 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Processes on Implicit Manifolds
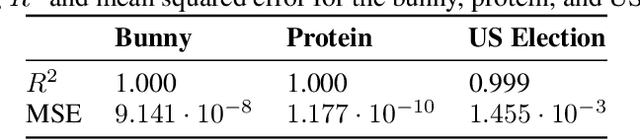
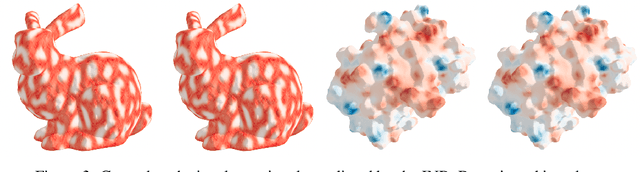
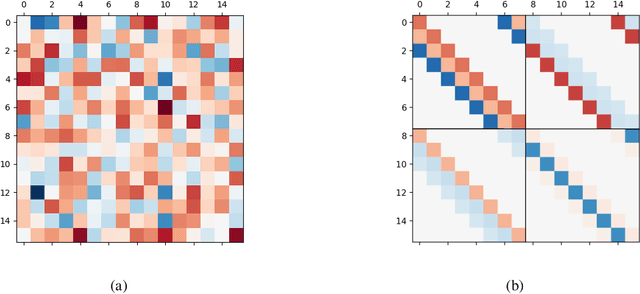
Apr 08, 2026High-dimensional data are often modeled as lying near a low-dimensional manifold. We study how to construct diffusion processes on this data manifold in the implicit setting. That is, using only point cloud samples and without access to charts, projections, or other geometric primitives. Our main contribution is a data-driven SDE that captures intrinsic diffusion on the underlying manifold while being defined in ambient space. The construction relies on estimating the diffusion's infinitesimal generator and its carré-du-champ (CDC) from a proximity graph built from the data. The generator and CDC together encode the local stochastic and geometric structure of the intended diffusion. We show that, as the number of samples grows, the induced process converges in law on the space of probability paths to its smooth manifold counterpart. We call this construction Implicit Manifold-valued Diffusions (IMDs), and furthermore present a numerical simulation procedure using Euler-Maruyama integration. This gives a rigorous basis for practical implementations of diffusion dynamics on data manifolds, and opens new directions for manifold-aware sampling, exploration, and generative modeling.
Position: Message-passing and spectral GNNs are two sides of the same coin
Feb 10, 2026Graph neural networks (GNNs) are commonly divided into message-passing neural networks (MPNNs) and spectral graph neural networks, reflecting two largely separate research traditions in machine learning and signal processing. This paper argues that this divide is mostly artificial, hindering progress in the field. We propose a viewpoint in which both MPNNs and spectral GNNs are understood as different parametrizations of permutation-equivariant operators acting on graph signals. From this perspective, many popular architectures are equivalent in expressive power, while genuine gaps arise only in specific regimes. We further argue that MPNNs and spectral GNNs offer complementary strengths. That is, MPNNs provide a natural language for discrete structure and expressivity analysis using tools from logic and graph isomorphism research, while the spectral perspective provides principled tools for understanding smoothing, bottlenecks, stability, and community structure. Overall, we posit that progress in graph learning will be accelerated by clearly understanding the key similarities and differences between these two types of GNNs, and by working towards unifying these perspectives within a common theoretical and conceptual framework rather than treating them as competing paradigms.
All-Atom GPCR-Ligand Simulation via Residual Isometric Latent Flow
Feb 03, 2026G-protein-coupled receptors (GPCRs), primary targets for over one-third of approved therapeutics, rely on intricate conformational transitions to transduce signals. While Molecular Dynamics (MD) is essential for elucidating this transduction process, particularly within ligand-bound complexes, conventional all-atom MD simulation is computationally prohibitive. In this paper, we introduce GPCRLMD, a deep generative framework for efficient all-atom GPCR-ligand simulation.GPCRLMD employs a Harmonic-Prior Variational Autoencoder (HP-VAE) to first map the complex into a regularized isometric latent space, preserving geometric topology via physics-informed constraints. Within this latent space, a Residual Latent Flow samples evolution trajectories, which are subsequently decoded back to atomic coordinates. By capturing temporal dynamics via relative displacements anchored to the initial structure, this residual mechanism effectively decouples static topology from dynamic fluctuations. Experimental results demonstrate that GPCRLMD achieves state-of-the-art performance in GPCR-ligand dynamics simulation, faithfully reproducing thermodynamic observables and critical ligand-receptor interactions.
