 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesGPO: Trading Inference FLOPs for Training Efficiency in RLVR
Jun 07, 2026Standard Reinforcement Learning with Verifiable Rewards (RLVR) training allocates a fixed rollout budget to every query, without regard for what each query's difficulty means for the current policy. This leads to two symmetric failure modes: easy queries produce near-zero advantage because the policy already solves them, while unsolvable queries produce no signal because the policy never solves them. Both regimes waste training FLOPs without contributing to a learning gradient. We introduce sorted Group Policy Optimization (sGPO), a compute-efficient strategy that trades a small budget of inference FLOPs for a large reduction in wasted training FLOPs. The key insight is that cheap inference compute can serve as a single offline proxy for query difficulty. By generating a small batch of parallel samples per query under the initial policy, we obtain a model-aware empirical success rate. This motivates setting the training rollout group size to the inverse of this success rate, a practical rule that maximizes sample efficiency by extracting the most advantage per generated rollout. This single profiling pass simultaneously drives data filtering (removing trivial queries and sub-sampling unsolvable ones), adaptive group size allocation, and curriculum construction (scheduling queries from easy to hard). sGPO matches or exceeds baseline performance while reducing total training compute by a factor of three, with the upfront inference profiling cost included.
Intrinsic Selection and Particle Resampling for Inference-Time Scaling Beyond Domain Verifiability
Jun 07, 2026Inference-Time Scaling (ITS) has largely succeeded in verifiable domains like math and coding, where cheap verification enables scalable output selection. However, extending ITS to tasks prone to systematic failure - driven by faulty initial assumptions or unmet multidimensional constraints - typically relies on costly external solvers or brittle, model-based verifiers. Our key insight is that the intrinsic statistics of parallel sample sets, specifically length-adjusted tail entropy, provide a robust discriminative signal for solution quality without access to ground truth. Crucially, these statistics serve as a difficulty gate for adaptive compute allocation, dynamically routing problems across scaling regimes. First, Intrinsic Selection (iS) ranks candidates post-hoc, matching consensus-based algorithms across three domains and improving engineering design selection by 20% over pass@1 baselines. Second, Intrinsic Particle Filtering (iPF) generalizes this to step-level resampling, guiding generation toward high-confidence reasoning trajectories to improve pass@1 by 6.1 points on average on hard math problems. Finally, Particle Distillation (dPF) injects privileged guidance via early logit blending and KL-guided resampling, steering generation past systematic reasoning errors to satisfy expert rubrics, yielding up to 26.5% gains on complex clinical responses. Our pipeline applies seamlessly across broad-purpose, domain-specialized, and multimodal architectures, successfully extending ITS to open-ended domains without requiring trained reward models or exact ground-truth verification.
GIFT: Bootstrapping Image-to-CAD Program Synthesis via Geometric Feedback
Mar 28, 2026Generating executable CAD programs from images requires alignment between visual geometry and symbolic program representations, a capability that current methods fail to learn reliably as design complexity increases. Existing fine-tuning approaches rely on either limited supervised datasets or expensive post-training pipelines, resulting in brittle systems that restrict progress in generative CAD design. We argue that the primary bottleneck lies not in model or algorithmic capacity, but in the scarcity of diverse training examples that align visual geometry with program syntax. This limitation is especially acute because the collection of diverse and verified engineering datasets is both expensive and difficult to scale, constraining the development of robust generative CAD models. We introduce Geometric Inference Feedback Tuning (GIFT), a data augmentation framework that leverages geometric feedback to turn test-time compute into a bootstrapped set of high-quality training samples. GIFT combines two mechanisms: Soft-Rejection Sampling (GIFT-REJECT), which retains diverse high-fidelity programs beyond exact ground-truth matches, and Failure-Driven Augmentation (GIFT-FAIL), which converts near-miss predictions into synthetic training examples that improve robustness on challenging geometries. By amortizing inference-time search into the model parameters, GIFT captures the benefits of test-time scaling while reducing inference compute by 80%. It improves mean IoU by 12% over a strong supervised baseline and remains competitive with more complex multimodal systems, without requiring additional human annotation or specialized architectures.
Supervision-free Vision-Language Alignment
Jan 08, 2025Vision-language models (VLMs) have demonstrated remarkable potential in integrating visual and linguistic information, but their performance is often constrained by the need for extensive, high-quality image-text training data. Curation of these image-text pairs is both time-consuming and computationally expensive. To address this challenge, we introduce SVP (Supervision-free Visual Projection), a novel framework that enhances vision-language alignment without relying on curated data or preference annotation. SVP leverages self-captioning and a pre-trained grounding model as a feedback mechanism to elicit latent information in VLMs. We evaluate our approach across six key areas: captioning, referring, visual question answering, multitasking, hallucination control, and object recall. Results demonstrate significant improvements, including a 14% average improvement in captioning tasks, up to 12% increase in object recall, and substantial reduction in hallucination rates. Notably, a small VLM using SVP achieves hallucination reductions comparable to a model five times larger, while a VLM with initially poor referring capabilities more than doubles its performance, approaching parity with a model twice its size.
