Abstraction for Deep Option Learning
Sep 20, 2021
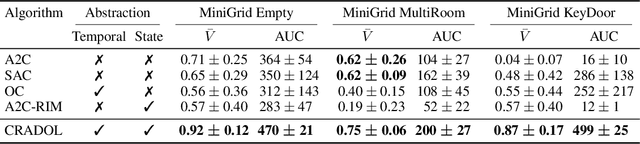
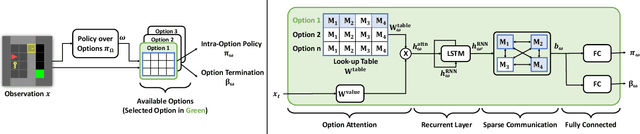
Hierarchical reinforcement learning has focused on discovering temporally extended actions, such as options, that can provide benefits in problems requiring extensive exploration. One promising approach that learns these options end-to-end is the option-critic (OC) framework. We examine and show in this paper that OC does not decompose a problem into simpler sub-problems, but instead increases the size of the search over policy space with each option considering the entire state space during learning. This issue can result in practical limitations of this method, including sample inefficient learning. To address this problem, we introduce Context-Specific Representation Abstraction for Deep Option Learning (CRADOL), a new framework that considers both temporal abstraction and context-specific representation abstraction to effectively reduce the size of the search over policy space. Specifically, our method learns a factored belief state representation that enables each option to learn a policy over only a subsection of the state space. We test our method against hierarchical, non-hierarchical, and modular recurrent neural network baselines, demonstrating significant sample efficiency improvements in challenging partially observable environments.
Consolidation via Policy Information Regularization in Deep RL for Multi-Agent Games
Nov 23, 2020
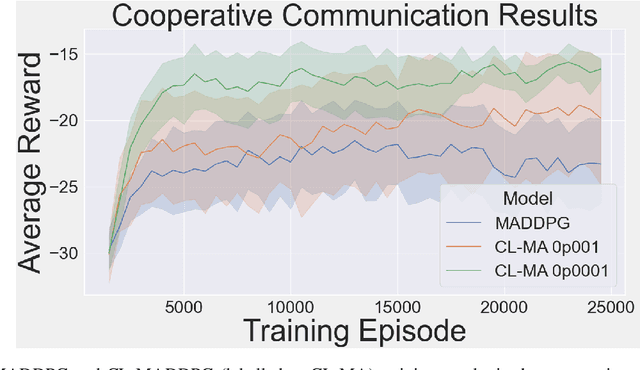
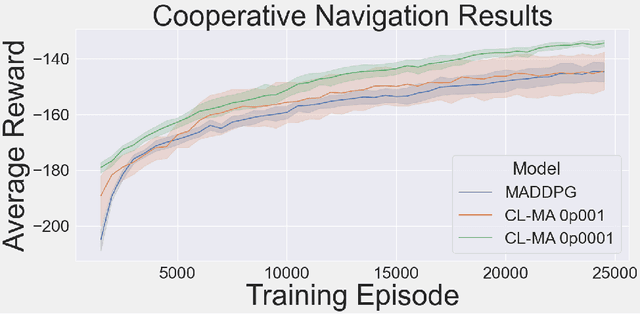
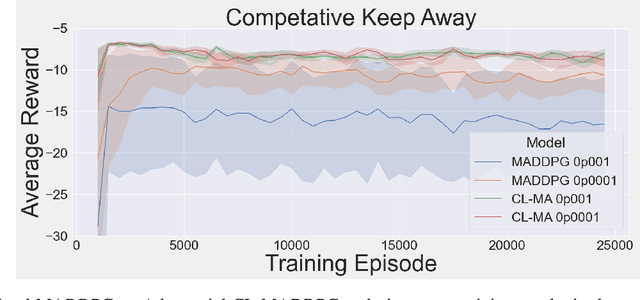
This paper introduces an information-theoretic constraint on learned policy complexity in the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) reinforcement learning algorithm. Previous research with a related approach in continuous control experiments suggests that this method favors learning policies that are more robust to changing environment dynamics. The multi-agent game setting naturally requires this type of robustness, as other agents' policies change throughout learning, introducing a nonstationary environment. For this reason, recent methods in continual learning are compared to our approach, termed Capacity-Limited MADDPG. Results from experimentation in multi-agent cooperative and competitive tasks demonstrate that the capacity-limited approach is a good candidate for improving learning performance in these environments.