MEIDNet: Multimodal generative AI framework for inverse materials design
Jan 29, 2026In this work, we present Multimodal Equivariant Inverse Design Network (MEIDNet), a framework that jointly learns structural information and materials properties through contrastive learning, while encoding structures via an equivariant graph neural network (EGNN). By combining generative inverse design with multimodal learning, our approach accelerates the exploration of chemical-structural space and facilitates the discovery of materials that satisfy predefined property targets. MEIDNet exhibits strong latent-space alignment with cosine similarity 0.96 by fusion of three modalities through cross-modal learning. Through implementation of curriculum learning strategies, MEIDNet achieves ~60 times higher learning efficiency than conventional training techniques. The potential of our multimodal approach is demonstrated by generating low-bandgap perovskite structures at a stable, unique, and novel (SUN) rate of 13.6 %, which are further validated by ab initio methods. Our inverse design framework demonstrates both scalability and adaptability, paving the way for the universal learning of chemical space across diverse modalities.
Return of ChebNet: Understanding and Improving an Overlooked GNN on Long Range Tasks
Jun 09, 2025ChebNet, one of the earliest spectral GNNs, has largely been overshadowed by Message Passing Neural Networks (MPNNs), which gained popularity for their simplicity and effectiveness in capturing local graph structure. Despite their success, MPNNs are limited in their ability to capture long-range dependencies between nodes. This has led researchers to adapt MPNNs through rewiring or make use of Graph Transformers, which compromises the computational efficiency that characterized early spatial message-passing architectures, and typically disregards the graph structure. Almost a decade after its original introduction, we revisit ChebNet to shed light on its ability to model distant node interactions. We find that out-of-box, ChebNet already shows competitive advantages relative to classical MPNNs and GTs on long-range benchmarks, while maintaining good scalability properties for high-order polynomials. However, we uncover that this polynomial expansion leads ChebNet to an unstable regime during training. To address this limitation, we cast ChebNet as a stable and non-dissipative dynamical system, which we coin Stable-ChebNet. Our Stable-ChebNet model allows for stable information propagation, and has controllable dynamics which do not require the use of eigendecompositions, positional encodings, or graph rewiring. Across several benchmarks, Stable-ChebNet achieves near state-of-the-art performance.
Implicit Gaussian process representation of vector fields over arbitrary latent manifolds
Sep 28, 2023Gaussian processes (GPs) are popular nonparametric statistical models for learning unknown functions and quantifying the spatiotemporal uncertainty in data. Recent works have extended GPs to model scalar and vector quantities distributed over non-Euclidean domains, including smooth manifolds appearing in numerous fields such as computer vision, dynamical systems, and neuroscience. However, these approaches assume that the manifold underlying the data is known, limiting their practical utility. We introduce RVGP, a generalisation of GPs for learning vector signals over latent Riemannian manifolds. Our method uses positional encoding with eigenfunctions of the connection Laplacian, associated with the tangent bundle, readily derived from common graph-based approximation of data. We demonstrate that RVGP possesses global regularity over the manifold, which allows it to super-resolve and inpaint vector fields while preserving singularities. Furthermore, we use RVGP to reconstruct high-density neural dynamics derived from low-density EEG recordings in healthy individuals and Alzheimer's patients. We show that vector field singularities are important disease markers and that their reconstruction leads to a comparable classification accuracy of disease states to high-density recordings. Thus, our method overcomes a significant practical limitation in experimental and clinical applications.
