 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Generation of Algorithm Discovery Tasks in Machine Learning
Mar 18, 2026Automating the development of machine learning algorithms has the potential to unlock new breakthroughs. However, our ability to improve and evaluate algorithm discovery systems has thus far been limited by existing task suites. They suffer from many issues, such as: poor evaluation methodologies; data contamination; and containing saturated or very similar problems. Here, we introduce DiscoGen, a procedural generator of algorithm discovery tasks for machine learning, such as developing optimisers for reinforcement learning or loss functions for image classification. Motivated by the success of procedural generation in reinforcement learning, DiscoGen spans millions of tasks of varying difficulty and complexity from a range of machine learning fields. These tasks are specified by a small number of configuration parameters and can be used to optimise algorithm discovery agents (ADAs). We present DiscoBench, a benchmark consisting of a fixed, small subset of DiscoGen tasks for principled evaluation of ADAs. Finally, we propose a number of ambitious, impactful research directions enabled by DiscoGen, in addition to experiments demonstrating its use for prompt optimisation of an ADA. DiscoGen is released open-source at https://github.com/AlexGoldie/discogen.
Intent Factored Generation: Unleashing the Diversity in Your Language Model
Jun 11, 2025Obtaining multiple meaningfully diverse, high quality samples from Large Language Models for a fixed prompt remains an open challenge. Current methods for increasing diversity often only operate at the token-level, paraphrasing the same response. This is problematic because it leads to poor exploration on reasoning problems and to unengaging, repetitive conversational agents. To address this we propose Intent Factored Generation (IFG), factorising the sampling process into two stages. First, we sample a semantically dense intent, e.g., a summary or keywords. Second, we sample the final response conditioning on both the original prompt and the intent from the first stage. This allows us to use a higher temperature during the intent step to promote conceptual diversity, and a lower temperature during the final generation to ensure the outputs are coherent and self-consistent. Additionally, we find that prompting the model to explicitly state its intent for each step of the chain-of-thought before generating the step is beneficial for reasoning tasks. We demonstrate our method's effectiveness across a diverse set of tasks. We show this method improves both pass@k and Reinforcement Learning from Verifier Feedback on maths and code tasks. For instruction-tuning, we combine IFG with Direct Preference Optimisation to increase conversational diversity without sacrificing reward. Finally, we achieve higher diversity while maintaining the quality of generations on a general language modelling task, using a new dataset of reader comments and news articles that we collect and open-source. In summary, we present a simple method of increasing the sample diversity of LLMs while maintaining performance. This method can be implemented by changing the prompt and varying the temperature during generation, making it easy to integrate into many algorithms for gains across various applications.
High Accuracy, Less Talk (HALT): Reliable LLMs through Capability-Aligned Finetuning
Jun 04, 2025Large Language Models (LLMs) currently respond to every prompt. However, they can produce incorrect answers when they lack knowledge or capability -- a problem known as hallucination. We instead propose post-training an LLM to generate content only when confident in its correctness and to otherwise (partially) abstain. Specifically, our method, HALT, produces capability-aligned post-training data that encodes what the model can and cannot reliably generate. We generate this data by splitting responses of the pretrained LLM into factual fragments (atomic statements or reasoning steps), and use ground truth information to identify incorrect fragments. We achieve capability-aligned finetuning responses by either removing incorrect fragments or replacing them with "Unsure from Here" -- according to a tunable threshold that allows practitioners to trade off response completeness and mean correctness of the response's fragments. We finetune four open-source models for biography writing, mathematics, coding, and medicine with HALT for three different trade-off thresholds. HALT effectively trades off response completeness for correctness, increasing the mean correctness of response fragments by 15% on average, while resulting in a 4% improvement in the F1 score (mean of completeness and correctness of the response) compared to the relevant baselines. By tuning HALT for highest correctness, we train a single reliable Llama3-70B model with correctness increased from 51% to 87% across all four domains while maintaining 53% of the response completeness achieved with standard finetuning.
