 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReparameterized LLM Training via Orthogonal Equivalence Transformation
Jun 09, 2025While large language models (LLMs) are driving the rapid advancement of artificial intelligence, effectively and reliably training these large models remains one of the field's most significant challenges. To address this challenge, we propose POET, a novel reParameterized training algorithm that uses Orthogonal Equivalence Transformation to optimize neurons. Specifically, POET reparameterizes each neuron with two learnable orthogonal matrices and a fixed random weight matrix. Because of its provable preservation of spectral properties of weight matrices, POET can stably optimize the objective function with improved generalization. We further develop efficient approximations that make POET flexible and scalable for training large-scale neural networks. Extensive experiments validate the effectiveness and scalability of POET in training LLMs.
Synthesizing 3D Abstractions by Inverting Procedural Buildings with Transformers
Jan 29, 2025We generate abstractions of buildings, reflecting the essential aspects of their geometry and structure, by learning to invert procedural models. We first build a dataset of abstract procedural building models paired with simulated point clouds and then learn the inverse mapping through a transformer. Given a point cloud, the trained transformer then infers the corresponding abstracted building in terms of a programmatic language description. This approach leverages expressive procedural models developed for gaming and animation, and thereby retains desirable properties such as efficient rendering of the inferred abstractions and strong priors for regularity and symmetry. Our approach achieves good reconstruction accuracy in terms of geometry and structure, as well as structurally consistent inpainting.
Flow Matching for Atmospheric Retrieval of Exoplanets: Where Reliability meets Adaptive Noise Levels
Oct 28, 2024



Inferring atmospheric properties of exoplanets from observed spectra is key to understanding their formation, evolution, and habitability. Since traditional Bayesian approaches to atmospheric retrieval (e.g., nested sampling) are computationally expensive, a growing number of machine learning (ML) methods such as neural posterior estimation (NPE) have been proposed. We seek to make ML-based atmospheric retrieval (1) more reliable and accurate with verified results, and (2) more flexible with respect to the underlying neural networks and the choice of the assumed noise models. First, we adopt flow matching posterior estimation (FMPE) as a new ML approach to atmospheric retrieval. FMPE maintains many advantages of NPE, but provides greater architectural flexibility and scalability. Second, we use importance sampling (IS) to verify and correct ML results, and to compute an estimate of the Bayesian evidence. Third, we condition our ML models on the assumed noise level of a spectrum (i.e., error bars), thus making them adaptable to different noise models. Both our noise level-conditional FMPE and NPE models perform on par with nested sampling across a range of noise levels when tested on simulated data. FMPE trains about 3 times faster than NPE and yields higher IS efficiencies. IS successfully corrects inaccurate ML results, identifies model failures via low efficiencies, and provides accurate estimates of the Bayesian evidence. FMPE is a powerful alternative to NPE for fast, amortized, and parallelizable atmospheric retrieval. IS can verify results, thus helping to build confidence in ML-based approaches, while also facilitating model comparison via the evidence ratio. Noise level conditioning allows design studies for future instruments to be scaled up, for example, in terms of the range of signal-to-noise ratios.
Fast and Reliable Probabilistic Reflectometry Inversion with Prior-Amortized Neural Posterior Estimation
Jul 26, 2024Reconstructing the structure of thin films and multilayers from measurements of scattered X-rays or neutrons is key to progress in physics, chemistry, and biology. However, finding all structures compatible with reflectometry data is computationally prohibitive for standard algorithms, which typically results in unreliable analysis with only a single potential solution identified. We address this lack of reliability with a probabilistic deep learning method that identifies all realistic structures in seconds, setting new standards in reflectometry. Our method, Prior-Amortized Neural Posterior Estimation (PANPE), combines simulation-based inference with novel adaptive priors that inform the inference network about known structural properties and controllable experimental conditions. PANPE networks support key scenarios such as high-throughput sample characterization, real-time monitoring of evolving structures, or the co-refinement of several experimental data sets, and can be adapted to provide fast, reliable, and flexible inference across many other inverse problems.