Interpretable statistical representations of neural population dynamics and geometry
Apr 06, 2023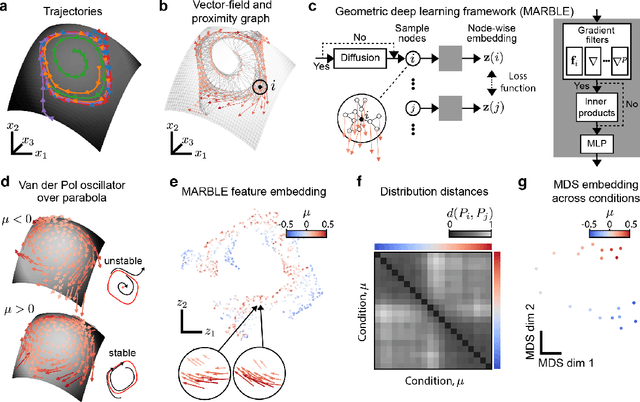

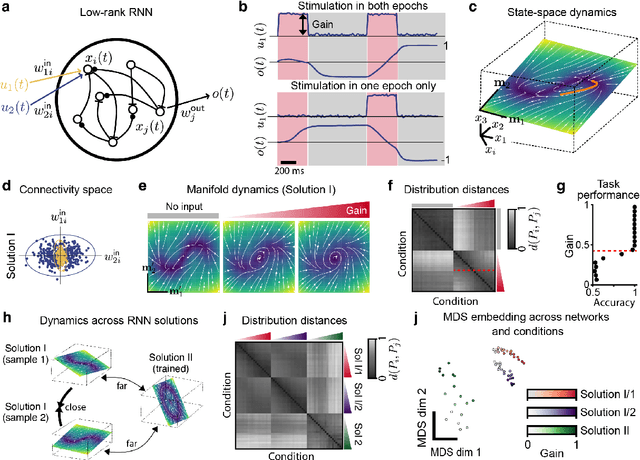
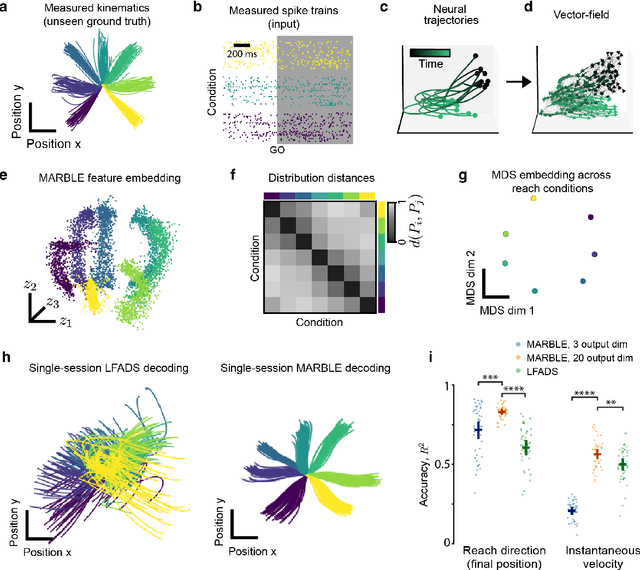
The dynamics of neuron populations during diverse tasks often evolve on low-dimensional manifolds. However, it remains challenging to discern the contributions of geometry and dynamics for encoding relevant behavioural variables. Here, we introduce an unsupervised geometric deep learning framework for representing non-linear dynamical systems based on statistical distributions of local phase portrait features. Our method provides robust geometry-aware or geometry-agnostic representations for the unbiased comparison of dynamics based on measured trajectories. We demonstrate that our statistical representation can generalise across neural network instances to discriminate computational mechanisms, obtain interpretable embeddings of neural dynamics in a primate reaching task with geometric correspondence to hand kinematics, and develop a decoding algorithm with state-of-the-art accuracy. Our results highlight the importance of using the intrinsic manifold structure over temporal information to develop better decoding algorithms and assimilate data across experiments.
Generalised Implicit Neural Representations
May 31, 2022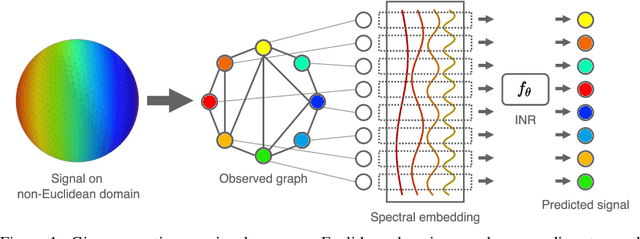
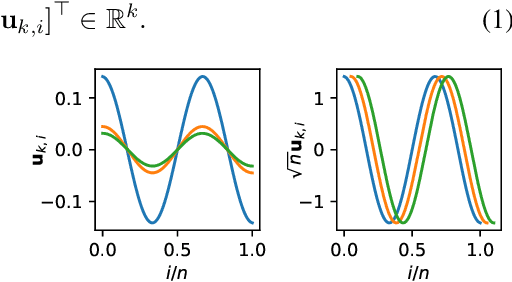
We consider the problem of learning implicit neural representations (INRs) for signals on non-Euclidean domains. In the Euclidean case, INRs are trained on a discrete sampling of a signal over a regular lattice. Here, we assume that the continuous signal exists on some unknown topological space from which we sample a discrete graph. In the absence of a coordinate system to identify the sampled nodes, we propose approximating their location with a spectral embedding of the graph. This allows us to train INRs without knowing the underlying continuous domain, which is the case for most graph signals in nature, while also making the INRs equivariant under the symmetry group of the domain. We show experiments with our method on various real-world signals on non-Euclidean domains.