SOReL and TOReL: Two Methods for Fully Offline Reinforcement Learning
May 28, 2025Sample efficiency remains a major obstacle for real world adoption of reinforcement learning (RL): success has been limited to settings where simulators provide access to essentially unlimited environment interactions, which in reality are typically costly or dangerous to obtain. Offline RL in principle offers a solution by exploiting offline data to learn a near-optimal policy before deployment. In practice, however, current offline RL methods rely on extensive online interactions for hyperparameter tuning, and have no reliable bound on their initial online performance. To address these two issues, we introduce two algorithms. Firstly, SOReL: an algorithm for safe offline reinforcement learning. Using only offline data, our Bayesian approach infers a posterior over environment dynamics to obtain a reliable estimate of the online performance via the posterior predictive uncertainty. Crucially, all hyperparameters are also tuned fully offline. Secondly, we introduce TOReL: a tuning for offline reinforcement learning algorithm that extends our information rate based offline hyperparameter tuning methods to general offline RL approaches. Our empirical evaluation confirms SOReL's ability to accurately estimate regret in the Bayesian setting whilst TOReL's offline hyperparameter tuning achieves competitive performance with the best online hyperparameter tuning methods using only offline data. Thus, SOReL and TOReL make a significant step towards safe and reliable offline RL, unlocking the potential for RL in the real world. Our implementations are publicly available: https://github.com/CWibault/sorel\_torel.
An Optimisation Framework for Unsupervised Environment Design
May 27, 2025For reinforcement learning agents to be deployed in high-risk settings, they must achieve a high level of robustness to unfamiliar scenarios. One method for improving robustness is unsupervised environment design (UED), a suite of methods aiming to maximise an agent's generalisability across configurations of an environment. In this work, we study UED from an optimisation perspective, providing stronger theoretical guarantees for practical settings than prior work. Whereas previous methods relied on guarantees if they reach convergence, our framework employs a nonconvex-strongly-concave objective for which we provide a provably convergent algorithm in the zero-sum setting. We empirically verify the efficacy of our method, outperforming prior methods in a number of environments with varying difficulties.
Beyond the Boundaries of Proximal Policy Optimization
Nov 01, 2024
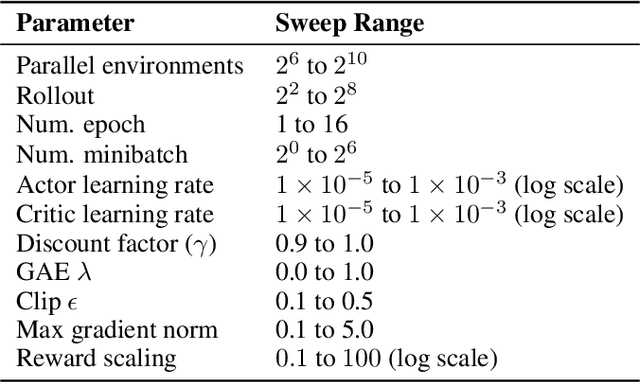
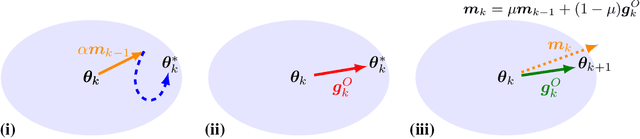

Proximal policy optimization (PPO) is a widely-used algorithm for on-policy reinforcement learning. This work offers an alternative perspective of PPO, in which it is decomposed into the inner-loop estimation of update vectors, and the outer-loop application of updates using gradient ascent with unity learning rate. Using this insight we propose outer proximal policy optimization (outer-PPO); a framework wherein these update vectors are applied using an arbitrary gradient-based optimizer. The decoupling of update estimation and update application enabled by outer-PPO highlights several implicit design choices in PPO that we challenge through empirical investigation. In particular we consider non-unity learning rates and momentum applied to the outer loop, and a momentum-bias applied to the inner estimation loop. Methods are evaluated against an aggressively tuned PPO baseline on Brax, Jumanji and MinAtar environments; non-unity learning rates and momentum both achieve statistically significant improvement on Brax and Jumanji, given the same hyperparameter tuning budget.
Opponent Shaping for Antibody Development
Sep 19, 2024Anti-viral therapies are typically designed or evolved towards the current strains of a virus. In learning terms, this corresponds to a myopic best response, i.e., not considering the possible adaptive moves of the opponent. However, therapy-induced selective pressures act on viral antigens to drive the emergence of mutated strains, against which initial therapies have reduced efficacy. To motivate our work, we consider antibody designs that target not only the current viral strains but also the wide range of possible future variants that the virus might evolve into under the evolutionary pressure exerted by said antibodies. Building on a computational model of binding between antibodies and viral antigens (the Absolut! framework), we design and implement a genetic simulation of the viral evolutionary escape. Crucially, this allows our antibody optimisation algorithm to consider and influence the entire escape curve of the virus, i.e. to guide (or ''shape'') the viral evolution. This is inspired by opponent shaping which, in general-sum learning, accounts for the adaptation of the co-player rather than playing a myopic best response. Hence we call the optimised antibodies shapers. Within our simulations, we demonstrate that our shapers target both current and simulated future viral variants, outperforming the antibodies chosen in a myopic way. Furthermore, we show that shapers exert specific evolutionary pressure on the virus compared to myopic antibodies. Altogether, shapers modify the evolutionary trajectories of viral strains and minimise the viral escape compared to their myopic counterparts. While this is a simple model, we hope that our proposed paradigm will enable the discovery of better long-lived vaccines and antibody therapies in the future, enabled by rapid advancements in the capabilities of simulation tools.