Real-time gravitational-wave inference for binary neutron stars using machine learning
Jul 12, 2024



Mergers of binary neutron stars (BNSs) emit signals in both the gravitational-wave (GW) and electromagnetic (EM) spectra. Famously, the 2017 multi-messenger observation of GW170817 led to scientific discoveries across cosmology, nuclear physics, and gravity. Central to these results were the sky localization and distance obtained from GW data, which, in the case of GW170817, helped to identify the associated EM transient, AT 2017gfo, 11 hours after the GW signal. Fast analysis of GW data is critical for directing time-sensitive EM observations; however, due to challenges arising from the length and complexity of signals, it is often necessary to make approximations that sacrifice accuracy. Here, we develop a machine learning approach that performs complete BNS inference in just one second without making any such approximations. This is enabled by a new method for explicit integration of physical domain knowledge into neural networks. Our approach enhances multi-messenger observations by providing (i) accurate localization even before the merger; (ii) improved localization precision by $\sim30\%$ compared to approximate low-latency methods; and (iii) detailed information on luminosity distance, inclination, and masses, which can be used to prioritize expensive telescope time. Additionally, the flexibility and reduced cost of our method open new opportunities for equation-of-state and waveform systematics studies. Finally, we demonstrate that our method scales to extremely long signals, up to an hour in length, thus serving as a blueprint for data analysis for next-generation ground- and space-based detectors.
Inferring Atmospheric Properties of Exoplanets with Flow Matching and Neural Importance Sampling
Dec 13, 2023



Atmospheric retrievals (AR) characterize exoplanets by estimating atmospheric parameters from observed light spectra, typically by framing the task as a Bayesian inference problem. However, traditional approaches such as nested sampling are computationally expensive, thus sparking an interest in solutions based on machine learning (ML). In this ongoing work, we first explore flow matching posterior estimation (FMPE) as a new ML-based method for AR and find that, in our case, it is more accurate than neural posterior estimation (NPE), but less accurate than nested sampling. We then combine both FMPE and NPE with importance sampling, in which case both methods outperform nested sampling in terms of accuracy and simulation efficiency. Going forward, our analysis suggests that simulation-based inference with likelihood-based importance sampling provides a framework for accurate and efficient AR that may become a valuable tool not only for the analysis of observational data from existing telescopes, but also for the development of new missions and instruments.
Flow Matching for Scalable Simulation-Based Inference
May 26, 2023Neural posterior estimation methods based on discrete normalizing flows have become established tools for simulation-based inference (SBI), but scaling them to high-dimensional problems can be challenging. Building on recent advances in generative modeling, we here present flow matching posterior estimation (FMPE), a technique for SBI using continuous normalizing flows. Like diffusion models, and in contrast to discrete flows, flow matching allows for unconstrained architectures, providing enhanced flexibility for complex data modalities. Flow matching, therefore, enables exact density evaluation, fast training, and seamless scalability to large architectures--making it ideal for SBI. We show that FMPE achieves competitive performance on an established SBI benchmark, and then demonstrate its improved scalability on a challenging scientific problem: for gravitational-wave inference, FMPE outperforms methods based on comparable discrete flows, reducing training time by 30% with substantially improved accuracy. Our work underscores the potential of FMPE to enhance performance in challenging inference scenarios, thereby paving the way for more advanced applications to scientific problems.
Adapting to noise distribution shifts in flow-based gravitational-wave inference
Nov 16, 2022



Deep learning techniques for gravitational-wave parameter estimation have emerged as a fast alternative to standard samplers $\unicode{x2013}$ producing results of comparable accuracy. These approaches (e.g., DINGO) enable amortized inference by training a normalizing flow to represent the Bayesian posterior conditional on observed data. By conditioning also on the noise power spectral density (PSD) they can even account for changing detector characteristics. However, training such networks requires knowing in advance the distribution of PSDs expected to be observed, and therefore can only take place once all data to be analyzed have been gathered. Here, we develop a probabilistic model to forecast future PSDs, greatly increasing the temporal scope of DINGO networks. Using PSDs from the second LIGO-Virgo observing run (O2) $\unicode{x2013}$ plus just a single PSD from the beginning of the third (O3) $\unicode{x2013}$ we show that we can train a DINGO network to perform accurate inference throughout O3 (on 37 real events). We therefore expect this approach to be a key component to enable the use of deep learning techniques for low-latency analyses of gravitational waves.