Reparameterized Multi-Resolution Convolutions for Long Sequence Modelling
Aug 18, 2024Global convolutions have shown increasing promise as powerful general-purpose sequence models. However, training long convolutions is challenging, and kernel parameterizations must be able to learn long-range dependencies without overfitting. This work introduces reparameterized multi-resolution convolutions ($\texttt{MRConv}$), a novel approach to parameterizing global convolutional kernels for long-sequence modelling. By leveraging multi-resolution convolutions, incorporating structural reparameterization and introducing learnable kernel decay, $\texttt{MRConv}$ learns expressive long-range kernels that perform well across various data modalities. Our experiments demonstrate state-of-the-art performance on the Long Range Arena, Sequential CIFAR, and Speech Commands tasks among convolution models and linear-time transformers. Moreover, we report improved performance on ImageNet classification by replacing 2D convolutions with 1D $\texttt{MRConv}$ layers.
NITO: Neural Implicit Fields for Resolution-free Topology Optimization
Feb 07, 2024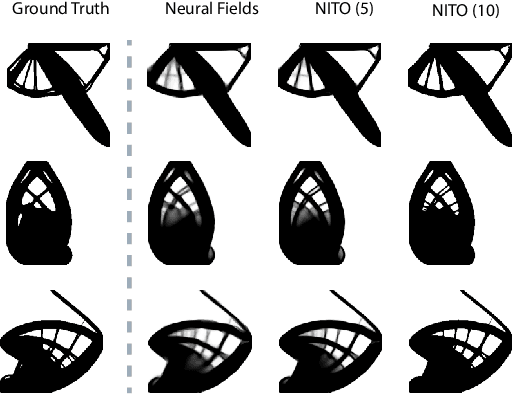

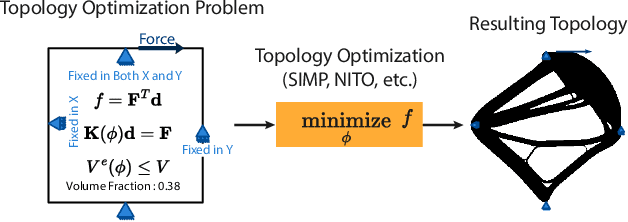
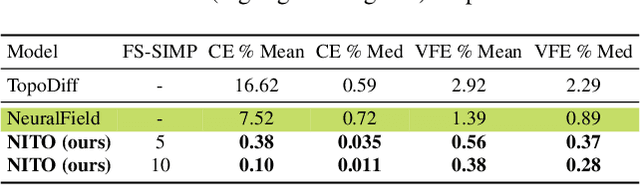
Topology optimization is a critical task in engineering design, where the goal is to optimally distribute material in a given space for maximum performance. We introduce Neural Implicit Topology Optimization (NITO), a novel approach to accelerate topology optimization problems using deep learning. NITO stands out as one of the first frameworks to offer a resolution-free and domain-agnostic solution in deep learning-based topology optimization. NITO synthesizes structures with up to seven times better structural efficiency compared to SOTA diffusion models and does so in a tenth of the time. In the NITO framework, we introduce a novel method, the Boundary Point Order-Invariant MLP (BPOM), to represent boundary conditions in a sparse and domain-agnostic manner, moving away from expensive simulation-based approaches. Crucially, NITO circumvents the domain and resolution limitations that restrict Convolutional Neural Network (CNN) models to a structured domain of fixed size -- limitations that hinder the widespread adoption of CNNs in engineering applications. This generalizability allows a single NITO model to train and generate solutions in countless domains, eliminating the need for numerous domain-specific CNNs and their extensive datasets. Despite its generalizability, NITO outperforms SOTA models even in specialized tasks, is an order of magnitude smaller, and is practically trainable at high resolutions that would be restrictive for CNNs. This combination of versatility, efficiency, and performance underlines NITO's potential to transform the landscape of engineering design optimization problems through implicit fields.
From Concept to Manufacturing: Evaluating Vision-Language Models for Engineering Design
Nov 21, 2023



Engineering Design is undergoing a transformative shift with the advent of AI, marking a new era in how we approach product, system, and service planning. Large language models have demonstrated impressive capabilities in enabling this shift. Yet, with text as their only input modality, they cannot leverage the large body of visual artifacts that engineers have used for centuries and are accustomed to. This gap is addressed with the release of multimodal vision language models, such as GPT-4V, enabling AI to impact many more types of tasks. In light of these advancements, this paper presents a comprehensive evaluation of GPT-4V, a vision language model, across a wide spectrum of engineering design tasks, categorized into four main areas: Conceptual Design, System-Level and Detailed Design, Manufacturing and Inspection, and Engineering Education Tasks. Our study assesses GPT-4V's capabilities in design tasks such as sketch similarity analysis, concept selection using Pugh Charts, material selection, engineering drawing analysis, CAD generation, topology optimization, design for additive and subtractive manufacturing, spatial reasoning challenges, and textbook problems. Through this structured evaluation, we not only explore GPT-4V's proficiency in handling complex design and manufacturing challenges but also identify its limitations in complex engineering design applications. Our research establishes a foundation for future assessments of vision language models, emphasizing their immense potential for innovating and enhancing the engineering design and manufacturing landscape. It also contributes a set of benchmark testing datasets, with more than 1000 queries, for ongoing advancements and applications in this field.
