 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianHeadTalk: Wobble-Free 3D Talking Heads with Audio Driven Gaussian Splatting
Dec 11, 2025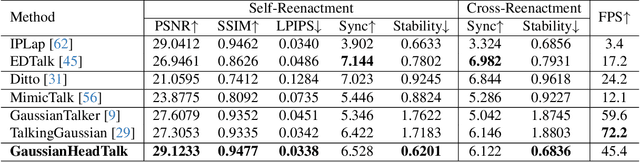
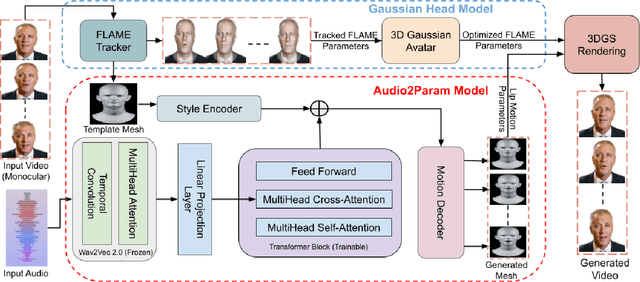
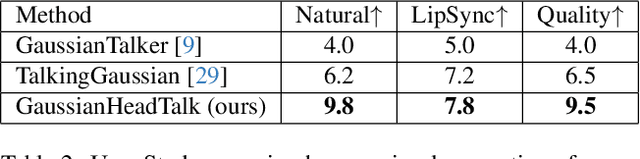

Speech-driven talking heads have recently emerged and enable interactive avatars. However, real-world applications are limited, as current methods achieve high visual fidelity but slow or fast yet temporally unstable. Diffusion methods provide realistic image generation, yet struggle with oneshot settings. Gaussian Splatting approaches are real-time, yet inaccuracies in facial tracking, or inconsistent Gaussian mappings, lead to unstable outputs and video artifacts that are detrimental to realistic use cases. We address this problem by mapping Gaussian Splatting using 3D Morphable Models to generate person-specific avatars. We introduce transformer-based prediction of model parameters, directly from audio, to drive temporal consistency. From monocular video and independent audio speech inputs, our method enables generation of real-time talking head videos where we report competitive quantitative and qualitative performance.
VarDiU: A Variational Diffusive Upper Bound for One-Step Diffusion Distillation
Aug 28, 2025Recently, diffusion distillation methods have compressed thousand-step teacher diffusion models into one-step student generators while preserving sample quality. Most existing approaches train the student model using a diffusive divergence whose gradient is approximated via the student's score function, learned through denoising score matching (DSM). Since DSM training is imperfect, the resulting gradient estimate is inevitably biased, leading to sub-optimal performance. In this paper, we propose VarDiU (pronounced /va:rdju:/), a Variational Diffusive Upper Bound that admits an unbiased gradient estimator and can be directly applied to diffusion distillation. Using this objective, we compare our method with Diff-Instruct and demonstrate that it achieves higher generation quality and enables a more efficient and stable training procedure for one-step diffusion distillation.
Towards Training One-Step Diffusion Models Without Distillation
Feb 11, 2025Recent advances in one-step generative models typically follow a two-stage process: first training a teacher diffusion model and then distilling it into a one-step student model. This distillation process traditionally relies on both the teacher model's score function to compute the distillation loss and its weights for student initialization. In this paper, we explore whether one-step generative models can be trained directly without this distillation process. First, we show that the teacher's score function is not essential and propose a family of distillation methods that achieve competitive results without relying on score estimation. Next, we demonstrate that initialization from teacher weights is indispensable in successful training. Surprisingly, we find that this benefit is not due to improved ``input-output" mapping but rather the learned feature representations, which dominate distillation quality. Our findings provide a better understanding of the role of initialization in one-step model training and its impact on distillation quality.
Training Neural Samplers with Reverse Diffusive KL Divergence
Oct 16, 2024Training generative models to sample from unnormalized density functions is an important and challenging task in machine learning. Traditional training methods often rely on the reverse Kullback-Leibler (KL) divergence due to its tractability. However, the mode-seeking behavior of reverse KL hinders effective approximation of multi-modal target distributions. To address this, we propose to minimize the reverse KL along diffusion trajectories of both model and target densities. We refer to this objective as the reverse diffusive KL divergence, which allows the model to capture multiple modes. Leveraging this objective, we train neural samplers that can efficiently generate samples from the target distribution in one step. We demonstrate that our method enhances sampling performance across various Boltzmann distributions, including both synthetic multi-modal densities and n-body particle systems.
Reparameterized Multi-Resolution Convolutions for Long Sequence Modelling
Aug 18, 2024Global convolutions have shown increasing promise as powerful general-purpose sequence models. However, training long convolutions is challenging, and kernel parameterizations must be able to learn long-range dependencies without overfitting. This work introduces reparameterized multi-resolution convolutions ($\texttt{MRConv}$), a novel approach to parameterizing global convolutional kernels for long-sequence modelling. By leveraging multi-resolution convolutions, incorporating structural reparameterization and introducing learnable kernel decay, $\texttt{MRConv}$ learns expressive long-range kernels that perform well across various data modalities. Our experiments demonstrate state-of-the-art performance on the Long Range Arena, Sequential CIFAR, and Speech Commands tasks among convolution models and linear-time transformers. Moreover, we report improved performance on ImageNet classification by replacing 2D convolutions with 1D $\texttt{MRConv}$ layers.
Diffusion Model With Optimal Covariance Matching
Jun 16, 2024The probabilistic diffusion model has become highly effective across various domains. Typically, sampling from a diffusion model involves using a denoising distribution characterized by a Gaussian with a learned mean and either fixed or learned covariances. In this paper, we leverage the recently proposed full covariance moment matching technique and introduce a novel method for learning covariances. Unlike traditional data-driven covariance approximation approaches, our method involves directly regressing the optimal analytic covariance using a new, unbiased objective named Optimal Covariance Matching (OCM). This approach can significantly reduce the approximation error in covariance prediction. We demonstrate how our method can substantially enhance the sampling efficiency of both Markovian (DDPM) and non-Markovian (DDIM) diffusion model families.
Mafin: Enhancing Black-Box Embeddings with Model Augmented Fine-Tuning
Feb 26, 2024



