 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Tractogram Filtering using Geometric Deep Learning
Dec 06, 2022



A tractogram is a virtual representation of the brain white matter. It is composed of millions of virtual fibers, encoded as 3D polylines, which approximate the white matter axonal pathways. To date, tractograms are the most accurate white matter representation and thus are used for tasks like presurgical planning and investigations of neuroplasticity, brain disorders, or brain networks. However, it is a well-known issue that a large portion of tractogram fibers is not anatomically plausible and can be considered artifacts of the tracking procedure. With Verifyber, we tackle the problem of filtering out such non-plausible fibers using a novel fully-supervised learning approach. Differently from other approaches based on signal reconstruction and/or brain topology regularization, we guide our method with the existing anatomical knowledge of the white matter. Using tractograms annotated according to anatomical principles, we train our model, Verifyber, to classify fibers as either anatomically plausible or non-plausible. The proposed Verifyber model is an original Geometric Deep Learning method that can deal with variable size fibers, while being invariant to fiber orientation. Our model considers each fiber as a graph of points, and by learning features of the edges between consecutive points via the proposed sequence Edge Convolution, it can capture the underlying anatomical properties. The output filtering results highly accurate and robust across an extensive set of experiments, and fast; with a 12GB GPU, filtering a tractogram of 1M fibers requires less than a minute. Verifyber implementation and trained models are available at https://github.com/FBK-NILab/verifyber.
Automatic design of novel potential 3CL$^{\text{pro}}$ and PL$^{\text{pro}}$ inhibitors
Jan 29, 2021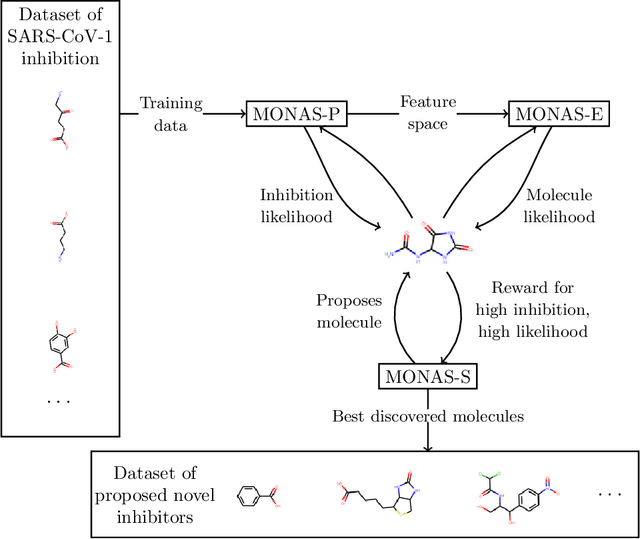
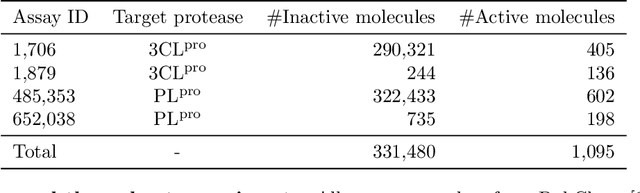
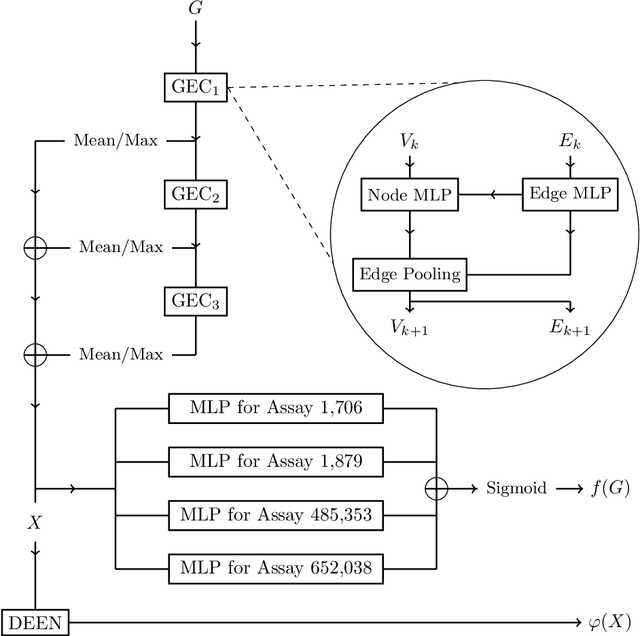
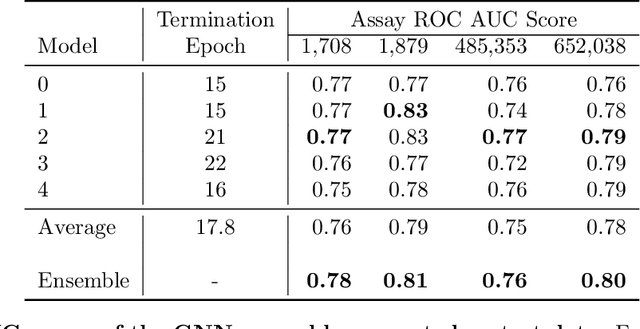
With the goal of designing novel inhibitors for SARS-CoV-1 and SARS-CoV-2, we propose the general molecule optimization framework, Molecular Neural Assay Search (MONAS), consisting of three components: a property predictor which identifies molecules with specific desirable properties, an energy model which approximates the statistical similarity of a given molecule to known training molecules, and a