 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Real-time Classification from Short Event-Camera Streams using Input-filtering Neural ODEs
Apr 07, 2020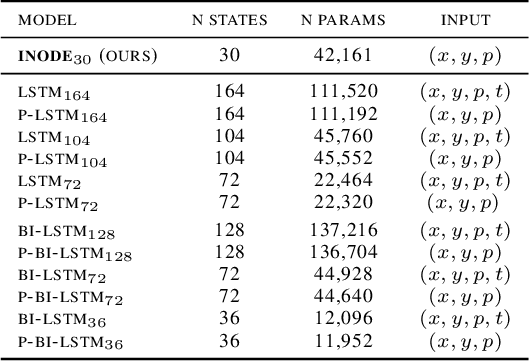


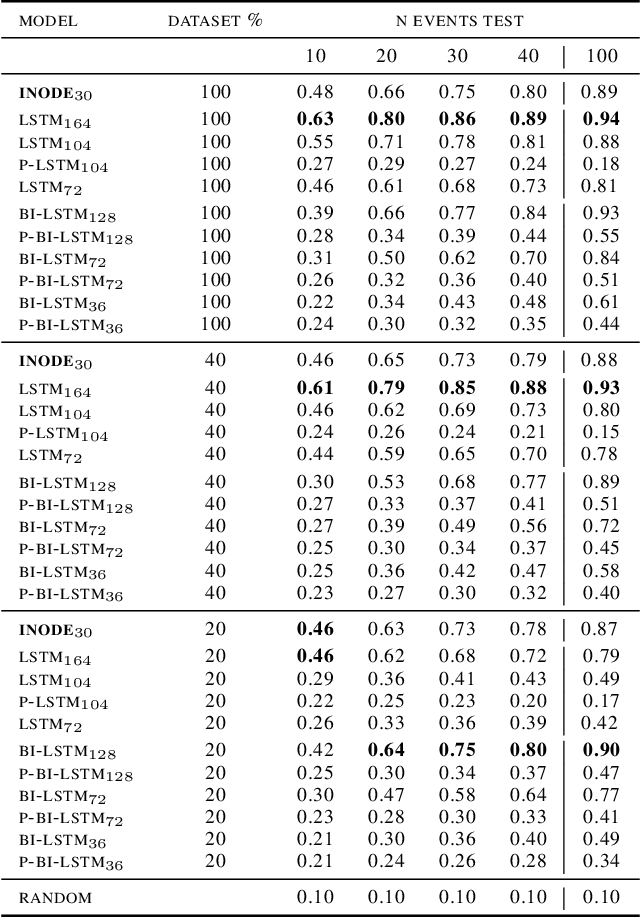
Event-based cameras are novel, efficient sensors inspired by the human vision system, generating an asynchronous, pixel-wise stream of data. Learning from such data is generally performed through heavy preprocessing and event integration into images. This requires buffering of possibly long sequences and can limit the response time of the inference system. In this work, we instead propose to directly use events from a DVS camera, a stream of intensity changes and their spatial coordinates. This sequence is used as the input for a novel \emph{asynchronous} RNN-like architecture, the Input-filtering Neural ODEs (INODE). This is inspired by the dynamical systems and filtering literature. INODE is an extension of Neural ODEs (NODE) that allows for input signals to be continuously fed to the network, like in filtering. The approach naturally handles batches of time series with irregular time-stamps by implementing a batch forward Euler solver. INODE is trained like a standard RNN, it learns to discriminate short event sequences and to perform event-by-event online inference. We demonstrate our approach on a series of classification tasks, comparing against a set of LSTM baselines. We show that, independently of the camera resolution, INODE can outperform the baselines by a large margin on the ASL task and it's on par with a much larger LSTM for the NCALTECH task. Finally, we show that INODE is accurate even when provided with very few events.
Conditional Neural Style Transfer with Peer-Regularized Feature Transform
Jun 10, 2019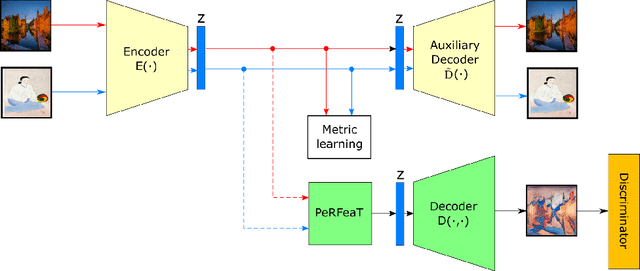
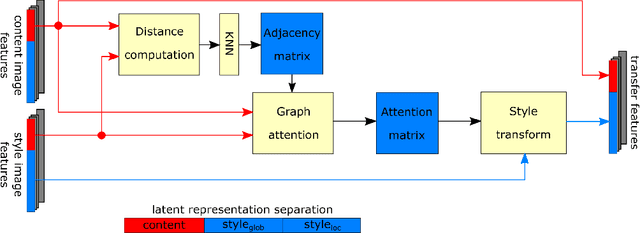


