 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Connectivity on Laplacian Representations in Reinforcement Learning
Mar 09, 2026Learning compact state representations in Markov Decision Processes (MDPs) has proven crucial for addressing the curse of dimensionality in large-scale reinforcement learning (RL) problems. Existing principled approaches leverage structural priors on the MDP by constructing state representations as linear combinations of the state-graph Laplacian eigenvectors. When the transition graph is unknown or the state space is prohibitively large, the graph spectral features can be estimated directly via sample trajectories. In this work, we prove an upper bound on the approximation error of linear value function approximation under the learned spectral features. We show how this error scales with the algebraic connectivity of the state-graph, grounding the approximation quality in the topological structure of the MDP. We further bound the error introduced by the eigenvector estimation itself, leading to an end-to-end error decomposition across the representation learning pipeline. Additionally, our expression of the Laplacian operator for the RL setting, although equivalent to existing ones, prevents some common misunderstandings, of which we show some examples from the literature. Our results hold for general (non-uniform) policies without any assumptions on the symmetry of the induced transition kernel. We validate our theoretical findings with numerical simulations on gridworld environments.
From In Silico to In Vitro: Evaluating Molecule Generative Models for Hit Generation
Dec 26, 2025Hit identification is a critical yet resource-intensive step in the drug discovery pipeline, traditionally relying on high-throughput screening of large compound libraries. Despite advancements in virtual screening, these methods remain time-consuming and costly. Recent progress in deep learning has enabled the development of generative models capable of learning complex molecular representations and generating novel compounds de novo. However, using ML to replace the entire drug-discovery pipeline is highly challenging. In this work, we rather investigate whether generative models can replace one step of the pipeline: hit-like molecule generation. To the best of our knowledge, this is the first study to explicitly frame hit-like molecule generation as a standalone task and empirically test whether generative models can directly support this stage of the drug discovery pipeline. Specifically, we investigate if such models can be trained to generate hit-like molecules, enabling direct incorporation into, or even substitution of, traditional hit identification workflows. We propose an evaluation framework tailored to this task, integrating physicochemical, structural, and bioactivity-related criteria within a multi-stage filtering pipeline that defines the hit-like chemical space. Two autoregressive and one diffusion-based generative models were benchmarked across various datasets and training settings, with outputs assessed using standard metrics and target-specific docking scores. Our results show that these models can generate valid, diverse, and biologically relevant compounds across multiple targets, with a few selected GSK-3$β$ hits synthesized and confirmed active in vitro. We also identify key limitations in current evaluation metrics and available training data.
Reinforcement Learning Using known Invariances
Nov 05, 2025In many real-world reinforcement learning (RL) problems, the environment exhibits inherent symmetries that can be exploited to improve learning efficiency. This paper develops a theoretical and algorithmic framework for incorporating known group symmetries into kernel-based RL. We propose a symmetry-aware variant of optimistic least-squares value iteration (LSVI), which leverages invariant kernels to encode invariance in both rewards and transition dynamics. Our analysis establishes new bounds on the maximum information gain and covering numbers for invariant RKHSs, explicitly quantifying the sample efficiency gains from symmetry. Empirical results on a customized Frozen Lake environment and a 2D placement design problem confirm the theoretical improvements, demonstrating that symmetry-aware RL achieves significantly better performance than their standard kernel counterparts. These findings highlight the value of structural priors in designing more sample-efficient reinforcement learning algorithms.
Bayesian Optimization from Human Feedback: Near-Optimal Regret Bounds
May 29, 2025



Bayesian optimization (BO) with preference-based feedback has recently garnered significant attention due to its emerging applications. We refer to this problem as Bayesian Optimization from Human Feedback (BOHF), which differs from conventional BO by learning the best actions from a reduced feedback model, where only the preference between two actions is revealed to the learner at each time step. The objective is to identify the best action using a limited number of preference queries, typically obtained through costly human feedback. Existing work, which adopts the Bradley-Terry-Luce (BTL) feedback model, provides regret bounds for the performance of several algorithms. In this work, within the same framework we develop tighter performance guarantees. Specifically, we derive regret bounds of $\tilde{\mathcal{O}}(\sqrt{\Gamma(T)T})$, where $\Gamma(T)$ represents the maximum information gain$\unicode{x2014}$a kernel-specific complexity term$\unicode{x2014}$and $T$ is the number of queries. Our results significantly improve upon existing bounds. Notably, for common kernels, we show that the order-optimal sample complexities of conventional BO$\unicode{x2014}$achieved with richer feedback models$\unicode{x2014}$are recovered. In other words, the same number of preferential samples as scalar-valued samples is sufficient to find a nearly optimal solution.
Heterogeneous Graph Structure Learning through the Lens of Data-generating Processes
Mar 11, 2025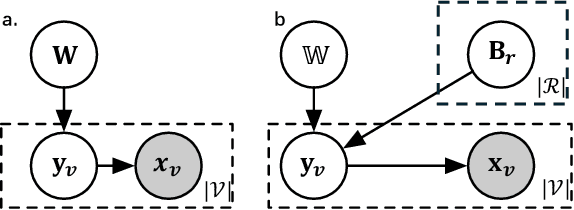



