 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Using known Invariances
Nov 05, 2025In many real-world reinforcement learning (RL) problems, the environment exhibits inherent symmetries that can be exploited to improve learning efficiency. This paper develops a theoretical and algorithmic framework for incorporating known group symmetries into kernel-based RL. We propose a symmetry-aware variant of optimistic least-squares value iteration (LSVI), which leverages invariant kernels to encode invariance in both rewards and transition dynamics. Our analysis establishes new bounds on the maximum information gain and covering numbers for invariant RKHSs, explicitly quantifying the sample efficiency gains from symmetry. Empirical results on a customized Frozen Lake environment and a 2D placement design problem confirm the theoretical improvements, demonstrating that symmetry-aware RL achieves significantly better performance than their standard kernel counterparts. These findings highlight the value of structural priors in designing more sample-efficient reinforcement learning algorithms.
Bayesian Optimization from Human Feedback: Near-Optimal Regret Bounds
May 29, 2025Bayesian optimization (BO) with preference-based feedback has recently garnered significant attention due to its emerging applications. We refer to this problem as Bayesian Optimization from Human Feedback (BOHF), which differs from conventional BO by learning the best actions from a reduced feedback model, where only the preference between two actions is revealed to the learner at each time step. The objective is to identify the best action using a limited number of preference queries, typically obtained through costly human feedback. Existing work, which adopts the Bradley-Terry-Luce (BTL) feedback model, provides regret bounds for the performance of several algorithms. In this work, within the same framework we develop tighter performance guarantees. Specifically, we derive regret bounds of $\tilde{\mathcal{O}}(\sqrt{\Gamma(T)T})$, where $\Gamma(T)$ represents the maximum information gain$\unicode{x2014}$a kernel-specific complexity term$\unicode{x2014}$and $T$ is the number of queries. Our results significantly improve upon existing bounds. Notably, for common kernels, we show that the order-optimal sample complexities of conventional BO$\unicode{x2014}$achieved with richer feedback models$\unicode{x2014}$are recovered. In other words, the same number of preferential samples as scalar-valued samples is sufficient to find a nearly optimal solution.
Near-Optimal Sample Complexity in Reward-Free Kernel-Based Reinforcement Learning
Feb 11, 2025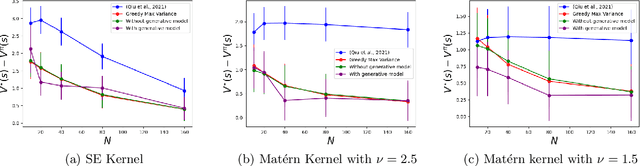

Reinforcement Learning (RL) problems are being considered under increasingly more complex structures. While tabular and linear models have been thoroughly explored, the analytical study of RL under nonlinear function approximation, especially kernel-based models, has recently gained traction for their strong representational capacity and theoretical tractability. In this context, we examine the question of statistical efficiency in kernel-based RL within the reward-free RL framework, specifically asking: how many samples are required to design a near-optimal policy? Existing work addresses this question under restrictive assumptions about the class of kernel functions. We first explore this question by assuming a generative model, then relax this assumption at the cost of increasing the sample complexity by a factor of H, the length of the episode. We tackle this fundamental problem using a broad class of kernels and a simpler algorithm compared to prior work. Our approach derives new confidence intervals for kernel ridge regression, specific to our RL setting, which may be of broader applicability. We further validate our theoretical findings through simulations.
The impact of intrinsic rewards on exploration in Reinforcement Learning
Jan 20, 2025



One of the open challenges in Reinforcement Learning is the hard exploration problem in sparse reward environments. Various types of intrinsic rewards have been proposed to address this challenge by pushing towards diversity. This diversity might be imposed at different levels, favouring the agent to explore different states, policies or behaviours (State, Policy and Skill level diversity, respectively). However, the impact of diversity on the agent's behaviour remains unclear. In this work, we aim to fill this gap by studying the effect of different levels of diversity imposed by intrinsic rewards on the exploration patterns of RL agents. We select four intrinsic rewards (State Count, Intrinsic Curiosity Module (ICM), Maximum Entropy, and Diversity is all you need (DIAYN)), each pushing for a different diversity level. We conduct an empirical study on MiniGrid environment to compare their impact on exploration considering various metrics related to the agent's exploration, namely: episodic return, observation coverage, agent's position coverage, policy entropy, and timeframes to reach the sparse reward. The main outcome of the study is that State Count leads to the best exploration performance in the case of low-dimensional observations. However, in the case of RGB observations, the performance of State Count is highly degraded mostly due to representation learning challenges. Conversely, Maximum Entropy is less impacted, resulting in a more robust exploration, despite being not always optimal. Lastly, our empirical study revealed that learning diverse skills with DIAYN, often linked to improved robustness and generalisation, does not promote exploration in MiniGrid environments. This is because: i) learning the skill space itself can be challenging, and ii) exploration within the skill space prioritises differentiating between behaviours rather than achieving uniform state visitation.