molecule search method. In this work, these components are instantiated with graph neural networks (GNNs), Deep Energy Estimator Networks (DEEN) and Monte Carlo tree search (MCTS), respectively. This implementation is used to identify 120K molecules (out of 40-million explored) which the GNN determined to be likely SARS-CoV-1 inhibitors, and, at the same time, are statistically close to the dataset used to train the GNN.
Learning to Detect Objects with a 1 Megapixel Event Camera
Sep 28, 2020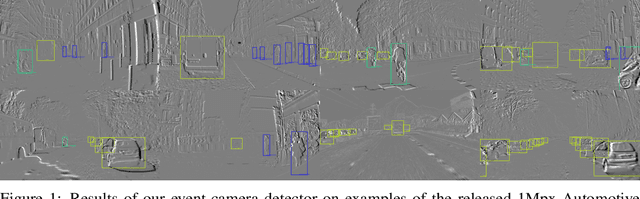

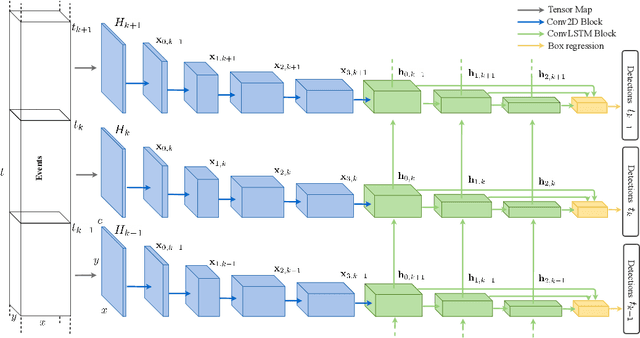
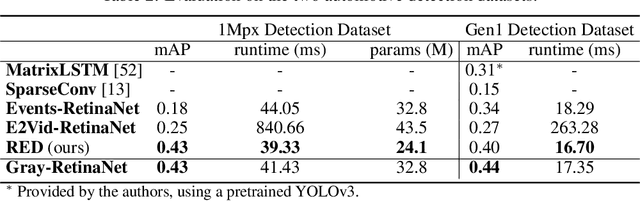
Event cameras encode visual information with high temporal precision, low data-rate, and high-dynamic range. Thanks to these characteristics, event cameras are particularly suited for scenarios with high motion, challenging lighting conditions and requiring low latency. However, due to the novelty of the field, the performance of event-based systems on many vision tasks is still lower compared to conventional frame-based solutions. The main reasons for this performance gap are: the lower spatial resolution of event sensors, compared to frame cameras; the lack of large-scale training datasets; the absence of well established deep learning architectures for event-based processing. In this paper, we address all these problems in the context of an event-based object detection task. First, we publicly release the first high-resolution large-scale dataset for object detection. The dataset contains more than 14 hours recordings of a 1 megapixel event camera, in automotive scenarios, together with 25M bounding boxes of cars, pedestrians, and two-wheelers, labeled at high frequency. Second, we introduce a novel recurrent architecture for event-based detection and a temporal consistency loss for better-behaved training. The ability to compactly represent the sequence of events into the internal memory of the model is essential to achieve high accuracy. Our model outperforms by a large margin feed-forward event-based architectures. Moreover, our method does not require any reconstruction of intensity images from events, showing that training directly from raw events is possible, more efficient, and more accurate than passing through an intermediate intensity image. Experiments on the dataset introduced in this work, for which events and gray level images are available, show performance on par with that of highly tuned and studied frame-based detectors.
