 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDE-SSM: A Spectral State Space Approach to Spatial Mixing in Diffusion Transformers
Mar 14, 2026The success of vision transformers-especially for generative modeling-is limited by the quadratic cost and weak spatial inductive bias of self-attention. We propose PDE-SSM, a spatial state-space block that replaces attention with a learnable convection-diffusion-reaction partial differential equation. This operator encodes a strong spatial prior by modeling information flow via physically grounded dynamics rather than all-to-all token interactions. Solving the PDE in the Fourier domain yields global coupling with near-linear complexity of $O(N \log N)$, delivering a principled and scalable alternative to attention. We integrate PDE-SSM into a flow-matching generative model to obtain the PDE-based Diffusion Transformer PDE-SSM-DiT. Empirically, PDE-SSM-DiT matches or exceeds the performance of state-of-the-art Diffusion Transformers while substantially reducing compute. Our results show that, analogous to 1D settings where SSMs supplant attention, multi-dimensional PDE operators provide an efficient, inductive-bias-rich foundation for next-generation vision models.
Towards Improved Sentence Representations using Token Graphs
Mar 03, 2026Obtaining a single-vector representation from a Large Language Model's (LLM) token-level outputs is a critical step for nearly all sentence-level tasks. However, standard pooling methods like mean or max aggregation treat tokens as an independent set, discarding the rich relational structure captured by the model's self-attention layers and making them susceptible to signal dilution. To address this, we introduce GLOT, a lightweight, structure-aware pooling module that reframes pooling as relational learning followed by aggregation. Operating on the outputs of a frozen LLM, GLOT first constructs a latent token-similarity graph, then refines token representations with a graph neural network, and finally aggregates them using a readout layer. Experimentally, our approach is remarkably robust and efficient: on a diagnostic stress test where 90% of tokens are random distractors, GLOT maintains over 97% accuracy while baseline methods collapse. Furthermore, it is competitive with state-of-the-art techniques on benchmarks like GLUE and MTEB with 20x fewer trainable parameters and speeds up the training time by over 100x compared with parameter-efficient fine-tuning methods. Supported by a theoretical analysis of its expressive power, our work shows that learning over token graphs is a powerful paradigm for the efficient adaptation of frozen LLMs. Our code is published at https://github.com/ipsitmantri/GLOT.
Preconditioned Score and Flow Matching
Mar 02, 2026Flow matching and score-based diffusion train vector fields under intermediate distributions $p_t$, whose geometry can strongly affect their optimization. We show that the covariance $Σ_t$ of $p_t$ governs optimization bias: when $Σ_t$ is ill-conditioned, and gradient-based training rapidly fits high-variance directions while systematically under-optimizing low-variance modes, leading to learning that plateaus at suboptimal weights. We formalize this effect in analytically tractable settings and propose reversible, label-conditional \emph{preconditioning} maps that reshape the geometry of $p_t$ by improving the conditioning of $Σ_t$ without altering the underlying generative model. Rather than accelerating early convergence, preconditioning primarily mitigates optimization stagnation by enabling continued progress along previously suppressed directions. Across MNIST latent flow matching, and additional high-resolution datasets, we empirically track conditioning diagnostics and distributional metrics and show that preconditioning consistently yields better-trained models by avoiding suboptimal plateaus.
Trajectory Stitching for Solving Inverse Problems with Flow-Based Models
Feb 09, 2026Flow-based generative models have emerged as powerful priors for solving inverse problems. One option is to directly optimize the initial latent code (noise), such that the flow output solves the inverse problem. However, this requires backpropagating through the entire generative trajectory, incurring high memory costs and numerical instability. We propose MS-Flow, which represents the trajectory as a sequence of intermediate latent states rather than a single initial code. By enforcing the flow dynamics locally and coupling segments through trajectory-matching penalties, MS-Flow alternates between updating intermediate latent states and enforcing consistency with observed data. This reduces memory consumption while improving reconstruction quality. We demonstrate the effectiveness of MS-Flow over existing methods on image recovery and inverse problems, including inpainting, super-resolution, and computed tomography.