Retrieval Augmented Generation (RAG) has emerged as an effective solution for mitigating hallucinations in Large Language Models (LLMs). The retrieval stage in RAG typically involves a pre-trained embedding model, which converts queries and passages into vectors to capture their semantics. However, a standard pre-trained embedding model may exhibit sub-optimal performance when applied to specific domain knowledge, necessitating fine-tuning. This paper addresses scenarios where the embeddings are only available from a black-box model. We introduce Model augmented fine-tuning (Mafin) -- a novel approach for fine-tuning a black-box embedding model by augmenting it with a trainable embedding model. Our results demonstrate that Mafin significantly enhances the performance of the black-box embeddings by only requiring the training of a small augmented model. We validate the effectiveness of our method on both labeled and unlabeled datasets, illustrating its broad applicability and efficiency.
Active Preference Learning for Large Language Models
Feb 12, 2024As large language models (LLMs) become more capable, fine-tuning techniques for aligning with human intent are increasingly important. A key consideration for aligning these models is how to most effectively use human resources, or model resources in the case where LLMs themselves are used as oracles. Reinforcement learning from Human or AI preferences (RLHF/RLAIF) is the most prominent example of such a technique, but is complex and often unstable. Direct Preference Optimization (DPO) has recently been proposed as a simpler and more stable alternative. In this work, we develop an active learning strategy for DPO to make better use of preference labels. We propose a practical acquisition function for prompt/completion pairs based on the predictive entropy of the language model and a measure of certainty of the implicit preference model optimized by DPO. We demonstrate how our approach improves both the rate of learning and final performance of fine-tuning on pairwise preference data.
Diffusive Gibbs Sampling
Feb 05, 2024The inadequate mixing of conventional Markov Chain Monte Carlo (MCMC) methods for multi-modal distributions presents a significant challenge in practical applications such as Bayesian inference and molecular dynamics. Addressing this, we propose Diffusive Gibbs Sampling (DiGS), an innovative family of sampling methods designed for effective sampling from distributions characterized by distant and disconnected modes. DiGS integrates recent developments in diffusion models, leveraging Gaussian convolution to create an auxiliary noisy distribution that bridges isolated modes in the original space and applying Gibbs sampling to alternately draw samples from both spaces. Our approach exhibits a better mixing property for sampling multi-modal distributions than state-of-the-art methods such as parallel tempering. We demonstrate that our sampler attains substantially improved results across various tasks, including mixtures of Gaussians, Bayesian neural networks and molecular dynamics.
Incorporating Neuro-Inspired Adaptability for Continual Learning in Artificial Intelligence
Aug 29, 2023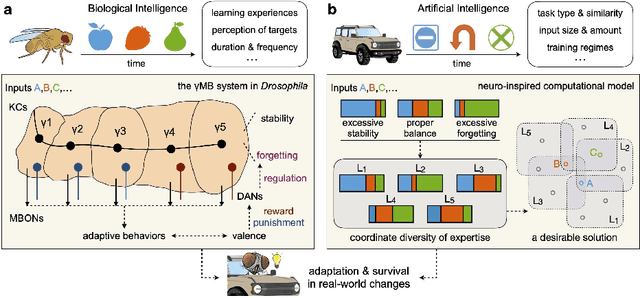


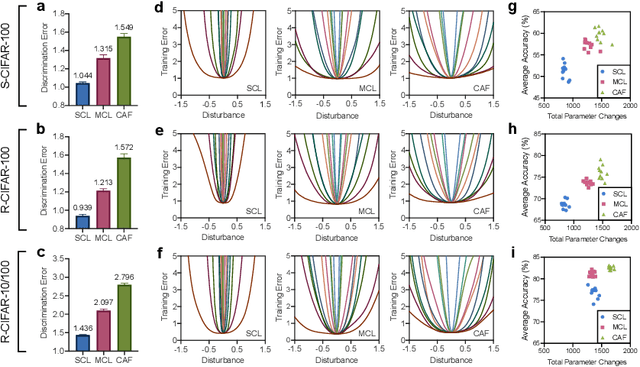
Continual learning aims to empower artificial intelligence (AI) with strong adaptability to the real world. For this purpose, a desirable solution should properly balance memory stability with learning plasticity, and acquire sufficient compatibility to capture the observed distributions. Existing advances mainly focus on preserving memory stability to overcome catastrophic forgetting, but remain difficult to flexibly accommodate incremental changes as biological intelligence (BI) does. By modeling a robust Drosophila learning system that actively regulates forgetting with multiple learning modules, here we propose a generic approach that appropriately attenuates old memories in parameter distributions to improve learning plasticity, and accordingly coordinates a multi-learner architecture to ensure solution compatibility. Through extensive theoretical and empirical validation, our approach not only clearly enhances the performance of continual learning, especially over synaptic regularization methods in task-incremental settings, but also potentially advances the understanding of neurological adaptive mechanisms, serving as a novel paradigm to progress AI and BI together.