 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluencing Long-Term Behavior in Multiagent Reinforcement Learning
Paper and Code
Mar 07, 2022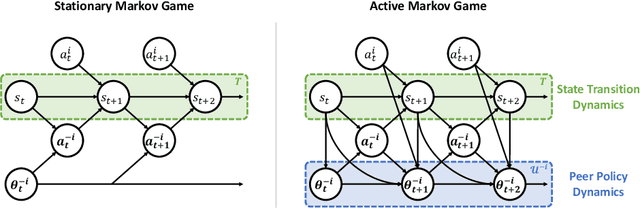
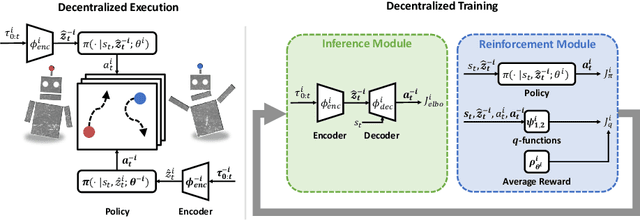
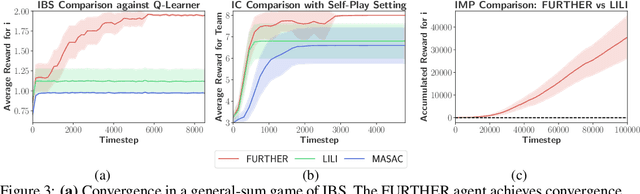
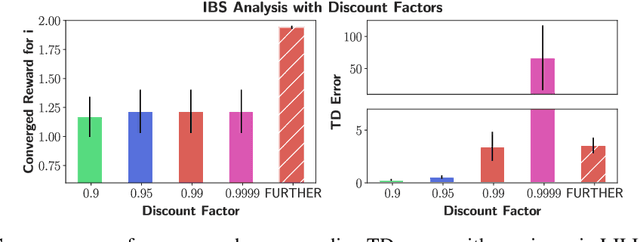
The main challenge of multiagent reinforcement learning is the difficulty of learning useful policies in the presence of other simultaneously learning agents whose changing behaviors jointly affect the environment's transition and reward dynamics. An effective approach that has recently emerged for addressing this non-stationarity is for each agent to anticipate the learning of other interacting agents and influence the evolution of their future policies towards desirable behavior for its own benefit. Unfortunately, all previous approaches for achieving this suffer from myopic evaluation, considering only a few or a finite number of updates to the policies of other agents. In this paper, we propose a principled framework for considering the limiting policies of other agents as the time approaches infinity. Specifically, we develop a new optimization objective that maximizes each agent's average reward by directly accounting for the impact of its behavior on the limiting set of policies that other agents will take on. Thanks to our farsighted evaluation, we demonstrate better long-term performance than state-of-the-art baselines in various domains, including the full spectrum of general-sum, competitive, and cooperative settings.