Learning from Historical Activations in Graph Neural Networks
Jan 03, 2026Graph Neural Networks (GNNs) have demonstrated remarkable success in various domains such as social networks, molecular chemistry, and more. A crucial component of GNNs is the pooling procedure, in which the node features calculated by the model are combined to form an informative final descriptor to be used for the downstream task. However, previous graph pooling schemes rely on the last GNN layer features as an input to the pooling or classifier layers, potentially under-utilizing important activations of previous layers produced during the forward pass of the model, which we regard as historical graph activations. This gap is particularly pronounced in cases where a node's representation can shift significantly over the course of many graph neural layers, and worsened by graph-specific challenges such as over-smoothing in deep architectures. To bridge this gap, we introduce HISTOGRAPH, a novel two-stage attention-based final aggregation layer that first applies a unified layer-wise attention over intermediate activations, followed by node-wise attention. By modeling the evolution of node representations across layers, our HISTOGRAPH leverages both the activation history of nodes and the graph structure to refine features used for final prediction. Empirical results on multiple graph classification benchmarks demonstrate that HISTOGRAPH offers strong performance that consistently improves traditional techniques, with particularly strong robustness in deep GNNs.
Revisiting Node Affinity Prediction in Temporal Graphs
Oct 08, 2025Node affinity prediction is a common task that is widely used in temporal graph learning with applications in social and financial networks, recommender systems, and more. Recent works have addressed this task by adapting state-of-the-art dynamic link property prediction models to node affinity prediction. However, simple heuristics, such as Persistent Forecast or Moving Average, outperform these models. In this work, we analyze the challenges in training current Temporal Graph Neural Networks for node affinity prediction and suggest appropriate solutions. Combining the solutions, we develop NAViS - Node Affinity prediction model using Virtual State, by exploiting the equivalence between heuristics and state space models. While promising, training NAViS is non-trivial. Therefore, we further introduce a novel loss function for node affinity prediction. We evaluate NAViS on TGB and show that it outperforms the state-of-the-art, including heuristics. Our source code is available at https://github.com/orfeld415/NAVIS
TANGO: Graph Neural Dynamics via Learned Energy and Tangential Flows
Aug 07, 2025We introduce TANGO -- a dynamical systems inspired framework for graph representation learning that governs node feature evolution through a learned energy landscape and its associated descent dynamics. At the core of our approach is a learnable Lyapunov function over node embeddings, whose gradient defines an energy-reducing direction that guarantees convergence and stability. To enhance flexibility while preserving the benefits of energy-based dynamics, we incorporate a novel tangential component, learned via message passing, that evolves features while maintaining the energy value. This decomposition into orthogonal flows of energy gradient descent and tangential evolution yields a flexible form of graph dynamics, and enables effective signal propagation even in flat or ill-conditioned energy regions, that often appear in graph learning. Our method mitigates oversquashing and is compatible with different graph neural network backbones. Empirically, TANGO achieves strong performance across a diverse set of node and graph classification and regression benchmarks, demonstrating the effectiveness of jointly learned energy functions and tangential flows for graph neural networks.
Return of ChebNet: Understanding and Improving an Overlooked GNN on Long Range Tasks
Jun 09, 2025ChebNet, one of the earliest spectral GNNs, has largely been overshadowed by Message Passing Neural Networks (MPNNs), which gained popularity for their simplicity and effectiveness in capturing local graph structure. Despite their success, MPNNs are limited in their ability to capture long-range dependencies between nodes. This has led researchers to adapt MPNNs through rewiring or make use of Graph Transformers, which compromises the computational efficiency that characterized early spatial message-passing architectures, and typically disregards the graph structure. Almost a decade after its original introduction, we revisit ChebNet to shed light on its ability to model distant node interactions. We find that out-of-box, ChebNet already shows competitive advantages relative to classical MPNNs and GTs on long-range benchmarks, while maintaining good scalability properties for high-order polynomials. However, we uncover that this polynomial expansion leads ChebNet to an unstable regime during training. To address this limitation, we cast ChebNet as a stable and non-dissipative dynamical system, which we coin Stable-ChebNet. Our Stable-ChebNet model allows for stable information propagation, and has controllable dynamics which do not require the use of eigendecompositions, positional encodings, or graph rewiring. Across several benchmarks, Stable-ChebNet achieves near state-of-the-art performance.