Inferring the graph structure from observed data is a key task in graph machine learning to capture the intrinsic relationship between data entities. While significant advancements have been made in learning the structure of homogeneous graphs, many real-world graphs exhibit heterogeneous patterns where nodes and edges have multiple types. This paper fills this gap by introducing the first approach for heterogeneous graph structure learning (HGSL). To this end, we first propose a novel statistical model for the data-generating process (DGP) of heterogeneous graph data, namely hidden Markov networks for heterogeneous graphs (H2MN). Then we formalize HGSL as a maximum a-posterior estimation problem parameterized by such DGP and derive an alternating optimization method to obtain a solution together with a theoretical justification of the optimization conditions. Finally, we conduct extensive experiments on both synthetic and real-world datasets to demonstrate that our proposed method excels in learning structure on heterogeneous graphs in terms of edge type identification and edge weight recovery.
Near-Optimal Sample Complexity in Reward-Free Kernel-Based Reinforcement Learning
Feb 11, 2025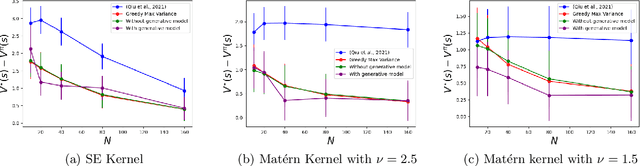

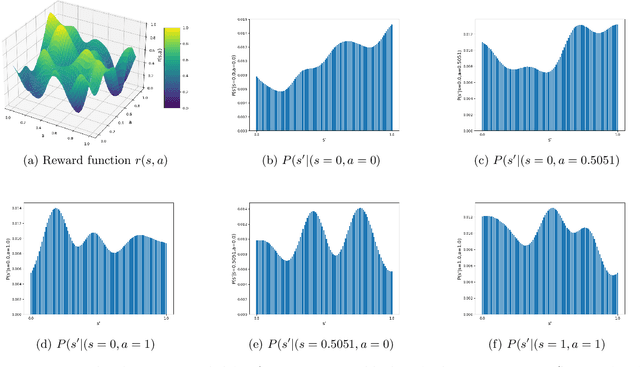
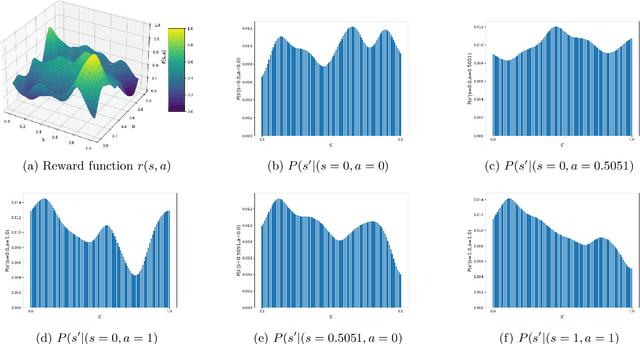
Reinforcement Learning (RL) problems are being considered under increasingly more complex structures. While tabular and linear models have been thoroughly explored, the analytical study of RL under nonlinear function approximation, especially kernel-based models, has recently gained traction for their strong representational capacity and theoretical tractability. In this context, we examine the question of statistical efficiency in kernel-based RL within the reward-free RL framework, specifically asking: how many samples are required to design a near-optimal policy? Existing work addresses this question under restrictive assumptions about the class of kernel functions. We first explore this question by assuming a generative model, then relax this assumption at the cost of increasing the sample complexity by a factor of H, the length of the episode. We tackle this fundamental problem using a broad class of kernels and a simpler algorithm compared to prior work. Our approach derives new confidence intervals for kernel ridge regression, specific to our RL setting, which may be of broader applicability. We further validate our theoretical findings through simulations.
Effects of Random Edge-Dropping on Over-Squashing in Graph Neural Networks
Feb 11, 2025