Real-time Classification from Short Event-Camera Streams using Input-filtering Neural ODEs
Apr 07, 2020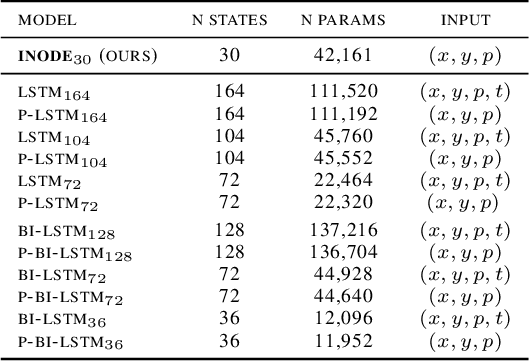


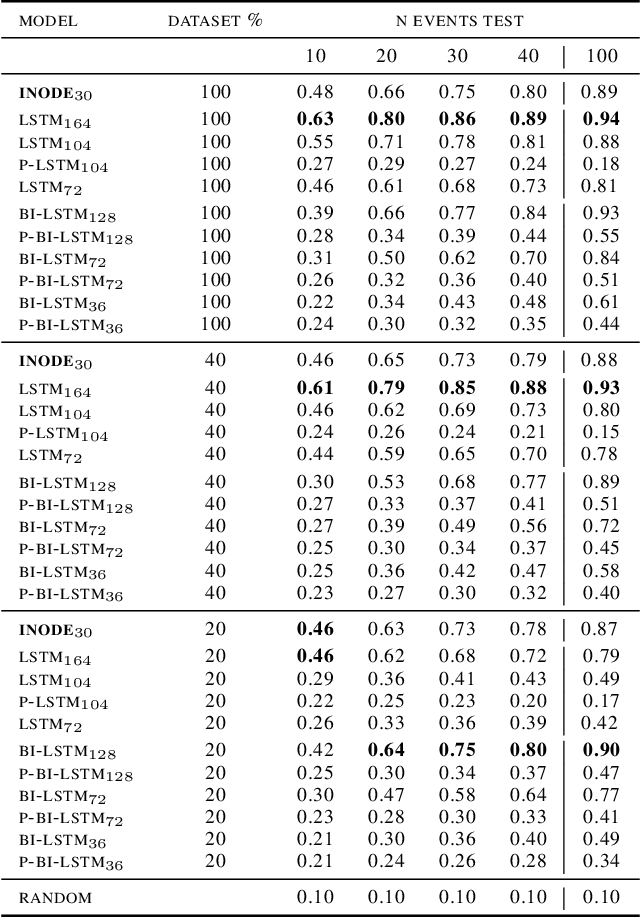
Event-based cameras are novel, efficient sensors inspired by the human vision system, generating an asynchronous, pixel-wise stream of data. Learning from such data is generally performed through heavy preprocessing and event integration into images. This requires buffering of possibly long sequences and can limit the response time of the inference system. In this work, we instead propose to directly use events from a DVS camera, a stream of intensity changes and their spatial coordinates. This sequence is used as the input for a novel \emph{asynchronous} RNN-like architecture, the Input-filtering Neural ODEs (INODE). This is inspired by the dynamical systems and filtering literature. INODE is an extension of Neural ODEs (NODE) that allows for input signals to be continuously fed to the network, like in filtering. The approach naturally handles batches of time series with irregular time-stamps by implementing a batch forward Euler solver. INODE is trained like a standard RNN, it learns to discriminate short event sequences and to perform event-by-event online inference. We demonstrate our approach on a series of classification tasks, comparing against a set of LSTM baselines. We show that, independently of the camera resolution, INODE can outperform the baselines by a large margin on the ASL task and it's on par with a much larger LSTM for the NCALTECH task. Finally, we show that INODE is accurate even when provided with very few events.