Discovering Minimal Reinforcement Learning Environments
Jun 18, 2024Reinforcement learning (RL) agents are commonly trained and evaluated in the same environment. In contrast, humans often train in a specialized environment before being evaluated, such as studying a book before taking an exam. The potential of such specialized training environments is still vastly underexplored, despite their capacity to dramatically speed up training. The framework of synthetic environments takes a first step in this direction by meta-learning neural network-based Markov decision processes (MDPs). The initial approach was limited to toy problems and produced environments that did not transfer to unseen RL algorithms. We extend this approach in three ways: Firstly, we modify the meta-learning algorithm to discover environments invariant towards hyperparameter configurations and learning algorithms. Secondly, by leveraging hardware parallelism and introducing a curriculum on an agent's evaluation episode horizon, we can achieve competitive results on several challenging continuous control problems. Thirdly, we surprisingly find that contextual bandits enable training RL agents that transfer well to their evaluation environment, even if it is a complex MDP. Hence, we set up our experiments to train synthetic contextual bandits, which perform on par with synthetic MDPs, yield additional insights into the evaluation environment, and can speed up downstream applications.
HelloFresh: LLM Evaluations on Streams of Real-World Human Editorial Actions across X Community Notes and Wikipedia edits
Jun 05, 2024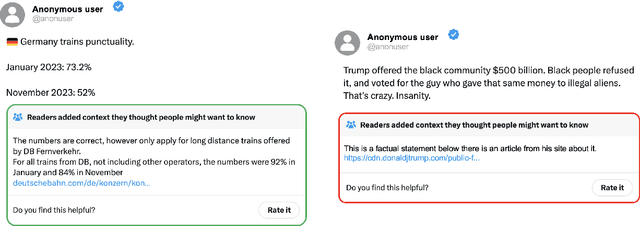


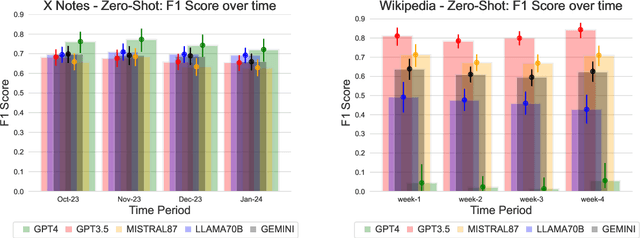
Benchmarks have been essential for driving progress in machine learning. A better understanding of LLM capabilities on real world tasks is vital for safe development. Designing adequate LLM benchmarks is challenging: Data from real-world tasks is hard to collect, public availability of static evaluation data results in test data contamination and benchmark overfitting, and periodically generating new evaluation data is tedious and may result in temporally inconsistent results. We introduce HelloFresh, based on continuous streams of real-world data generated by intrinsically motivated human labelers. It covers recent events from X (formerly Twitter) community notes and edits of Wikipedia pages, mitigating the risk of test data contamination and benchmark overfitting. Any X user can propose an X note to add additional context to a misleading post (formerly tweet); if the community classifies it as helpful, it is shown with the post. Similarly, Wikipedia relies on community-based consensus, allowing users to edit articles or revert edits made by other users. Verifying whether an X note is helpful or whether a Wikipedia edit should be accepted are hard tasks that require grounding by querying the web. We backtest state-of-the-art LLMs supplemented with simple web search access and find that HelloFresh yields a temporally consistent ranking. To enable continuous evaluation on HelloFresh, we host a public leaderboard and periodically updated evaluation data at https://tinyurl.com/hello-fresh-LLM.