Learning from Invalid Data: On Constraint Satisfaction in Generative Models
Jun 27, 2023Generative models have demonstrated impressive results in vision, language, and speech. However, even with massive datasets, they struggle with precision, generating physically invalid or factually incorrect data. This is particularly problematic when the generated data must satisfy constraints, for example, to meet product specifications in engineering design or to adhere to the laws of physics in a natural scene. To improve precision while preserving diversity and fidelity, we propose a novel training mechanism that leverages datasets of constraint-violating data points, which we consider invalid. Our approach minimizes the divergence between the generative distribution and the valid prior while maximizing the divergence with the invalid distribution. We demonstrate how generative models like GANs and DDPMs that we augment to train with invalid data vastly outperform their standard counterparts which solely train on valid data points. For example, our training procedure generates up to 98 % fewer invalid samples on 2D densities, improves connectivity and stability four-fold on a stacking block problem, and improves constraint satisfaction by 15 % on a structural topology optimization benchmark in engineering design. We also analyze how the quality of the invalid data affects the learning procedure and the generalization properties of models. Finally, we demonstrate significant improvements in sample efficiency, showing that a tenfold increase in valid samples leads to a negligible difference in constraint satisfaction, while less than 10 % invalid samples lead to a tenfold improvement. Our proposed mechanism offers a promising solution for improving precision in generative models while preserving diversity and fidelity, particularly in domains where constraint satisfaction is critical and data is limited, such as engineering design, robotics, and medicine.
Aligning Optimization Trajectories with Diffusion Models for Constrained Design Generation
May 29, 2023



Generative models have had a profound impact on vision and language, paving the way for a new era of multimodal generative applications. While these successes have inspired researchers to explore using generative models in science and engineering to accelerate the design process and reduce the reliance on iterative optimization, challenges remain. Specifically, engineering optimization methods based on physics still outperform generative models when dealing with constrained environments where data is scarce and precision is paramount. To address these challenges, we introduce Diffusion Optimization Models (DOM) and Trajectory Alignment (TA), a learning framework that demonstrates the efficacy of aligning the sampling trajectory of diffusion models with the optimization trajectory derived from traditional physics-based methods. This alignment ensures that the sampling process remains grounded in the underlying physical principles. Our method allows for generating feasible and high-performance designs in as few as two steps without the need for expensive preprocessing, external surrogate models, or additional labeled data. We apply our framework to structural topology optimization, a fundamental problem in mechanical design, evaluating its performance on in- and out-of-distribution configurations. Our results demonstrate that TA outperforms state-of-the-art deep generative models on in-distribution configurations and halves the inference computational cost. When coupled with a few steps of optimization, it also improves manufacturability for out-of-distribution conditions. By significantly improving performance and inference efficiency, DOM enables us to generate high-quality designs in just a few steps and guide them toward regions of high performance and manufacturability, paving the way for the widespread application of generative models in large-scale data-driven design.
Diffusing the Optimal Topology: A Generative Optimization Approach
Mar 17, 2023



Topology Optimization seeks to find the best design that satisfies a set of constraints while maximizing system performance. Traditional iterative optimization methods like SIMP can be computationally expensive and get stuck in local minima, limiting their applicability to complex or large-scale problems. Learning-based approaches have been developed to accelerate the topology optimization process, but these methods can generate designs with floating material and low performance when challenged with out-of-distribution constraint configurations. Recently, deep generative models, such as Generative Adversarial Networks and Diffusion Models, conditioned on constraints and physics fields have shown promise, but they require extensive pre-processing and surrogate models for improving performance. To address these issues, we propose a Generative Optimization method that integrates classic optimization like SIMP as a refining mechanism for the topology generated by a deep generative model. We also remove the need for conditioning on physical fields using a computationally inexpensive approximation inspired by classic ODE solutions and reduce the number of steps needed to generate a feasible and performant topology. Our method allows us to efficiently generate good topologies and explicitly guide them to regions with high manufacturability and high performance, without the need for external auxiliary models or additional labeled data. We believe that our method can lead to significant advancements in the design and optimization of structures in engineering applications, and can be applied to a broader spectrum of performance-aware engineering design problems.