Tractogram filtering of anatomically non-plausible fibers with geometric deep learning
Mar 24, 2020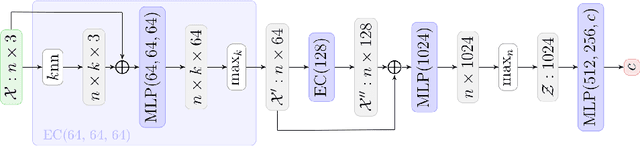
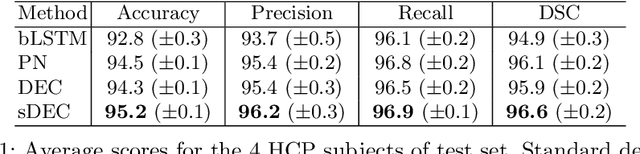
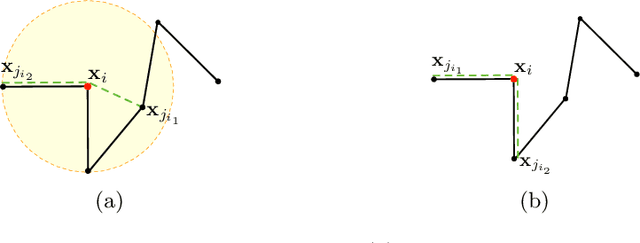
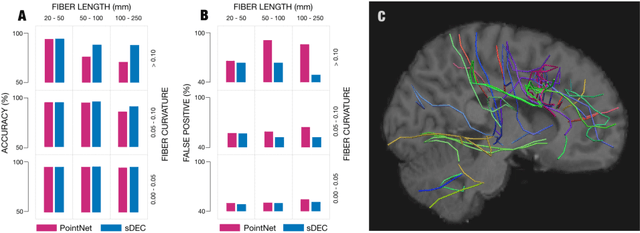
Tractograms are virtual representations of the white matter fibers of the brain. They are of primary interest for tasks like presurgical planning, and investigation of neuroplasticity or brain disorders. Each tractogram is composed of millions of fibers encoded as 3D polylines. Unfortunately, a large portion of those fibers are not anatomically plausible and can be considered artifacts of the tracking algorithms. Common methods for tractogram filtering are based on signal reconstruction, a principled approach, but unable to consider the knowledge of brain anatomy. In this work, we address the problem of tractogram filtering as a supervised learning problem by exploiting the ground truth annotations obtained with a recent heuristic method, which labels fibers as either anatomically plausible or non-plausible according to well-established anatomical properties. The intuitive idea is to model a fiber as a point cloud and the goal is to investigate whether and how a geometric deep learning model might capture its anatomical properties. Our contribution is an extension of the Dynamic Edge Convolution model that exploits the sequential relations of points in a fiber and discriminates with high accuracy plausible/non-plausible fibers.
