 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Orthogonal Residual Spread for Precise Massive Editing in Large Language Models
Jan 16, 2026Large language models (LLMs) exhibit exceptional performance across various domains, yet they face critical safety concerns. Model editing has emerged as an effective approach to mitigate these issues. Existing model editing methods often focus on optimizing an information matrix that blends new and old knowledge. While effective, these approaches can be computationally expensive and may cause conflicts. In contrast, we shift our attention to Hierarchical Orthogonal Residual SprEad of the information matrix, which reduces noisy gradients and enables more stable edits from a different perspective. We demonstrate the effectiveness of our method HORSE through a clear theoretical comparison with several popular methods and extensive experiments conducted on two datasets across multiple LLMs. The results show that HORSE maintains precise massive editing across diverse scenarios. The code is available at https://github.com/XiaojieGu/HORSE
Compositional Attribute Imbalance in Vision Datasets
Jun 17, 2025Visual attribute imbalance is a common yet underexplored issue in image classification, significantly impacting model performance and generalization. In this work, we first define the first-level and second-level attributes of images and then introduce a CLIP-based framework to construct a visual attribute dictionary, enabling automatic evaluation of image attributes. By systematically analyzing both single-attribute imbalance and compositional attribute imbalance, we reveal how the rarity of attributes affects model performance. To tackle these challenges, we propose adjusting the sampling probability of samples based on the rarity of their compositional attributes. This strategy is further integrated with various data augmentation techniques (such as CutMix, Fmix, and SaliencyMix) to enhance the model's ability to represent rare attributes. Extensive experiments on benchmark datasets demonstrate that our method effectively mitigates attribute imbalance, thereby improving the robustness and fairness of deep neural networks. Our research highlights the importance of modeling visual attribute distributions and provides a scalable solution for long-tail image classification tasks.
Noise Diffusion for Enhancing Semantic Faithfulness in Text-to-Image Synthesis
Nov 25, 2024

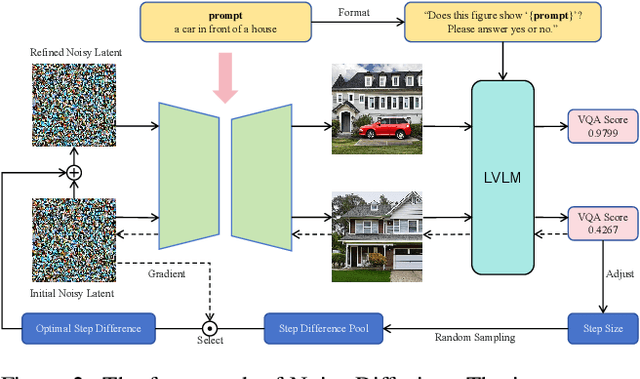

Diffusion models have achieved impressive success in generating photorealistic images, but challenges remain in ensuring precise semantic alignment with input prompts. Optimizing the initial noisy latent offers a more efficient alternative to modifying model architectures or prompt engineering for improving semantic alignment. A latest approach, InitNo, refines the initial noisy latent by leveraging attention maps; however, these maps capture only limited information, and the effectiveness of InitNo is highly dependent on the initial starting point, as it tends to converge on a local optimum near this point. To this end, this paper proposes leveraging the language comprehension capabilities of large vision-language models (LVLMs) to guide the optimization of the initial noisy latent, and introduces the Noise Diffusion process, which updates the noisy latent to generate semantically faithful images while preserving distribution consistency. Furthermore, we provide a theoretical analysis of the condition under which the update improves semantic faithfulness. Experimental results demonstrate the effectiveness and adaptability of our framework, consistently enhancing semantic alignment across various diffusion models. The code is available at https://github.com/Bomingmiao/NoiseDiffusion.
LoKO: Low-Rank Kalman Optimizer for Online Fine-Tuning of Large Models
Oct 15, 2024



Training large models with millions or even billions of parameters from scratch incurs substantial computational costs. Parameter Efficient Fine-Tuning (PEFT) methods, particularly Low-Rank Adaptation (LoRA), address this challenge by adapting only a reduced number of parameters to specific tasks with gradient-based optimizers. In this paper, we cast PEFT as an optimal filtering/state estimation problem and present Low-Rank Kalman Optimizer (LoKO) to estimate the optimal trainable parameters in an online manner. We leverage the low-rank decomposition in LoRA to significantly reduce matrix sizes in Kalman iterations and further capitalize on a diagonal approximation of the covariance matrix to effectively decrease computational complexity from quadratic to linear in the number of trainable parameters. Moreover, we discovered that the initialization of the covariance matrix within the Kalman algorithm and the accurate estimation of the observation noise covariance are the keys in this formulation, and we propose robust approaches that work well across a vast range of well-established computer vision and language models. Our results show that LoKO converges with fewer iterations and yields better performance models compared to commonly used optimizers with LoRA in both image classifications and language tasks. Our study opens up the possibility of leveraging the Kalman filter as an effective optimizer for the online fine-tuning of large models.
Learning to Discover Generalized Facial Expressions
Sep 30, 2024



