 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Graph Filters via Adaptive Spectral Shaping
Feb 03, 2026We introduce Adaptive Spectral Shaping, a data-driven framework for graph filtering that learns a reusable baseline spectral kernel and modulates it with a small set of Gaussian factors. The resulting multi-peak, multi-scale responses allocate energy to heterogeneous regions of the Laplacian spectrum while remaining interpretable via explicit centers and bandwidths. To scale, we implement filters with Chebyshev polynomial expansions, avoiding eigendecompositions. We further propose Transferable Adaptive Spectral Shaping (TASS): the baseline kernel is learned on source graphs and, on a target graph, kept fixed while only the shaping parameters are adapted, enabling few-shot transfer under matched compute. Across controlled synthetic benchmarks spanning graph families and signal regimes, Adaptive Spectral Shaping reduces reconstruction error relative to fixed-prototype wavelets and learned linear banks, and TASS yields consistent positive transfer. The framework provides compact spectral modules that plug into graph signal processing pipelines and graph neural networks, combining scalability, interpretability, and cross-graph generalization.
On the Importance of Task Complexity in Evaluating LLM-Based Multi-Agent Systems
Oct 05, 2025Large language model multi-agent systems (LLM-MAS) offer a promising paradigm for harnessing collective intelligence to achieve more advanced forms of AI behaviour. While recent studies suggest that LLM-MAS can outperform LLM single-agent systems (LLM-SAS) on certain tasks, the lack of systematic experimental designs limits the strength and generality of these conclusions. We argue that a principled understanding of task complexity, such as the degree of sequential reasoning required and the breadth of capabilities involved, is essential for assessing the effectiveness of LLM-MAS in task solving. To this end, we propose a theoretical framework characterising tasks along two dimensions: depth, representing reasoning length, and width, representing capability diversity. We theoretically examine a representative class of LLM-MAS, namely the multi-agent debate system, and empirically evaluate its performance in both discriminative and generative tasks with varying depth and width. Theoretical and empirical results show that the benefit of LLM-MAS over LLM-SAS increases with both task depth and width, and the effect is more pronounced with respect to depth. This clarifies when LLM-MAS are beneficial and provides a principled foundation for designing future LLM-MAS methods and benchmarks.
Natural Evolutionary Search meets Probabilistic Numerics
Jul 09, 2025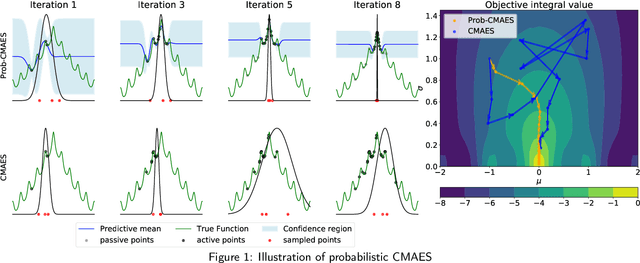
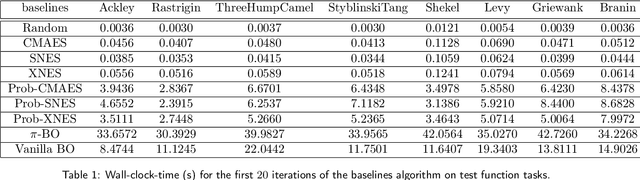
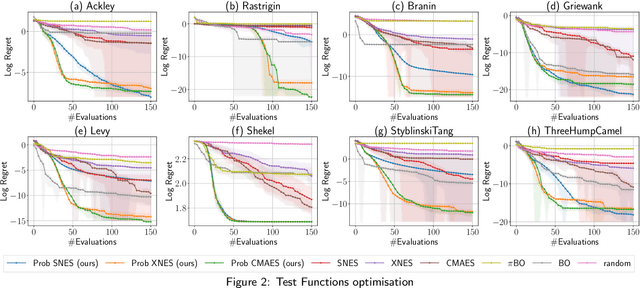
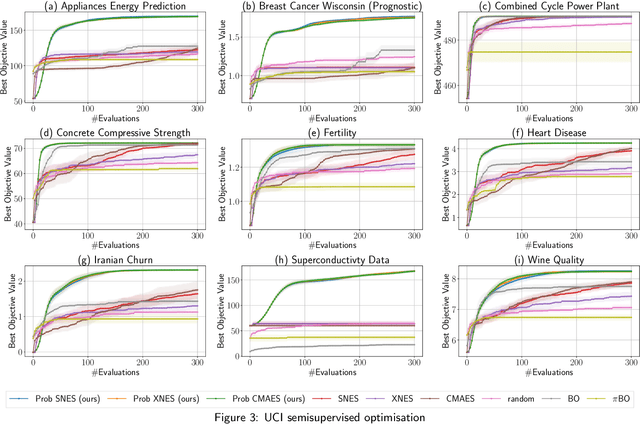
Zeroth-order local optimisation algorithms are essential for solving real-valued black-box optimisation problems. Among these, Natural Evolution Strategies (NES) represent a prominent class, particularly well-suited for scenarios where prior distributions are available. By optimising the objective function in the space of search distributions, NES algorithms naturally integrate prior knowledge during initialisation, making them effective in settings such as semi-supervised learning and user-prior belief frameworks. However, due to their reliance on random sampling and Monte Carlo estimates, NES algorithms can suffer from limited sample efficiency. In this paper, we introduce a novel class of algorithms, termed Probabilistic Natural Evolutionary Strategy Algorithms (ProbNES), which enhance the NES framework with Bayesian quadrature. We show that ProbNES algorithms consistently outperforms their non-probabilistic counterparts as well as global sample efficient methods such as Bayesian Optimisation (BO) or $\pi$BO across a wide range of tasks, including benchmark test functions, data-driven optimisation tasks, user-informed hyperparameter tuning tasks and locomotion tasks.
