 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperMentor: A Human-Centered Multi-Agent Writing Tutor for AI Research Papers on Overleaf
Jun 07, 2026Expert writing feedback from experienced researchers is critical for early-career scholars to improve their manuscripts, yet high-quality feedback often remains scarce because reviewing research papers is labor-intensive. Emerging AI-powered writing assistants largely focus on grammar fixes or simulating peer review with final scores, yet they fall short of providing concrete, actionable suggestions that help students improve their papers during drafting. We present PaperMentor, a human-centered writing assistant system that delivers actionable suggestions as Overleaf-native inline comments while leaving the actual writing entirely to human authors. PaperMentor integrates an expert skill library carefully curated from established researchers' writing advice with 12 specialized agents covering different aspects of paper writing, such as formatting compliance, phrasing accuracy, and terminology consistency. In a user study (n=14), 90.6% of the generated comments were rated actionable and 67.5% were rated valid, significantly outperforming a GPT-5.2 baseline uswithout the skill library. We release PaperMentor as open source for public use. Our code is publicly available under the AGPL-3.0 license at https://github.com/jiarui-liu/overleaf
PEFT-Arena: Understanding Parameter-Efficient Finetuning from a Stability-Plasticity Perspective
May 27, 2026Parameter-efficient finetuning (PEFT) has become the standard approach for adapting large language models, yet evaluations largely emphasize downstream accuracy while overlooking the retention of pretrained capabilities. We argue that PEFT should be assessed through the stability-plasticity dilemma: the trade-off between target-task adaptation and resistance to forgetting. We introduce PEFT-Arena, a benchmark that jointly measures downstream performance and general capability retention. Across methods, we find distinct stability-plasticity profiles; under comparable parameter budgets, orthogonal finetuning achieves the most favorable Pareto frontier. To explain these differences, we analyze PEFT updates from two geometric perspectives. In weight space, spectral analysis reveals how parameterizations interact with the pretrained singular-value structure. In activation space, retention metrics show whether finetuning preserves or distorts general-capability representations, with forgetting linked to non-isometric representation distortion. Finally, an analysis shows that final SFT checkpoints often overshoot a better target-retention operating point. Inspired by this, we present case studies of a post-hoc improvement with path-wise rewinding.
Pion: A Spectrum-Preserving Optimizer via Orthogonal Equivalence Transformation
May 12, 2026We introduce Pion, a spectrum-preserving optimizer for large language model (LLM) training based on orthogonal equivalence transformation. Unlike additive optimizers such as Adam and Muon, Pion updates each weight matrix through left and right orthogonal transformations, preserving its singular values throughout training. This yields an optimization mechanism that modulates the geometry of weight matrices while keeping their spectral norm fixed. We derive the Pion update rule, systematically examine its design choices, and analyze its convergence behavior along with several key properties. Empirical results show that Pion offers a stable and competitive alternative to standard optimizers for both LLM pretraining and finetuning.
POET-X: Memory-efficient LLM Training by Scaling Orthogonal Transformation
Mar 05, 2026Efficient and stable training of large language models (LLMs) remains a core challenge in modern machine learning systems. To address this challenge, Reparameterized Orthogonal Equivalence Training (POET), a spectrum-preserving framework that optimizes each weight matrix through orthogonal equivalence transformation, has been proposed. Although POET provides strong training stability, its original implementation incurs high memory consumption and computational overhead due to intensive matrix multiplications. To overcome these limitations, we introduce POET-X, a scalable and memory-efficient variant that performs orthogonal equivalence transformations with significantly reduced computational cost. POET-X maintains the generalization and stability benefits of POET while achieving substantial improvements in throughput and memory efficiency. In our experiments, POET-X enables the pretraining of billion-parameter LLMs on a single Nvidia H100 GPU, and in contrast, standard optimizers such as AdamW run out of memory under the same settings.
Rigidity-Aware Geometric Pretraining for Protein Design and Conformational Ensembles
Mar 02, 2026Generative models have recently advanced $\textit{de novo}$ protein design by learning the statistical regularities of natural structures. However, current approaches face three key limitations: (1) Existing methods cannot jointly learn protein geometry and design tasks, where pretraining can be a solution; (2) Current pretraining methods mostly rely on local, non-rigid atomic representations for property prediction downstream tasks, limiting global geometric understanding for protein generation tasks; and (3) Existing approaches have yet to effectively model the rich dynamic and conformational information of protein structures. To overcome these issues, we introduce $\textbf{RigidSSL}$ ($\textit{Rigidity-Aware Self-Supervised Learning}$), a geometric pretraining framework that front-loads geometry learning prior to generative finetuning. Phase I (RigidSSL-Perturb) learns geometric priors from 432K structures from the AlphaFold Protein Structure Database with simulated perturbations. Phase II (RigidSSL-MD) refines these representations on 1.3K molecular dynamics trajectories to capture physically realistic transitions. Underpinning both phases is a bi-directional, rigidity-aware flow matching objective that jointly optimizes translational and rotational dynamics to maximize mutual information between conformations. Empirically, RigidSSL variants improve designability by up to 43\% while enhancing novelty and diversity in unconditional generation. Furthermore, RigidSSL-Perturb improves the success rate by 5.8\% in zero-shot motif scaffolding and RigidSSL-MD captures more biophysically realistic conformational ensembles in G protein-coupled receptor modeling. The code is available at: https://github.com/ZhanghanNi/RigidSSL.git.
