 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mechanistic Analysis of Looped Reasoning Language Models
Apr 13, 2026Reasoning has become a central capability in large language models. Recent research has shown that reasoning performance can be improved by looping an LLM's layers in the latent dimension, resulting in looped reasoning language models. Despite promising results, few works have investigated how their internal dynamics differ from those of standard feedforward models. In this paper, we conduct a mechanistic analysis of the latent states in looped language models, focusing in particular on how the stages of inference observed in feedforward models compare to those observed in looped ones. To this end, we analyze cyclic recurrence and show that for many of the studied models each layer in the cycle converges to a distinct fixed point; consequently, the recurrent block follows a consistent cyclic trajectory in the latent space. We provide evidence that as these fixed points are reached, attention-head behavior stabilizes, leading to constant behavior across recurrences. Empirically, we discover that recurrent blocks learn stages of inference that closely mirror those of feedforward models, repeating these stages in depth with each iteration. We study how recurrent block size, input injection, and normalization influence the emergence and stability of these cyclic fixed points. We believe these findings help translate mechanistic insights into practical guidance for architectural design.
Return of ChebNet: Understanding and Improving an Overlooked GNN on Long Range Tasks
Jun 09, 2025ChebNet, one of the earliest spectral GNNs, has largely been overshadowed by Message Passing Neural Networks (MPNNs), which gained popularity for their simplicity and effectiveness in capturing local graph structure. Despite their success, MPNNs are limited in their ability to capture long-range dependencies between nodes. This has led researchers to adapt MPNNs through rewiring or make use of Graph Transformers, which compromises the computational efficiency that characterized early spatial message-passing architectures, and typically disregards the graph structure. Almost a decade after its original introduction, we revisit ChebNet to shed light on its ability to model distant node interactions. We find that out-of-box, ChebNet already shows competitive advantages relative to classical MPNNs and GTs on long-range benchmarks, while maintaining good scalability properties for high-order polynomials. However, we uncover that this polynomial expansion leads ChebNet to an unstable regime during training. To address this limitation, we cast ChebNet as a stable and non-dissipative dynamical system, which we coin Stable-ChebNet. Our Stable-ChebNet model allows for stable information propagation, and has controllable dynamics which do not require the use of eigendecompositions, positional encodings, or graph rewiring. Across several benchmarks, Stable-ChebNet achieves near state-of-the-art performance.
Why do LLMs attend to the first token?
Apr 03, 2025Large Language Models (LLMs) tend to attend heavily to the first token in the sequence -- creating a so-called attention sink. Many works have studied this phenomenon in detail, proposing various ways to either leverage or alleviate it. Attention sinks have been connected to quantisation difficulties, security issues, and streaming attention. Yet, while many works have provided conditions in which they occur or not, a critical question remains shallowly answered: Why do LLMs learn such patterns and how are they being used? In this work, we argue theoretically and empirically that this mechanism provides a method for LLMs to avoid over-mixing, connecting this to existing lines of work that study mathematically how information propagates in Transformers. We conduct experiments to validate our theoretical intuitions and show how choices such as context length, depth, and data packing influence the sink behaviour. We hope that this study provides a new practical perspective on why attention sinks are useful in LLMs, leading to a better understanding of the attention patterns that form during training.
Rough Transformers: Lightweight Continuous-Time Sequence Modelling with Path Signatures
May 31, 2024Time-series data in real-world settings typically exhibit long-range dependencies and are observed at non-uniform intervals. In these settings, traditional sequence-based recurrent models struggle. To overcome this, researchers often replace recurrent architectures with Neural ODE-based models to account for irregularly sampled data and use Transformer-based architectures to account for long-range dependencies. Despite the success of these two approaches, both incur very high computational costs for input sequences of even moderate length. To address this challenge, we introduce the Rough Transformer, a variation of the Transformer model that operates on continuous-time representations of input sequences and incurs significantly lower computational costs. In particular, we propose \textit{multi-view signature attention}, which uses path signatures to augment vanilla attention and to capture both local and global (multi-scale) dependencies in the input data, while remaining robust to changes in the sequence length and sampling frequency and yielding improved spatial processing. We find that, on a variety of time-series-related tasks, Rough Transformers consistently outperform their vanilla attention counterparts while obtaining the representational benefits of Neural ODE-based models, all at a fraction of the computational time and memory resources.
Rough Transformers for Continuous and Efficient Time-Series Modelling
Mar 15, 2024Time-series data in real-world medical settings typically exhibit long-range dependencies and are observed at non-uniform intervals. In such contexts, traditional sequence-based recurrent models struggle. To overcome this, researchers replace recurrent architectures with Neural ODE-based models to model irregularly sampled data and use Transformer-based architectures to account for long-range dependencies. Despite the success of these two approaches, both incur very high computational costs for input sequences of moderate lengths and greater. To mitigate this, we introduce the Rough Transformer, a variation of the Transformer model which operates on continuous-time representations of input sequences and incurs significantly reduced computational costs, critical for addressing long-range dependencies common in medical contexts. In particular, we propose multi-view signature attention, which uses path signatures to augment vanilla attention and to capture both local and global dependencies in input data, while remaining robust to changes in the sequence length and sampling frequency. We find that Rough Transformers consistently outperform their vanilla attention counterparts while obtaining the benefits of Neural ODE-based models using a fraction of the computational time and memory resources on synthetic and real-world time-series tasks.
Projections of Model Spaces for Latent Graph Inference
Mar 25, 2023
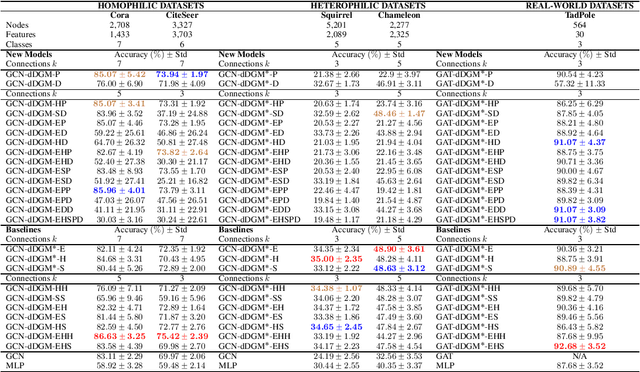
Graph Neural Networks leverage the connectivity structure of graphs as an inductive bias. Latent graph inference focuses on learning an adequate graph structure to diffuse information on and improve the downstream performance of the model. In this work we employ stereographic projections of the hyperbolic and spherical model spaces, as well as products of Riemannian manifolds, for the purpose of latent graph inference. Stereographically projected model spaces achieve comparable performance to their non-projected counterparts, while providing theoretical guarantees that avoid divergence of the spaces when the curvature tends to zero. We perform experiments on both homophilic and heterophilic graphs.