We introduce Facial Expression Category Discovery (FECD), a novel task in the domain of open-world facial expression recognition (O-FER). While Generalized Category Discovery (GCD) has been explored in natural image datasets, applying it to facial expressions presents unique challenges. Specifically, we identify two key biases to better understand these challenges: Theoretical Bias-arising from the introduction of new categories in unlabeled training data, and Practical Bias-stemming from the imbalanced and fine-grained nature of facial expression data. To address these challenges, we propose FER-GCD, an adversarial approach that integrates both implicit and explicit debiasing components. In the implicit debiasing process, we devise F-discrepancy, a novel metric used to estimate the upper bound of Theoretical Bias, helping the model minimize this upper bound through adversarial training. The explicit debiasing process further optimizes the feature generator and classifier to reduce Practical Bias. Extensive experiments on GCD-based FER datasets demonstrate that our FER-GCD framework significantly improves accuracy on both old and new categories, achieving an average improvement of 9.8% over the baseline and outperforming state-of-the-art methods.
Diffusion Model With Optimal Covariance Matching
Jun 16, 2024The probabilistic diffusion model has become highly effective across various domains. Typically, sampling from a diffusion model involves using a denoising distribution characterized by a Gaussian with a learned mean and either fixed or learned covariances. In this paper, we leverage the recently proposed full covariance moment matching technique and introduce a novel method for learning covariances. Unlike traditional data-driven covariance approximation approaches, our method involves directly regressing the optimal analytic covariance using a new, unbiased objective named Optimal Covariance Matching (OCM). This approach can significantly reduce the approximation error in covariance prediction. We demonstrate how our method can substantially enhance the sampling efficiency of both Markovian (DDPM) and non-Markovian (DDIM) diffusion model families.
Your Finetuned Large Language Model is Already a Powerful Out-of-distribution Detector
Apr 07, 2024
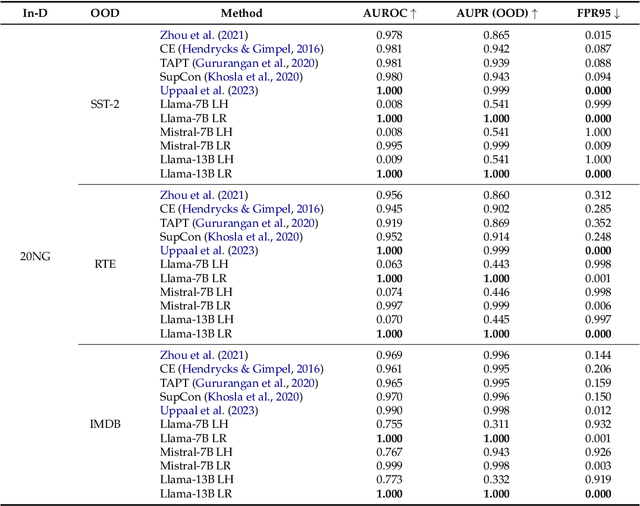
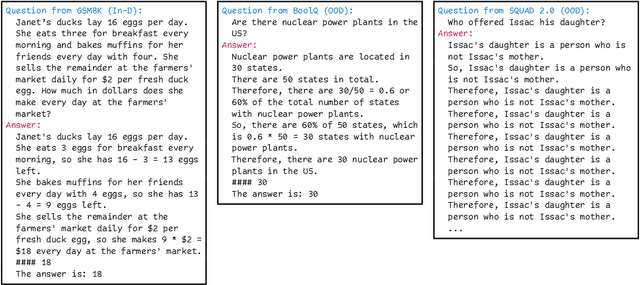
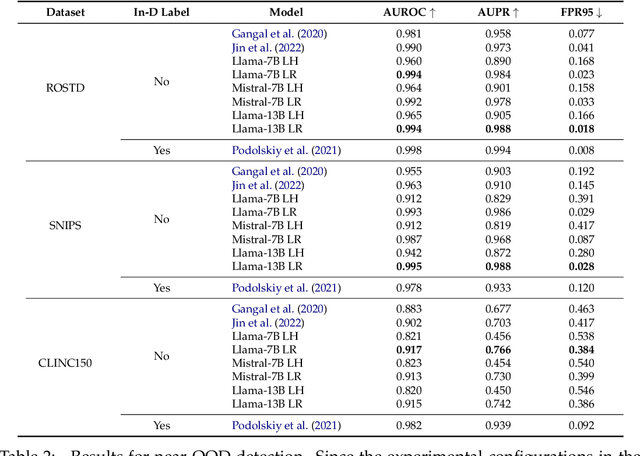
We revisit the likelihood ratio between a pretrained large language model (LLM) and its finetuned variant as a criterion for out-of-distribution (OOD) detection. The intuition behind such a criterion is that, the pretrained LLM has the prior knowledge about OOD data due to its large amount of training data, and once finetuned with the in-distribution data, the LLM has sufficient knowledge to distinguish their difference. Leveraging the power of LLMs, we show that, for the first time, the likelihood ratio can serve as an effective OOD detector. Moreover, we apply the proposed LLM-based likelihood ratio to detect OOD questions in question-answering (QA) systems, which can be used to improve the performance of specialized LLMs for general questions. Given that likelihood can be easily obtained by the loss functions within contemporary neural network frameworks, it is straightforward to implement this approach in practice. Since both the pretrained LLMs and its various finetuned models are available, our proposed criterion can be effortlessly incorporated for OOD detection without the need for further training. We conduct comprehensive evaluation across on multiple settings, including far OOD, near OOD, spam detection, and QA scenarios, to demonstrate the effectiveness of the method.
Constructing Semantics-Aware Adversarial Examples with Probabilistic Perspective
Jun 01, 2023In this study, we introduce a novel, probabilistic viewpoint on adversarial examples, achieved through box-constrained Langevin Monte Carlo (LMC). Proceeding from this perspective, we develop an innovative approach for generating semantics-aware adversarial examples in a principled manner. This methodology transcends the restriction imposed by geometric distance, instead opting for semantic constraints. Our approach empowers individuals to incorporate their personal comprehension of semantics into the model. Through human evaluation, we validate that our semantics-aware adversarial examples maintain their inherent meaning. Experimental findings on the MNIST and SVHN datasets demonstrate that our semantics-aware adversarial examples can effectively circumvent robust adversarial training methods tailored for traditional adversarial attacks.
SR-OOD: Out-of-Distribution Detection via Sample Repairing
May 26, 2023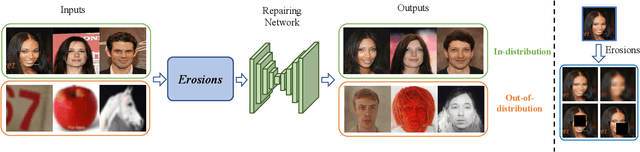
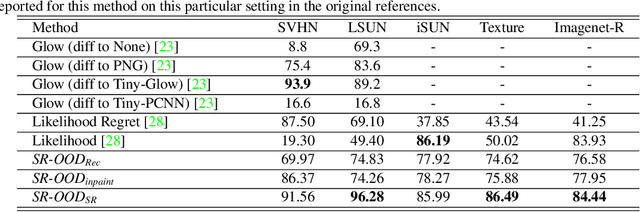