Deep Graph Matching Consensus
Jan 27, 2020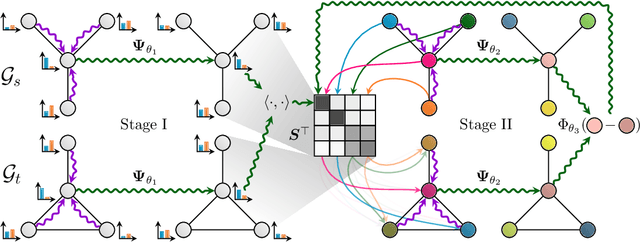
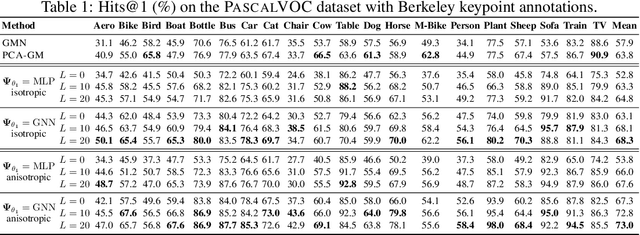
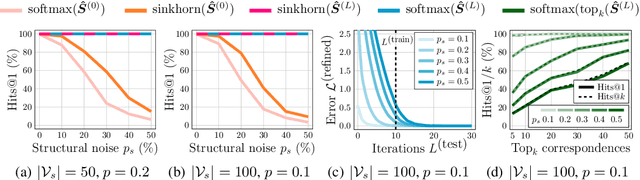
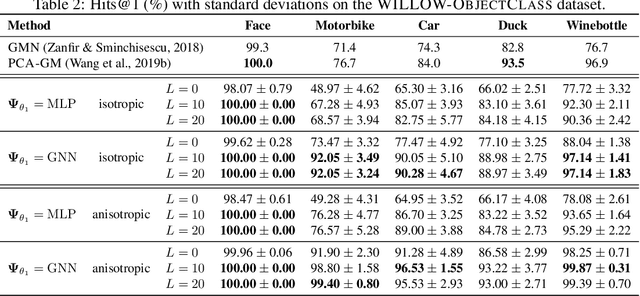
This work presents a two-stage neural architecture for learning and refining structural correspondences between graphs. First, we use localized node embeddings computed by a graph neural network to obtain an initial ranking of soft correspondences between nodes. Secondly, we employ synchronous message passing networks to iteratively re-rank the soft correspondences to reach a matching consensus in local neighborhoods between graphs. We show, theoretically and empirically, that our message passing scheme computes a well-founded measure of consensus for corresponding neighborhoods, which is then used to guide the iterative re-ranking process. Our purely local and sparsity-aware architecture scales well to large, real-world inputs while still being able to recover global correspondences consistently. We demonstrate the practical effectiveness of our method on real-world tasks from the fields of computer vision and entity alignment between knowledge graphs, on which we improve upon the current state-of-the-art. Our source code is available under https://github.com/rusty1s/ deep-graph-matching-consensus.
