 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clean Slate for Offline Reinforcement Learning
Apr 15, 2025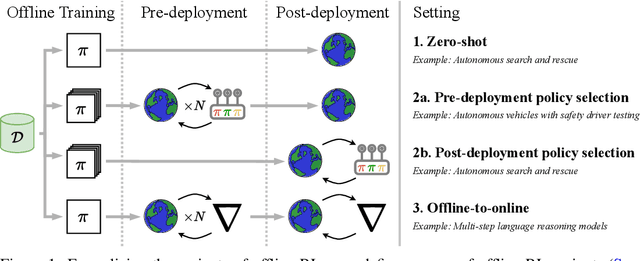

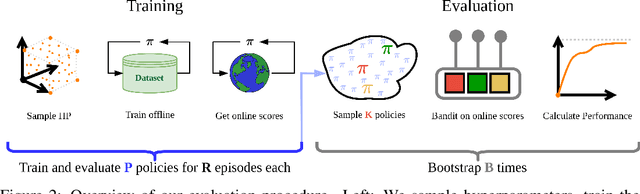

Progress in offline reinforcement learning (RL) has been impeded by ambiguous problem definitions and entangled algorithmic designs, resulting in inconsistent implementations, insufficient ablations, and unfair evaluations. Although offline RL explicitly avoids environment interaction, prior methods frequently employ extensive, undocumented online evaluation for hyperparameter tuning, complicating method comparisons. Moreover, existing reference implementations differ significantly in boilerplate code, obscuring their core algorithmic contributions. We address these challenges by first introducing a rigorous taxonomy and a transparent evaluation protocol that explicitly quantifies online tuning budgets. To resolve opaque algorithmic design, we provide clean, minimalistic, single-file implementations of various model-free and model-based offline RL methods, significantly enhancing clarity and achieving substantial speed-ups. Leveraging these streamlined implementations, we propose Unifloral, a unified algorithm that encapsulates diverse prior approaches within a single, comprehensive hyperparameter space, enabling algorithm development in a shared hyperparameter space. Using Unifloral with our rigorous evaluation protocol, we develop two novel algorithms - TD3-AWR (model-free) and MoBRAC (model-based) - which substantially outperform established baselines. Our implementation is publicly available at https://github.com/EmptyJackson/unifloral.
NAVIX: Scaling MiniGrid Environments with JAX
Jul 28, 2024



As Deep Reinforcement Learning (Deep RL) research moves towards solving large-scale worlds, efficient environment simulations become crucial for rapid experimentation. However, most existing environments struggle to scale to high throughput, setting back meaningful progress. Interactions are typically computed on the CPU, limiting training speed and throughput, due to slower computation and communication overhead when distributing the task across multiple machines. Ultimately, Deep RL training is CPU-bound, and developing batched, fast, and scalable environments has become a frontier for progress. Among the most used Reinforcement Learning (RL) environments, MiniGrid is at the foundation of several studies on exploration, curriculum learning, representation learning, diversity, meta-learning, credit assignment, and language-conditioned RL, and still suffers from the limitations described above. In this work, we introduce NAVIX, a re-implementation of MiniGrid in JAX. NAVIX achieves over 200 000x speed improvements in batch mode, supporting up to 2048 agents in parallel on a single Nvidia A100 80 GB. This reduces experiment times from one week to 15 minutes, promoting faster design iterations and more scalable RL model development.
Behaviour Distillation
Jun 21, 2024



Dataset distillation aims to condense large datasets into a small number of synthetic examples that can be used as drop-in replacements when training new models. It has applications to interpretability, neural architecture search, privacy, and continual learning. Despite strong successes in supervised domains, such methods have not yet been extended to reinforcement learning, where the lack of a fixed dataset renders most distillation methods unusable. Filling the gap, we formalize behaviour distillation, a setting that aims to discover and then condense the information required for training an expert policy into a synthetic dataset of state-action pairs, without access to expert data. We then introduce Hallucinating Datasets with Evolution Strategies (HaDES), a method for behaviour distillation that can discover datasets of just four state-action pairs which, under supervised learning, train agents to competitive performance levels in continuous control tasks. We show that these datasets generalize out of distribution to training policies with a wide range of architectures and hyperparameters. We also demonstrate application to a downstream task, namely training multi-task agents in a zero-shot fashion. Beyond behaviour distillation, HaDES provides significant improvements in neuroevolution for RL over previous approaches and achieves SoTA results on one standard supervised dataset distillation task. Finally, we show that visualizing the synthetic datasets can provide human-interpretable task insights.
Discovering Minimal Reinforcement Learning Environments
Jun 18, 2024Reinforcement learning (RL) agents are commonly trained and evaluated in the same environment. In contrast, humans often train in a specialized environment before being evaluated, such as studying a book before taking an exam. The potential of such specialized training environments is still vastly underexplored, despite their capacity to dramatically speed up training. The framework of synthetic environments takes a first step in this direction by meta-learning neural network-based Markov decision processes (MDPs). The initial approach was limited to toy problems and produced environments that did not transfer to unseen RL algorithms. We extend this approach in three ways: Firstly, we modify the meta-learning algorithm to discover environments invariant towards hyperparameter configurations and learning algorithms. Secondly, by leveraging hardware parallelism and introducing a curriculum on an agent's evaluation episode horizon, we can achieve competitive results on several challenging continuous control problems. Thirdly, we surprisingly find that contextual bandits enable training RL agents that transfer well to their evaluation environment, even if it is a complex MDP. Hence, we set up our experiments to train synthetic contextual bandits, which perform on par with synthetic MDPs, yield additional insights into the evaluation environment, and can speed up downstream applications.