 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Easy-to-Hard: Limits of Curriculum Learning in Post-Training for Deductive Reasoning
Mar 28, 2026Curriculum learning (CL), motivated by the intuition that learning in increasing order of difficulty should ease generalization, is commonly adopted both in pre-training and post-training of large language models (LLMs). The intuition of CL is particularly compelling for compositional reasoning, where complex problems are built from elementary inference rules; however, the actual impact of CL on such tasks remains largely underexplored. We present a systematic empirical study of CL for post-training of LLMs, using synthetic arithmetic and logical benchmarks where difficulty is characterized by reasoning complexity rather than surface-level proxies. Surprisingly, across multiple model families and curriculum schedules, we find no robust advantage in difficulty-based sequencing over standard random sampling in either accuracy or response length. These findings persist across both supervised fine-tuning (SFT) and reinforcement learning (RL) methods. Our study suggests that, in the context of deductive reasoning, the specific ordering of training examples plays a negligible role in achieving compositional generalization, challenging the practical utility of curriculum-based post-training.
Streaming Autoregressive Video Generation via Diagonal Distillation
Mar 11, 2026Large pretrained diffusion models have significantly enhanced the quality of generated videos, and yet their use in real-time streaming remains limited. Autoregressive models offer a natural framework for sequential frame synthesis but require heavy computation to achieve high fidelity. Diffusion distillation can compress these models into efficient few-step variants, but existing video distillation approaches largely adapt image-specific methods that neglect temporal dependencies. These techniques often excel in image generation but underperform in video synthesis, exhibiting reduced motion coherence, error accumulation over long sequences, and a latency-quality trade-off. We identify two factors that result in these limitations: insufficient utilization of temporal context during step reduction and implicit prediction of subsequent noise levels in next-chunk prediction (i.e., exposure bias). To address these issues, we propose Diagonal Distillation, which operates orthogonally to existing approaches and better exploits temporal information across both video chunks and denoising steps. Central to our approach is an asymmetric generation strategy: more steps early, fewer steps later. This design allows later chunks to inherit rich appearance information from thoroughly processed early chunks, while using partially denoised chunks as conditional inputs for subsequent synthesis. By aligning the implicit prediction of subsequent noise levels during chunk generation with the actual inference conditions, our approach mitigates error propagation and reduces oversaturation in long-range sequences. We further incorporate implicit optical flow modeling to preserve motion quality under strict step constraints. Our method generates a 5-second video in 2.61 seconds (up to 31 FPS), achieving a 277.3x speedup over the undistilled model.
POET-X: Memory-efficient LLM Training by Scaling Orthogonal Transformation
Mar 05, 2026Efficient and stable training of large language models (LLMs) remains a core challenge in modern machine learning systems. To address this challenge, Reparameterized Orthogonal Equivalence Training (POET), a spectrum-preserving framework that optimizes each weight matrix through orthogonal equivalence transformation, has been proposed. Although POET provides strong training stability, its original implementation incurs high memory consumption and computational overhead due to intensive matrix multiplications. To overcome these limitations, we introduce POET-X, a scalable and memory-efficient variant that performs orthogonal equivalence transformations with significantly reduced computational cost. POET-X maintains the generalization and stability benefits of POET while achieving substantial improvements in throughput and memory efficiency. In our experiments, POET-X enables the pretraining of billion-parameter LLMs on a single Nvidia H100 GPU, and in contrast, standard optimizers such as AdamW run out of memory under the same settings.
Rigidity-Aware Geometric Pretraining for Protein Design and Conformational Ensembles
Mar 02, 2026Generative models have recently advanced $\textit{de novo}$ protein design by learning the statistical regularities of natural structures. However, current approaches face three key limitations: (1) Existing methods cannot jointly learn protein geometry and design tasks, where pretraining can be a solution; (2) Current pretraining methods mostly rely on local, non-rigid atomic representations for property prediction downstream tasks, limiting global geometric understanding for protein generation tasks; and (3) Existing approaches have yet to effectively model the rich dynamic and conformational information of protein structures. To overcome these issues, we introduce $\textbf{RigidSSL}$ ($\textit{Rigidity-Aware Self-Supervised Learning}$), a geometric pretraining framework that front-loads geometry learning prior to generative finetuning. Phase I (RigidSSL-Perturb) learns geometric priors from 432K structures from the AlphaFold Protein Structure Database with simulated perturbations. Phase II (RigidSSL-MD) refines these representations on 1.3K molecular dynamics trajectories to capture physically realistic transitions. Underpinning both phases is a bi-directional, rigidity-aware flow matching objective that jointly optimizes translational and rotational dynamics to maximize mutual information between conformations. Empirically, RigidSSL variants improve designability by up to 43\% while enhancing novelty and diversity in unconditional generation. Furthermore, RigidSSL-Perturb improves the success rate by 5.8\% in zero-shot motif scaffolding and RigidSSL-MD captures more biophysically realistic conformational ensembles in G protein-coupled receptor modeling. The code is available at: https://github.com/ZhanghanNi/RigidSSL.git.