Neural Importance Sampling for Rapid and Reliable Gravitational-Wave Inference
Oct 11, 2022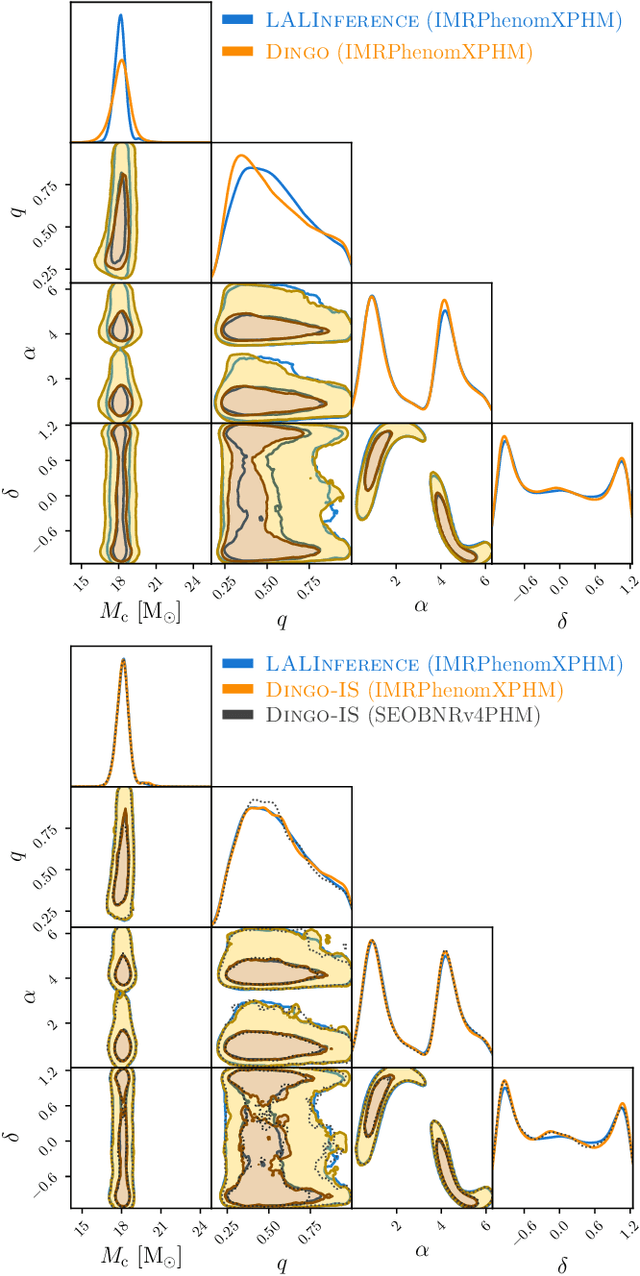
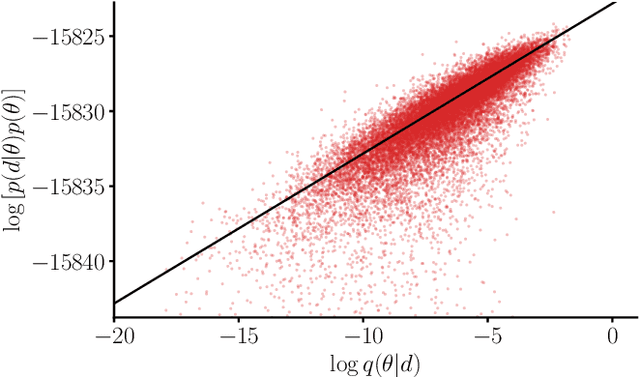
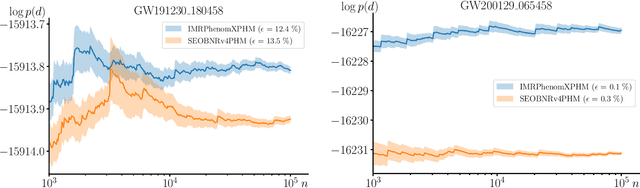
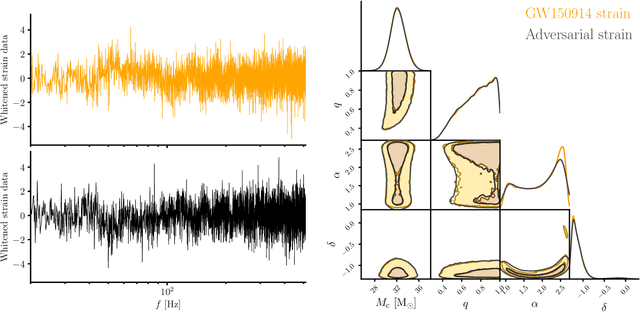
We combine amortized neural posterior estimation with importance sampling for fast and accurate gravitational-wave inference. We first generate a rapid proposal for the Bayesian posterior using neural networks, and then attach importance weights based on the underlying likelihood and prior. This provides (1) a corrected posterior free from network inaccuracies, (2) a performance diagnostic (the sample efficiency) for assessing the proposal and identifying failure cases, and (3) an unbiased estimate of the Bayesian evidence. By establishing this independent verification and correction mechanism we address some of the most frequent criticisms against deep learning for scientific inference. We carry out a large study analyzing 42 binary black hole mergers observed by LIGO and Virgo with the SEOBNRv4PHM and IMRPhenomXPHM waveform models. This shows a median sample efficiency of $\approx 10\%$ (two orders-of-magnitude better than standard samplers) as well as a ten-fold reduction in the statistical uncertainty in the log evidence. Given these advantages, we expect a significant impact on gravitational-wave inference, and for this approach to serve as a paradigm for harnessing deep learning methods in scientific applications.