A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
Oct 31, 2020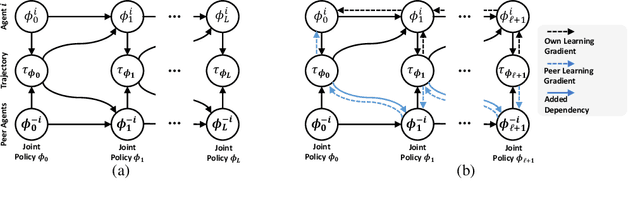
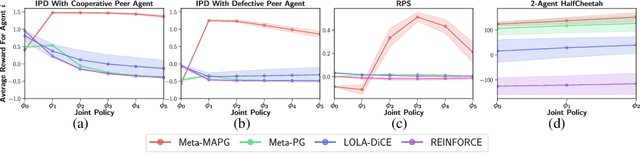

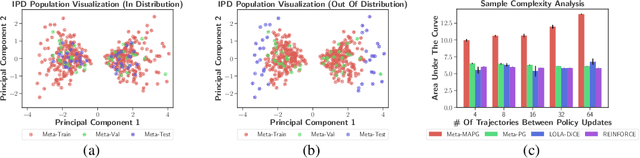
A fundamental challenge in multiagent reinforcement learning is to learn beneficial behaviors in a shared environment with other agents that are also simultaneously learning. In particular, each agent perceives the environment as effectively non-stationary due to the changing policies of other agents. Moreover, each agent is itself constantly learning, leading to natural nonstationarity in the distribution of experiences encountered. In this paper, we propose a novel meta-multiagent policy gradient theorem that directly accommodates for the non-stationary policy dynamics inherent to these multiagent settings. This is achieved by modeling our gradient updates to directly consider both an agent's own non-stationary policy dynamics and the non-stationary policy dynamics of other agents interacting with it in the environment. We find that our theoretically grounded approach provides a general solution to the multiagent learning problem, which inherently combines key aspects of previous state of the art approaches on this topic. We test our method on several multiagent benchmarks and demonstrate a more efficient ability to adapt to new agents as they learn than previous related approaches across the spectrum of mixed incentive, competitive, and cooperative environments.
Deep RL With Information Constrained Policies: Generalization in Continuous Control
Oct 09, 2020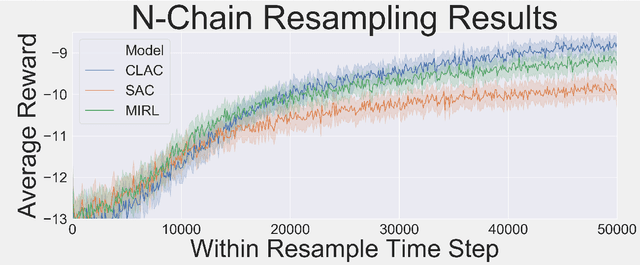
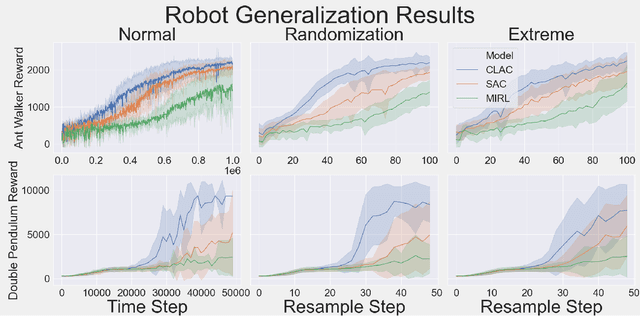
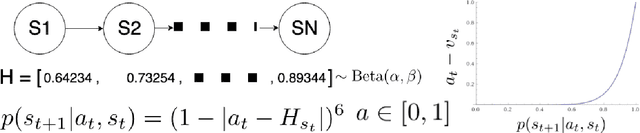
Biological agents learn and act intelligently in spite of a highly limited capacity to process and store information. Many real-world problems involve continuous control, which represents a difficult task for artificial intelligence agents. In this paper we explore the potential learning advantages a natural constraint on information flow might confer onto artificial agents in continuous control tasks. We focus on the model-free reinforcement learning (RL) setting and formalize our approach in terms of an information-theoretic constraint on the complexity of learned policies. We show that our approach emerges in a principled fashion from the application of rate-distortion theory. We implement a novel Capacity-Limited Actor-Critic (CLAC) algorithm and situate it within a broader family of RL algorithms such as the Soft Actor Critic (SAC) and Mutual Information Reinforcement Learning (MIRL) algorithm. Our experiments using continuous control tasks show that compared to alternative approaches, CLAC offers improvements in generalization between training and modified test environments. This is achieved in the CLAC model while displaying the high sample efficiency of similar methods.
Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines
Oct 08, 2020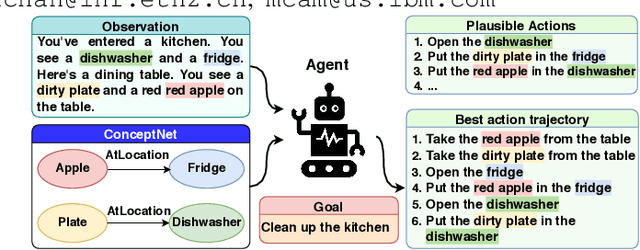


Text-based games have emerged as an important test-bed for Reinforcement Learning (RL) research, requiring RL agents to combine grounded language understanding with sequential decision making. In this paper, we examine the problem of infusing RL agents with commonsense knowledge. Such knowledge would allow agents to efficiently act in the world by pruning out implausible actions, and to perform look-ahead planning to determine how current actions might affect future world states. We design a new text-based gaming environment called TextWorld Commonsense (TWC) for training and evaluating RL agents with a specific kind of commonsense knowledge about objects, their attributes, and affordances. We also introduce several baseline RL agents which track the sequential context and dynamically retrieve the relevant commonsense knowledge from ConceptNet. We show that agents which incorporate commonsense knowledge in TWC perform better, while acting more efficiently. We conduct user-studies to estimate human performance on TWC and show that there is ample room for future improvement.