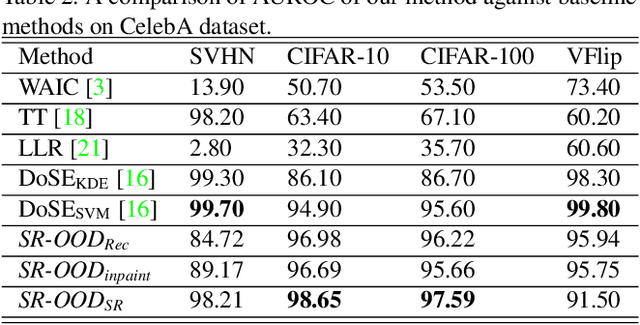
It is widely reported that deep generative models can classify out-of-distribution (OOD) samples as in-distribution with high confidence. In this work, we propose a hypothesis that this phenomenon is due to the reconstruction task, which can cause the generative model to focus too much on low-level features and not enough on semantic information. To address this issue, we introduce SR-OOD, an OOD detection framework that utilizes sample repairing to encourage the generative model to learn more than just an identity map. By focusing on semantics, our framework improves OOD detection performance without external data and label information. Our experimental results demonstrate the competitiveness of our approach in detecting OOD samples.
Falsehoods that ML researchers believe about OOD detection
Nov 01, 2022An intuitive way to detect out-of-distribution (OOD) data is via the density function of a fitted probabilistic generative model: points with low density may be classed as OOD. But this approach has been found to fail, in deep learning settings. In this paper, we list some falsehoods that machine learning researchers believe about density-based OOD detection. Many recent works have proposed likelihood-ratio-based methods to `fix' the problem. We propose a framework, the OOD proxy framework, to unify these methods, and we argue that likelihood ratio is a principled method for OOD detection and not a mere `fix'. Finally, we discuss the relationship between domain discrimination and semantics.