This paper introduces a neural style transfer model to conditionally generate a stylized image using only a set of examples describing the desired style. The proposed solution produces high-quality images even in the zero-shot setting and allows for greater freedom in changing the content geometry. This is thanks to the introduction of a novel Peer-Regularization Layer that recomposes style in latent space by means of a custom graph convolutional layer aiming at separating style and content. Contrary to the vast majority of existing solutions our model does not require any pre-trained network for computing perceptual losses and can be trained fully end-to-end with a new set of cyclic losses that operate directly in latent space. An extensive ablation study confirms the usefulness of the proposed losses and of the Peer-Regularization Layer, with qualitative results that are competitive with respect to the current state-of-the-art even in the challenging zero-shot setting. This opens the door to more abstract and artistic neural image generation scenarios and easier deployment of the model in. production
Night-to-Day Image Translation for Retrieval-based Localization
Sep 26, 2018


Visual localization is a key step in many robotics pipelines, allowing the robot to approximately determine its position and orientation in the world. An efficient and scalable approach to visual localization is to use image retrieval techniques. These approaches identify the image most similar to a query photo in a database of geo-tagged images and approximate the query's pose via the pose of the retrieved database image. However, image retrieval across drastically different illumination conditions, e.g. day and night, is still a problem with unsatisfactory results, even in this age of powerful neural models. This is due to a lack of a suitably diverse dataset with true correspondences to perform end-to-end learning. A recent class of neural models allows for realistic translation of images among visual domains with relatively little training data and, most importantly, without ground-truth pairings. In this paper, we explore the task of accurately localizing images captured from two traversals of the same area in both day and night. We propose ToDayGAN - a modified image-translation model to alter nighttime driving images to a more-useful daytime representation. We then compare the daytime and translated-night images to obtain a pose estimate for the night image using the known 6-DOF position of the closest day image. Our approach improves localization performance by over 250% compared the current state-of-the-art, in the context of standard metrics in multiple categories.
ComboGAN: Unrestrained Scalability for Image Domain Translation
Dec 19, 2017
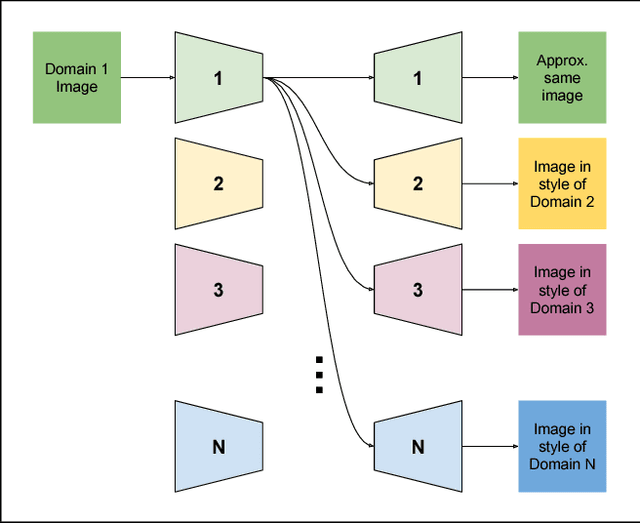

This year alone has seen unprecedented leaps in the area of learning-based image translation, namely CycleGAN, by Zhu et al. But experiments so far have been tailored to merely two domains at a time, and scaling them to more would require an quadratic number of models to be trained. And with two-domain models taking days to train on current hardware, the number of domains quickly becomes limited by the time and resources required to process them. In this paper, we propose a multi-component image translation model and training scheme which scales linearly - both in resource consumption and time required - with the number of domains. We demonstrate its capabilities on a dataset of paintings by 14 different artists and on images of the four different seasons in the Alps. Note that 14 data groups would need (14 choose 2) = 91 different CycleGAN models: a total of 182 generator/discriminator pairs; whereas our model requires only 14 generator/discriminator pairs.