Orthogonal Model Merging
Feb 05, 2026Merging finetuned Large Language Models (LLMs) has become increasingly important for integrating diverse capabilities into a single unified model. However, prevailing model merging methods rely on linear arithmetic in Euclidean space, which often destroys the intrinsic geometric properties of pretrained weights, such as hyperspherical energy. To address this, we propose Orthogonal Model Merging (OrthoMerge), a method that performs merging operations on the Riemannian manifold formed by the orthogonal group to preserve the geometric structure of the model's weights. By mapping task-specific orthogonal matrices learned by Orthogonal Finetuning (OFT) to the Lie algebra, OrthoMerge enables a principled yet efficient integration that takes into account both the direction and intensity of adaptations. In addition to directly leveraging orthogonal matrices obtained by OFT, we further extend this approach to general models finetuned with non-OFT methods (i.e., low-rank finetuning, full finetuning) via an Orthogonal-Residual Decoupling strategy. This technique extracts the orthogonal components of expert models by solving the orthogonal Procrustes problem, which are then merged on the manifold of the orthogonal group, while the remaining linear residuals are processed through standard additive merging. Extensive empirical results demonstrate the effectiveness of OrthoMerge in mitigating catastrophic forgetting and maintaining model performance across diverse tasks.
Agentic Design of Compositional Machines
Oct 16, 2025The design of complex machines stands as both a marker of human intelligence and a foundation of engineering practice. Given recent advances in large language models (LLMs), we ask whether they, too, can learn to create. We approach this question through the lens of compositional machine design: a task in which machines are assembled from standardized components to meet functional demands like locomotion or manipulation in a simulated physical environment. To support this investigation, we introduce BesiegeField, a testbed built on the machine-building game Besiege, which enables part-based construction, physical simulation and reward-driven evaluation. Using BesiegeField, we benchmark state-of-the-art LLMs with agentic workflows and identify key capabilities required for success, including spatial reasoning, strategic assembly, and instruction-following. As current open-source models fall short, we explore reinforcement learning (RL) as a path to improvement: we curate a cold-start dataset, conduct RL finetuning experiments, and highlight open challenges at the intersection of language, machine design, and physical reasoning.
Symbolic Graphics Programming with Large Language Models
Sep 05, 2025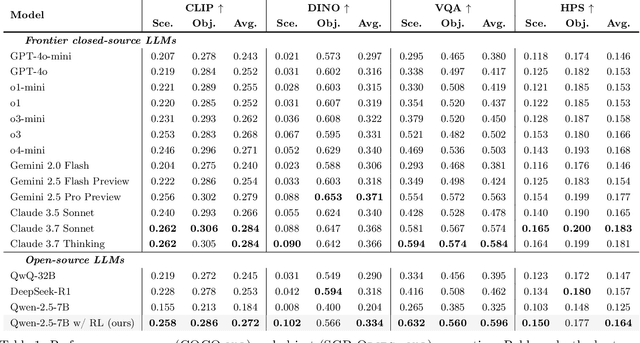
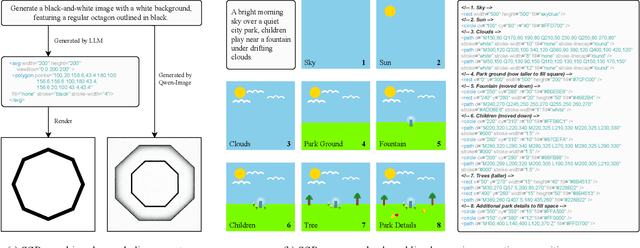
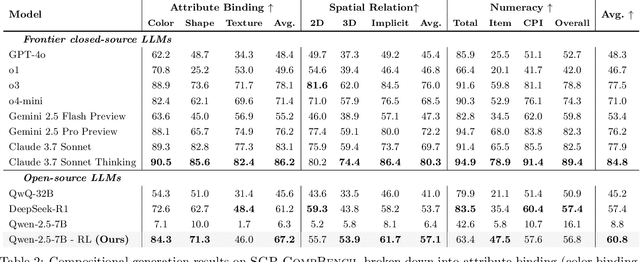
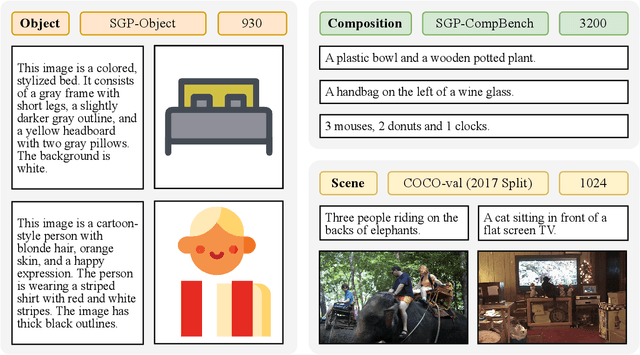
Large language models (LLMs) excel at program synthesis, yet their ability to produce symbolic graphics programs (SGPs) that render into precise visual content remains underexplored. We study symbolic graphics programming, where the goal is to generate an SGP from a natural-language description. This task also serves as a lens into how LLMs understand the visual world by prompting them to generate images rendered from SGPs. Among various SGPs, our paper sticks to scalable vector graphics (SVGs). We begin by examining the extent to which LLMs can generate SGPs. To this end, we introduce SGP-GenBench, a comprehensive benchmark covering object fidelity, scene fidelity, and compositionality (attribute binding, spatial relations, numeracy). On SGP-GenBench, we discover that frontier proprietary models substantially outperform open-source models, and performance correlates well with general coding capabilities. Motivated by this gap, we aim to improve LLMs' ability to generate SGPs. We propose a reinforcement learning (RL) with verifiable rewards approach, where a format-validity gate ensures renderable SVG, and a cross-modal reward aligns text and the rendered image via strong vision encoders (e.g., SigLIP for text-image and DINO for image-image). Applied to Qwen-2.5-7B, our method substantially improves SVG generation quality and semantics, achieving performance on par with frontier systems. We further analyze training dynamics, showing that RL induces (i) finer decomposition of objects into controllable primitives and (ii) contextual details that improve scene coherence. Our results demonstrate that symbolic graphics programming offers a precise and interpretable lens on cross-modal grounding.