Some limitations of norm based generalization bounds in deep neural networks
May 23, 2019

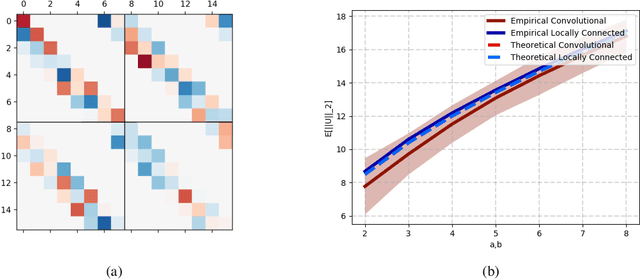
Deep convolutional neural networks have been shown to be able to fit a labeling over random data while still being able to generalize well on normal datasets. Describing deep convolutional neural network capacity through the measure of spectral complexity has been recently proposed to tackle this apparent paradox. Spectral complexity correlates with GE and can distinguish networks trained on normal and random labels. We propose the first GE bound based on spectral complexity for deep convolutional neural networks and provide tighter bounds by orders of magnitude from the previous estimate. We then investigate theoretically and empirically the insensitivity of spectral complexity to invariances of modern deep convolutional neural networks, and show several limitations of spectral complexity that occur as a result.
Revisiting hard thresholding for DNN pruning
May 21, 2019

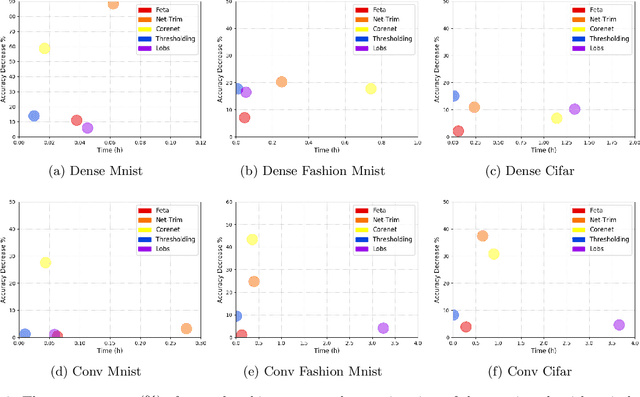
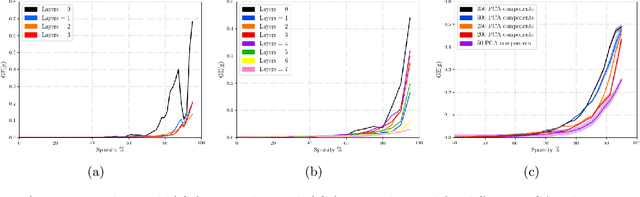
The most common method for DNN pruning is hard thresholding of network weights, followed by retraining to recover any lost accuracy. Recently developed smart pruning algorithms use the DNN response over the training set for a variety of cost functions to determine redundant network weights, leading to less accuracy degradation and possibly less retraining time. For experiments on the total pruning time (pruning time + retraining time) we show that hard thresholding followed by retraining remains the most efficient way of reducing the number of network parameters. However smart pruning algorithms still have advantages when retraining is not possible. In this context we propose a novel smart pruning algorithm based on difference of convex functions optimisation and show that it is often orders of magnitude faster than competing approaches while achieving the lowest classification accuracy degradation. Furthermore we investigate theoretically the effect of hard thresholding on DNN accuracy. We show that accuracy degradation increases with remaining network depth from the pruned layer. We also discover a link between the latent dimensionality of the training data manifold and network robustness to hard thresholding.