Infinite-Horizon Differentiable Model Predictive Control
Jan 07, 2020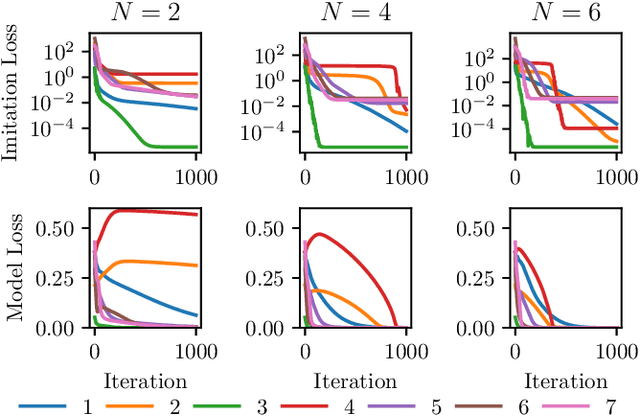
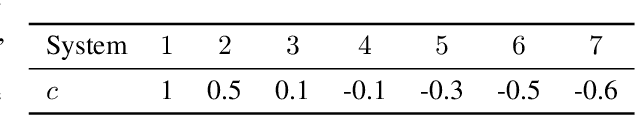

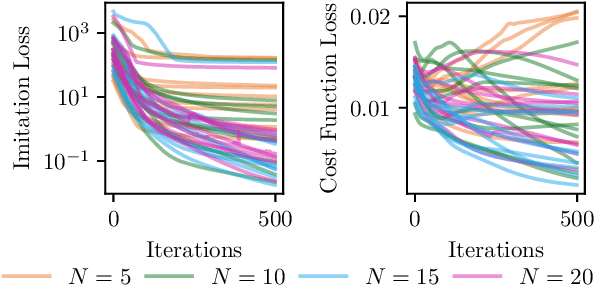
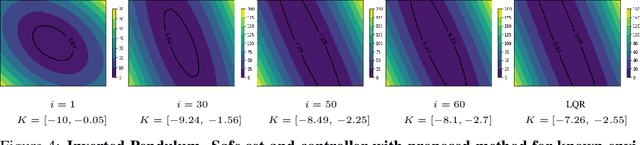
This paper proposes a differentiable linear quadratic Model Predictive Control (MPC) framework for safe imitation learning. The infinite-horizon cost is enforced using a terminal cost function obtained from the discrete-time algebraic Riccati equation (DARE), so that the learned controller can be proven to be stabilizing in closed-loop. A central contribution is the derivation of the analytical derivative of the solution of the DARE, thereby allowing the use of differentiation-based learning methods. A further contribution is the structure of the MPC optimization problem: an augmented Lagrangian method ensures that the MPC optimization is feasible throughout training whilst enforcing hard constraints on state and input, and a pre-stabilizing controller ensures that the MPC solution and derivatives are accurate at each iteration. The learning capabilities of the framework are demonstrated in a set of numerical studies.
No Representation without Transformation
Dec 09, 2019
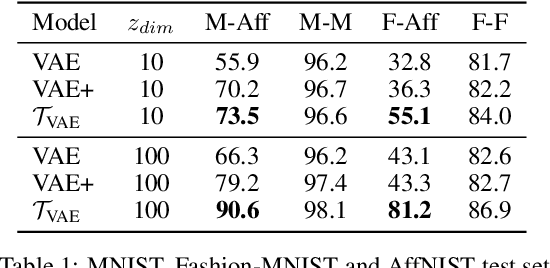
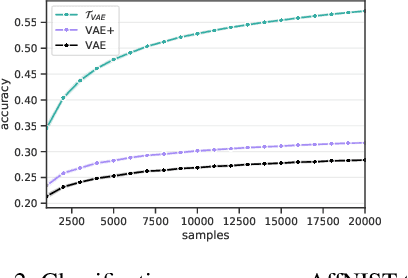

We propose to extend Latent Variable Models with a simple idea: learn to encode not only samples but also transformations of such samples. This means that the latent space is not only populated by embeddings but also by higher order objects that map between these embeddings. We show how a hierarchical graphical model can be utilized to enforce desirable algebraic properties of such latent mappings. These mappings in turn structure the latent space and hence can have a core impact on downstream tasks that are solved in the latent space. We demonstrate this impact on a set of experiments and also show that the representation of these latent mappings reflects interpretable properties.