Return of ChebNet: Understanding and Improving an Overlooked GNN on Long Range Tasks
Jun 09, 2025ChebNet, one of the earliest spectral GNNs, has largely been overshadowed by Message Passing Neural Networks (MPNNs), which gained popularity for their simplicity and effectiveness in capturing local graph structure. Despite their success, MPNNs are limited in their ability to capture long-range dependencies between nodes. This has led researchers to adapt MPNNs through rewiring or make use of Graph Transformers, which compromises the computational efficiency that characterized early spatial message-passing architectures, and typically disregards the graph structure. Almost a decade after its original introduction, we revisit ChebNet to shed light on its ability to model distant node interactions. We find that out-of-box, ChebNet already shows competitive advantages relative to classical MPNNs and GTs on long-range benchmarks, while maintaining good scalability properties for high-order polynomials. However, we uncover that this polynomial expansion leads ChebNet to an unstable regime during training. To address this limitation, we cast ChebNet as a stable and non-dissipative dynamical system, which we coin Stable-ChebNet. Our Stable-ChebNet model allows for stable information propagation, and has controllable dynamics which do not require the use of eigendecompositions, positional encodings, or graph rewiring. Across several benchmarks, Stable-ChebNet achieves near state-of-the-art performance.
On Measuring Long-Range Interactions in Graph Neural Networks
Jun 06, 2025Long-range graph tasks -- those dependent on interactions between distant nodes -- are an open problem in graph neural network research. Real-world benchmark tasks, especially the Long Range Graph Benchmark, have become popular for validating the long-range capability of proposed architectures. However, this is an empirical approach that lacks both robustness and theoretical underpinning; a more principled characterization of the long-range problem is required. To bridge this gap, we formalize long-range interactions in graph tasks, introduce a range measure for operators on graphs, and validate it with synthetic experiments. We then leverage our measure to examine commonly used tasks and architectures, and discuss to what extent they are, in fact, long-range. We believe our work advances efforts to define and address the long-range problem on graphs, and that our range measure will aid evaluation of new datasets and architectures.
Graph and Simplicial Complex Prediction Gaussian Process via the Hodgelet Representations
May 16, 2025Predicting the labels of graph-structured data is crucial in scientific applications and is often achieved using graph neural networks (GNNs). However, when data is scarce, GNNs suffer from overfitting, leading to poor performance. Recently, Gaussian processes (GPs) with graph-level inputs have been proposed as an alternative. In this work, we extend the Gaussian process framework to simplicial complexes (SCs), enabling the handling of edge-level attributes and attributes supported on higher-order simplices. We further augment the resulting SC representations by considering their Hodge decompositions, allowing us to account for homological information, such as the number of holes, in the SC. We demonstrate that our framework enhances the predictions across various applications, paving the way for GPs to be more widely used for graph and SC-level predictions.