Message Passing Neural Networks (MPNNs) are a class of Graph Neural Networks (GNNs) that leverage the graph topology to propagate messages across increasingly larger neighborhoods. The message-passing scheme leads to two distinct challenges: over-smoothing and over-squashing. While several algorithms, e.g. DropEdge and its variants -- DropNode, DropAgg and DropGNN -- have successfully addressed the over-smoothing problem, their impact on over-squashing remains largely unexplored. This represents a critical gap in the literature as failure to mitigate over-squashing would make these methods unsuitable for long-range tasks. In this work, we take the first step towards closing this gap by studying the aforementioned algorithms in the context of over-squashing. We present novel theoretical results that characterize the negative effects of DropEdge on sensitivity between distant nodes, suggesting its unsuitability for long-range tasks. Our findings are easily extended to its variants, allowing us to build a comprehensive understanding of how they affect over-squashing. We evaluate these methods using real-world datasets, demonstrating their detrimental effects. Specifically, we show that while DropEdge-variants improve test-time performance in short range tasks, they deteriorate performance in long-range ones. Our theory explains these results as follows: random edge-dropping lowers the effective receptive field of GNNs, which although beneficial for short-range tasks, misaligns the models on long-range ones. This forces the models to overfit to short-range artefacts in the training set, resulting in poor generalization. Our conclusions highlight the need to re-evaluate various methods designed for training deep GNNs, with a renewed focus on modelling long-range interactions.
The impact of intrinsic rewards on exploration in Reinforcement Learning
Jan 20, 2025



One of the open challenges in Reinforcement Learning is the hard exploration problem in sparse reward environments. Various types of intrinsic rewards have been proposed to address this challenge by pushing towards diversity. This diversity might be imposed at different levels, favouring the agent to explore different states, policies or behaviours (State, Policy and Skill level diversity, respectively). However, the impact of diversity on the agent's behaviour remains unclear. In this work, we aim to fill this gap by studying the effect of different levels of diversity imposed by intrinsic rewards on the exploration patterns of RL agents. We select four intrinsic rewards (State Count, Intrinsic Curiosity Module (ICM), Maximum Entropy, and Diversity is all you need (DIAYN)), each pushing for a different diversity level. We conduct an empirical study on MiniGrid environment to compare their impact on exploration considering various metrics related to the agent's exploration, namely: episodic return, observation coverage, agent's position coverage, policy entropy, and timeframes to reach the sparse reward. The main outcome of the study is that State Count leads to the best exploration performance in the case of low-dimensional observations. However, in the case of RGB observations, the performance of State Count is highly degraded mostly due to representation learning challenges. Conversely, Maximum Entropy is less impacted, resulting in a more robust exploration, despite being not always optimal. Lastly, our empirical study revealed that learning diverse skills with DIAYN, often linked to improved robustness and generalisation, does not promote exploration in MiniGrid environments. This is because: i) learning the skill space itself can be challenging, and ii) exploration within the skill space prioritises differentiating between behaviours rather than achieving uniform state visitation.
NAVIX: Scaling MiniGrid Environments with JAX
Jul 28, 2024



As Deep Reinforcement Learning (Deep RL) research moves towards solving large-scale worlds, efficient environment simulations become crucial for rapid experimentation. However, most existing environments struggle to scale to high throughput, setting back meaningful progress. Interactions are typically computed on the CPU, limiting training speed and throughput, due to slower computation and communication overhead when distributing the task across multiple machines. Ultimately, Deep RL training is CPU-bound, and developing batched, fast, and scalable environments has become a frontier for progress. Among the most used Reinforcement Learning (RL) environments, MiniGrid is at the foundation of several studies on exploration, curriculum learning, representation learning, diversity, meta-learning, credit assignment, and language-conditioned RL, and still suffers from the limitations described above. In this work, we introduce NAVIX, a re-implementation of MiniGrid in JAX. NAVIX achieves over 200 000x speed improvements in batch mode, supporting up to 2048 agents in parallel on a single Nvidia A100 80 GB. This reduces experiment times from one week to 15 minutes, promoting faster design iterations and more scalable RL model development.
A Survey of Temporal Credit Assignment in Deep Reinforcement Learning
Dec 02, 2023



The Credit Assignment Problem (CAP) refers to the longstanding challenge of Reinforcement Learning (RL) agents to associate actions with their long-term consequences. Solving the CAP is a crucial step towards the successful deployment of RL in the real world since most decision problems provide feedback that is noisy, delayed, and with little or no information about the causes. These conditions make it hard to distinguish serendipitous outcomes from those caused by informed decision-making. However, the mathematical nature of credit and the CAP remains poorly understood and defined. In this survey, we review the state of the art of Temporal Credit Assignment (CA) in deep RL. We propose a unifying formalism for credit that enables equitable comparisons of state of the art algorithms and improves our understanding of the trade-offs between the various methods. We cast the CAP as the problem of learning the influence of an action over an outcome from a finite amount of experience. We discuss the challenges posed by delayed effects, transpositions, and a lack of action influence, and analyse how existing methods aim to address them. Finally, we survey the protocols to evaluate a credit assignment method, and suggest ways to diagnoses the sources of struggle for different credit assignment methods. Overall, this survey provides an overview of the field for new-entry practitioners and researchers, it offers a coherent perspective for scholars looking to expedite the starting stages of a new study on the CAP, and it suggests potential directions for future research