Safe Interactive Model-Based Learning
Nov 18, 2019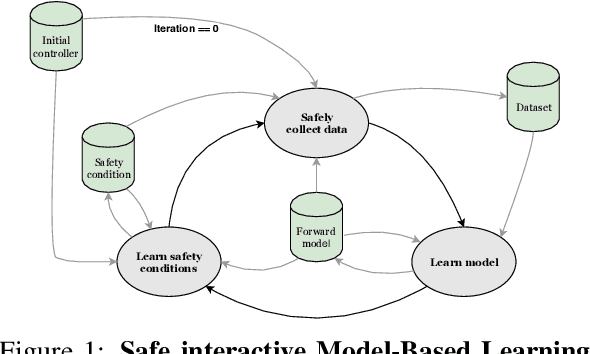
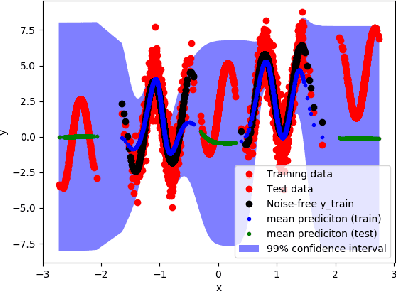
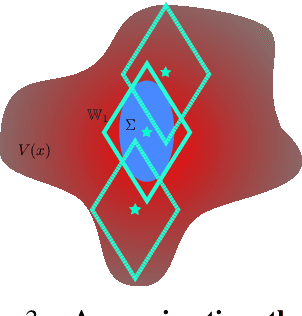
Control applications present hard operational constraints. A violation of these can result in unsafe behavior. This paper introduces Safe Interactive Model Based Learning (SiMBL), a framework to refine an existing controller and a system model while operating on the real environment. SiMBL is composed of the following trainable components: a Lyapunov function, which determines a safe set; a safe control policy; and a Bayesian RNN forward model. A min-max control framework, based on alternate minimisation and backpropagation through the forward model, is used for the offline computation of the controller and the safe set. Safety is formally verified a-posteriori with a probabilistic method that utilizes the Noise Contrastive Priors (NPC) idea to build a Bayesian RNN forward model with an additive state uncertainty estimate which is large outside the training data distribution. Iterative refinement of the model and the safe set is achieved thanks to a novel loss that conditions the uncertainty estimates of the new model to be close to the current one. The learned safe set and model can also be used for safe exploration, i.e., to collect data within the safe invariant set, for which a simple one-step MPC is proposed. The single components are tested on the simulation of an inverted pendulum with limited torque and stability region, showing that iteratively adding more data can improve the model, the controller and the size of the safe region.
Accelerating Neural ODEs with Spectral Elements
Jun 17, 2019
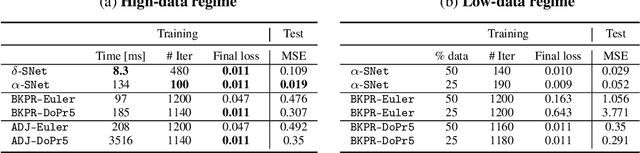
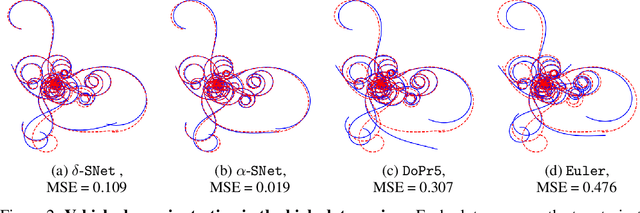

This paper proposes the use of spectral element methods \citep{canuto_spectral_1988} for fast and accurate training of Neural Ordinary Differential Equations (ODE-Nets; \citealp{Chen2018NeuralOD}). This is achieved by expressing their dynamics as truncated series of Legendre polynomials. The series coefficients, as well as the network weights, are computed by minimizing the weighted sum of the loss function and the violation of the ODE-Net dynamics. The problem is solved by coordinate descent that alternately minimizes, with respect to the coefficients and the weights, two unconstrained sub-problems using standard backpropagation and gradient methods. The resulting optimization scheme is fully time-parallel and results in a low memory footprint. Experimental comparison to standard methods, such as backpropagation through explicit solvers and the adjoint technique \citep{Chen2018NeuralOD}, on training surrogate models of small and medium-scale dynamical systems shows that it is at least one order of magnitude faster at reaching a comparable value of the loss function. The corresponding testing MSE is one order of magnitude smaller as well, suggesting generalization capabilities increase.