Group equivariant neural posterior estimation
Nov 25, 2021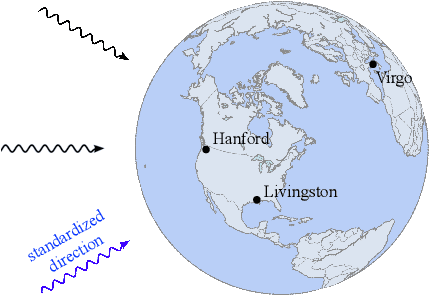
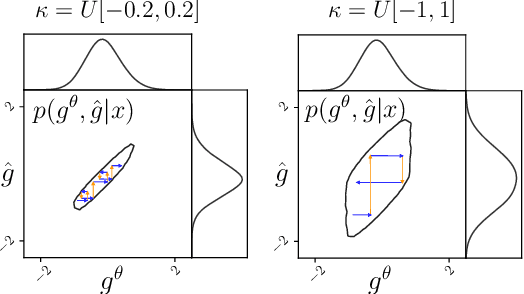
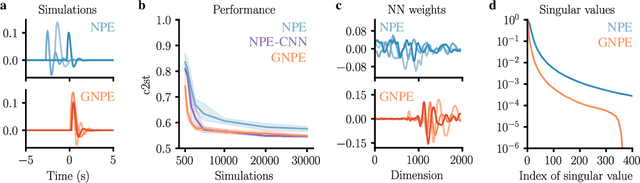
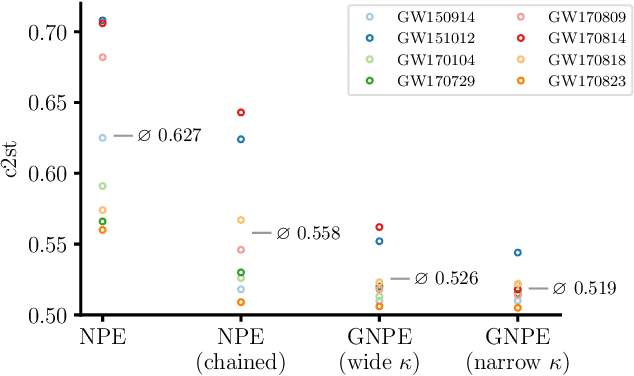
Simulation-based inference with conditional neural density estimators is a powerful approach to solving inverse problems in science. However, these methods typically treat the underlying forward model as a black box, with no way to exploit geometric properties such as equivariances. Equivariances are common in scientific models, however integrating them directly into expressive inference networks (such as normalizing flows) is not straightforward. We here describe an alternative method to incorporate equivariances under joint transformations of parameters and data. Our method -- called group equivariant neural posterior estimation (GNPE) -- is based on self-consistently standardizing the "pose" of the data while estimating the posterior over parameters. It is architecture-independent, and applies both to exact and approximate equivariances. As a real-world application, we use GNPE for amortized inference of astrophysical binary black hole systems from gravitational-wave observations. We show that GNPE achieves state-of-the-art accuracy while reducing inference times by three orders of magnitude.