SMACv2: An Improved Benchmark for Cooperative Multi-Agent Reinforcement Learning
Dec 14, 2022
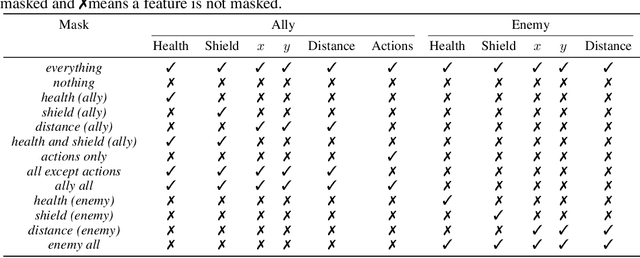
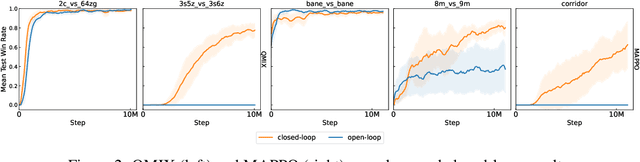
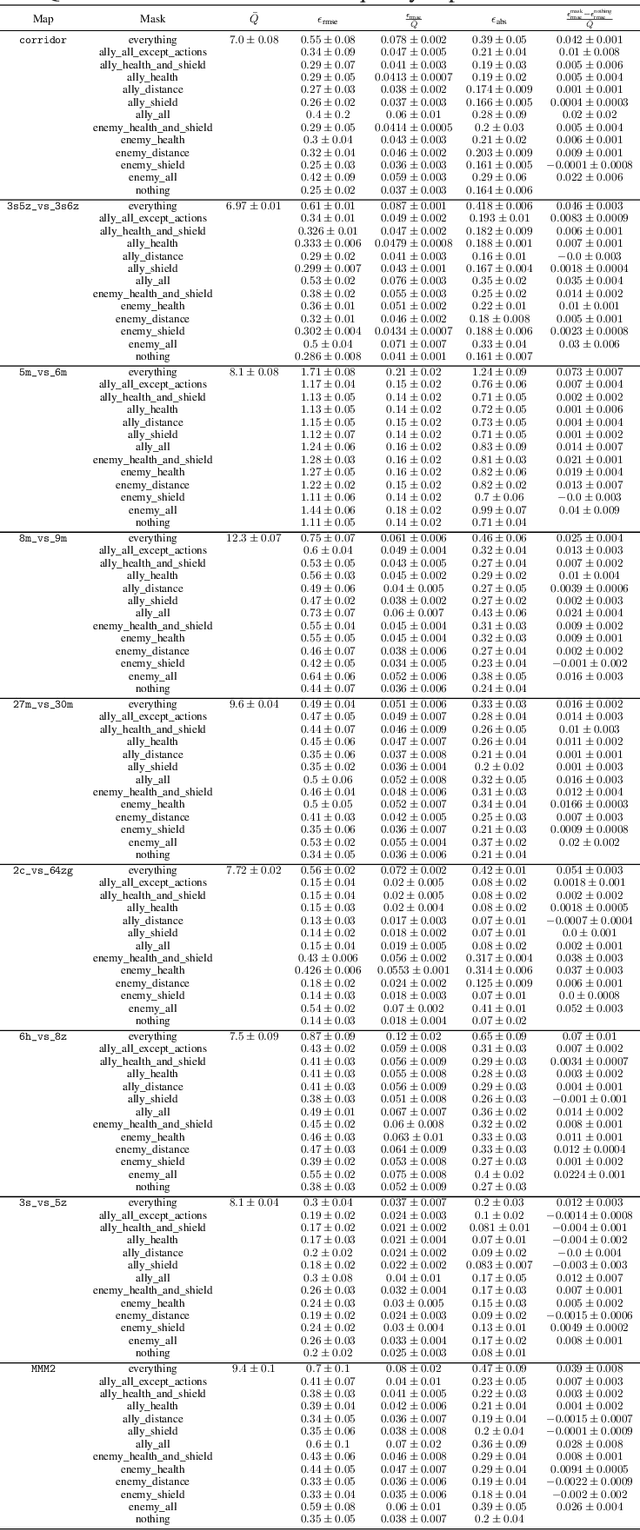
The availability of challenging benchmarks has played a key role in the recent progress of machine learning. In cooperative multi-agent reinforcement learning, the StarCraft Multi-Agent Challenge (SMAC) has become a popular testbed for centralised training with decentralised execution. However, after years of sustained improvement on SMAC, algorithms now achieve near-perfect performance. In this work, we conduct new analysis demonstrating that SMAC is not sufficiently stochastic to require complex closed-loop policies. In particular, we show that an open-loop policy conditioned only on the timestep can achieve non-trivial win rates for many SMAC scenarios. To address this limitation, we introduce SMACv2, a new version of the benchmark where scenarios are procedurally generated and require agents to generalise to previously unseen settings (from the same distribution) during evaluation. We show that these changes ensure the benchmark requires the use of closed-loop policies. We evaluate state-of-the-art algorithms on SMACv2 and show that it presents significant challenges not present in the original benchmark. Our analysis illustrates that SMACv2 addresses the discovered deficiencies of SMAC and can help benchmark the next generation of MARL methods. Videos of training are available at https://sites.google.com/view/smacv2