Orthogonal Finetuning Made Scalable
Jun 24, 2025Orthogonal finetuning (OFT) offers highly parameter-efficient adaptation while preventing catastrophic forgetting, but its high runtime and memory demands limit practical deployment. We identify the core computational bottleneck in OFT as its weight-centric implementation, which relies on costly matrix-matrix multiplications with cubic complexity. To overcome this, we propose OFTv2, an input-centric reformulation that instead uses matrix-vector multiplications (i.e., matrix-free computation), reducing the computational cost to quadratic. We further introduce the Cayley-Neumann parameterization, an efficient orthogonal parameterization that approximates the matrix inversion in Cayley transform via a truncated Neumann series. These modifications allow OFTv2 to achieve up to 10x faster training and 3x lower GPU memory usage without compromising performance. In addition, we extend OFTv2 to support finetuning quantized foundation models and show that it outperforms the popular QLoRA in training stability, efficiency, and memory usage.
Flipping Against All Odds: Reducing LLM Coin Flip Bias via Verbalized Rejection Sampling
Jun 11, 2025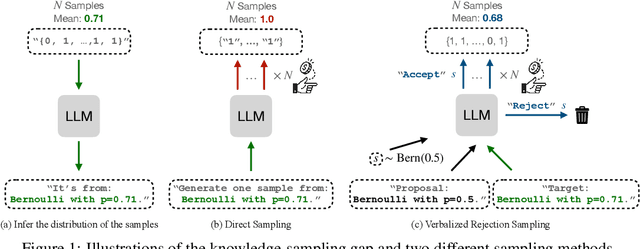


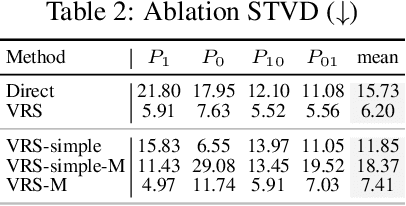
Large language models (LLMs) can often accurately describe probability distributions using natural language, yet they still struggle to generate faithful samples from them. This mismatch limits their use in tasks requiring reliable stochasticity, such as Monte Carlo methods, agent-based simulations, and randomized decision-making. We investigate this gap between knowledge and sampling in the context of Bernoulli distributions. We introduce Verbalized Rejection Sampling (VRS), a natural-language adaptation of classical rejection sampling that prompts the LLM to reason about and accept or reject proposed samples. Despite relying on the same Bernoulli mechanism internally, VRS substantially reduces sampling bias across models. We provide theoretical analysis showing that, under mild assumptions, VRS improves over direct sampling, with gains attributable to both the algorithm and prompt design. More broadly, our results show how classical probabilistic tools can be verbalized and embedded into LLM workflows to improve reliability, without requiring access to model internals or heavy prompt engineering.
Reparameterized LLM Training via Orthogonal Equivalence Transformation
Jun 09, 2025While large language models (LLMs) are driving the rapid advancement of artificial intelligence, effectively and reliably training these large models remains one of the field's most significant challenges. To address this challenge, we propose POET, a novel reParameterized training algorithm that uses Orthogonal Equivalence Transformation to optimize neurons. Specifically, POET reparameterizes each neuron with two learnable orthogonal matrices and a fixed random weight matrix. Because of its provable preservation of spectral properties of weight matrices, POET can stably optimize the objective function with improved generalization. We further develop efficient approximations that make POET flexible and scalable for training large-scale neural networks. Extensive experiments validate the effectiveness and scalability of POET in training LLMs.