Graph Flow Matching: Enhancing Image Generation with Neighbor-Aware Flow Fields
May 30, 2025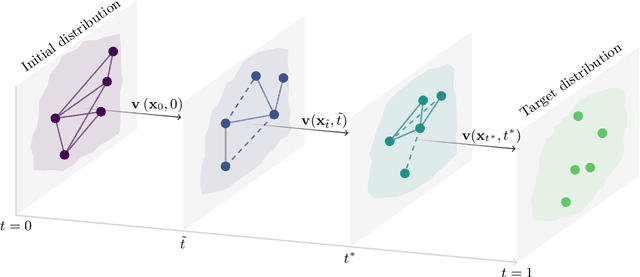
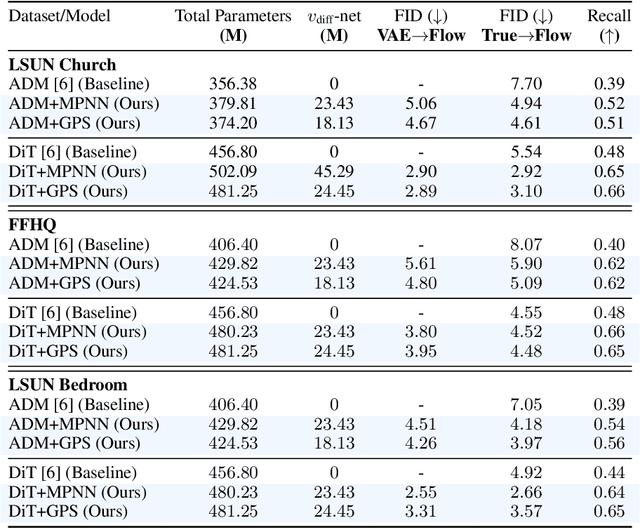

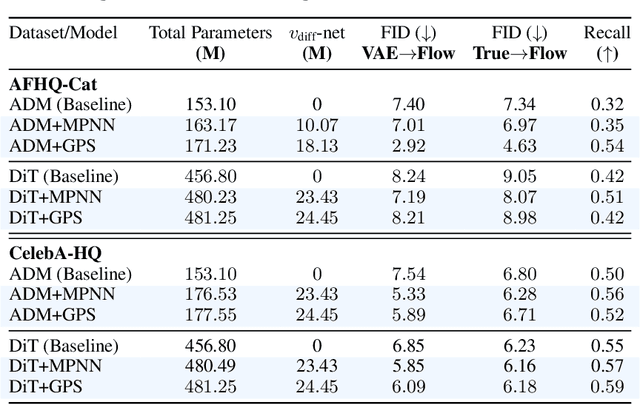
Flow matching casts sample generation as learning a continuous-time velocity field that transports noise to data. Existing flow matching networks typically predict each point's velocity independently, considering only its location and time along its flow trajectory, and ignoring neighboring points. However, this pointwise approach may overlook correlations between points along the generation trajectory that could enhance velocity predictions, thereby improving downstream generation quality. To address this, we propose Graph Flow Matching (GFM), a lightweight enhancement that decomposes the learned velocity into a reaction term -- any standard flow matching network -- and a diffusion term that aggregates neighbor information via a graph neural module. This reaction-diffusion formulation retains the scalability of deep flow models while enriching velocity predictions with local context, all at minimal additional computational cost. Operating in the latent space of a pretrained variational autoencoder, GFM consistently improves Fr\'echet Inception Distance (FID) and recall across five image generation benchmarks (LSUN Church, LSUN Bedroom, FFHQ, AFHQ-Cat, and CelebA-HQ at $256\times256$), demonstrating its effectiveness as a modular enhancement to existing flow matching architectures.
Improving the Effective Receptive Field of Message-Passing Neural Networks
May 29, 2025Message-Passing Neural Networks (MPNNs) have become a cornerstone for processing and analyzing graph-structured data. However, their effectiveness is often hindered by phenomena such as over-squashing, where long-range dependencies or interactions are inadequately captured and expressed in the MPNN output. This limitation mirrors the challenges of the Effective Receptive Field (ERF) in Convolutional Neural Networks (CNNs), where the theoretical receptive field is underutilized in practice. In this work, we show and theoretically explain the limited ERF problem in MPNNs. Furthermore, inspired by recent advances in ERF augmentation for CNNs, we propose an Interleaved Multiscale Message-Passing Neural Networks (IM-MPNN) architecture to address these problems in MPNNs. Our method incorporates a hierarchical coarsening of the graph, enabling message-passing across multiscale representations and facilitating long-range interactions without excessive depth or parameterization. Through extensive evaluations on benchmarks such as the Long-Range Graph Benchmark (LRGB), we demonstrate substantial improvements over baseline MPNNs in capturing long-range dependencies while maintaining computational efficiency.