GNNs as Predictors of Agentic Workflow Performances
Mar 14, 2025Agentic workflows invoked by Large Language Models (LLMs) have achieved remarkable success in handling complex tasks. However, optimizing such workflows is costly and inefficient in real-world applications due to extensive invocations of LLMs. To fill this gap, this position paper formulates agentic workflows as computational graphs and advocates Graph Neural Networks (GNNs) as efficient predictors of agentic workflow performances, avoiding repeated LLM invocations for evaluation. To empirically ground this position, we construct FLORA-Bench, a unified platform for benchmarking GNNs for predicting agentic workflow performances. With extensive experiments, we arrive at the following conclusion: GNNs are simple yet effective predictors. This conclusion supports new applications of GNNs and a novel direction towards automating agentic workflow optimization. All codes, models, and data are available at https://github.com/youngsoul0731/Flora-Bench.
Towards Quantifying Long-Range Interactions in Graph Machine Learning: a Large Graph Dataset and a Measurement
Mar 12, 2025Long-range dependencies are critical for effective graph representation learning, yet most existing datasets focus on small graphs tailored to inductive tasks, offering limited insight into long-range interactions. Current evaluations primarily compare models employing global attention (e.g., graph transformers) with those using local neighborhood aggregation (e.g., message-passing neural networks) without a direct measurement of long-range dependency. In this work, we introduce City-Networks, a novel large-scale transductive learning dataset derived from real-world city roads. This dataset features graphs with over $10^5$ nodes and significantly larger diameters than those in existing benchmarks, naturally embodying long-range information. We annotate the graphs using an eccentricity-based approach, ensuring that the classification task inherently requires information from distant nodes. Furthermore, we propose a model-agnostic measurement based on the Jacobians of neighbors from distant hops, offering a principled quantification of long-range dependencies. Finally, we provide theoretical justifications for both our dataset design and the proposed measurement - particularly by focusing on over-smoothing and influence score dilution - which establishes a robust foundation for further exploration of long-range interactions in graph neural networks.
Heterogeneous Graph Structure Learning through the Lens of Data-generating Processes
Mar 11, 2025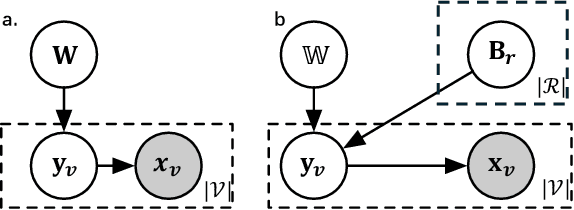



Inferring the graph structure from observed data is a key task in graph machine learning to capture the intrinsic relationship between data entities. While significant advancements have been made in learning the structure of homogeneous graphs, many real-world graphs exhibit heterogeneous patterns where nodes and edges have multiple types. This paper fills this gap by introducing the first approach for heterogeneous graph structure learning (HGSL). To this end, we first propose a novel statistical model for the data-generating process (DGP) of heterogeneous graph data, namely hidden Markov networks for heterogeneous graphs (H2MN). Then we formalize HGSL as a maximum a-posterior estimation problem parameterized by such DGP and derive an alternating optimization method to obtain a solution together with a theoretical justification of the optimization conditions. Finally, we conduct extensive experiments on both synthetic and real-world datasets to demonstrate that our proposed method excels in learning structure on heterogeneous graphs in terms of edge type identification and edge weight recovery.
Judge a Book by its Cover: Investigating Multi-Modal LLMs for Multi-Page Handwritten Document Transcription
Feb 27, 2025Handwritten text recognition (HTR) remains a challenging task, particularly for multi-page documents where pages share common formatting and contextual features. While modern optical character recognition (OCR) engines are proficient with printed text, their performance on handwriting is limited, often requiring costly labeled data for fine-tuning. In this paper, we explore the use of multi-modal large language models (MLLMs) for transcribing multi-page handwritten documents in a zero-shot setting. We investigate various configurations of commercial OCR engines and MLLMs, utilizing the latter both as end-to-end transcribers and as post-processors, with and without image components. We propose a novel method, '+first page', which enhances MLLM transcription by providing the OCR output of the entire document along with just the first page image. This approach leverages shared document features without incurring the high cost of processing all images. Experiments on a multi-page version of the IAM Handwriting Database demonstrate that '+first page' improves transcription accuracy, balances cost with performance, and even enhances results on out-of-sample text by extrapolating formatting and OCR error patterns from a single page.