Symbolic Graphics Programming with Large Language Models
Sep 05, 2025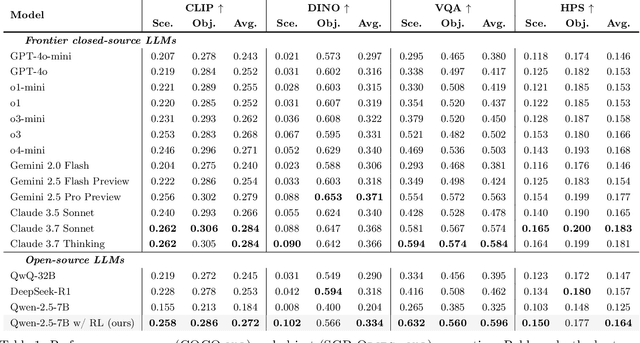
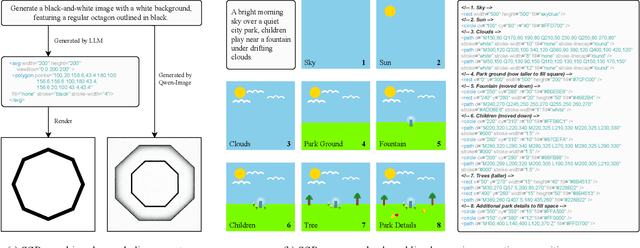
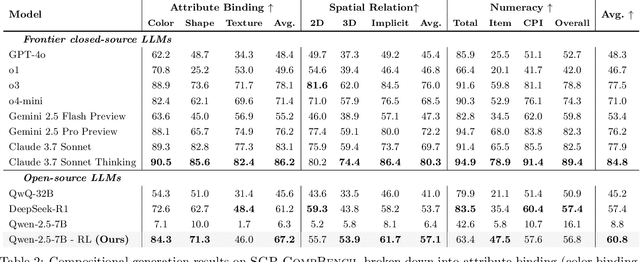
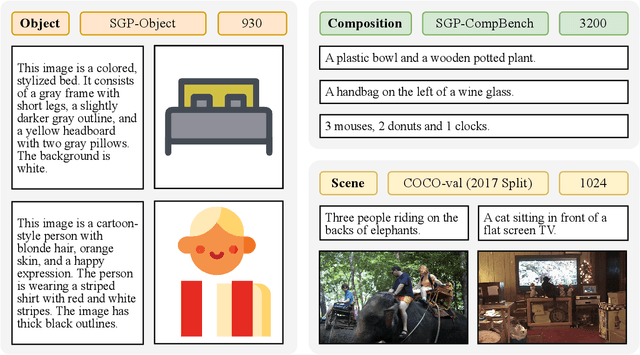
Large language models (LLMs) excel at program synthesis, yet their ability to produce symbolic graphics programs (SGPs) that render into precise visual content remains underexplored. We study symbolic graphics programming, where the goal is to generate an SGP from a natural-language description. This task also serves as a lens into how LLMs understand the visual world by prompting them to generate images rendered from SGPs. Among various SGPs, our paper sticks to scalable vector graphics (SVGs). We begin by examining the extent to which LLMs can generate SGPs. To this end, we introduce SGP-GenBench, a comprehensive benchmark covering object fidelity, scene fidelity, and compositionality (attribute binding, spatial relations, numeracy). On SGP-GenBench, we discover that frontier proprietary models substantially outperform open-source models, and performance correlates well with general coding capabilities. Motivated by this gap, we aim to improve LLMs' ability to generate SGPs. We propose a reinforcement learning (RL) with verifiable rewards approach, where a format-validity gate ensures renderable SVG, and a cross-modal reward aligns text and the rendered image via strong vision encoders (e.g., SigLIP for text-image and DINO for image-image). Applied to Qwen-2.5-7B, our method substantially improves SVG generation quality and semantics, achieving performance on par with frontier systems. We further analyze training dynamics, showing that RL induces (i) finer decomposition of objects into controllable primitives and (ii) contextual details that improve scene coherence. Our results demonstrate that symbolic graphics programming offers a precise and interpretable lens on cross-modal grounding.
Orthogonal Finetuning Made Scalable
Jun 24, 2025Orthogonal finetuning (OFT) offers highly parameter-efficient adaptation while preventing catastrophic forgetting, but its high runtime and memory demands limit practical deployment. We identify the core computational bottleneck in OFT as its weight-centric implementation, which relies on costly matrix-matrix multiplications with cubic complexity. To overcome this, we propose OFTv2, an input-centric reformulation that instead uses matrix-vector multiplications (i.e., matrix-free computation), reducing the computational cost to quadratic. We further introduce the Cayley-Neumann parameterization, an efficient orthogonal parameterization that approximates the matrix inversion in Cayley transform via a truncated Neumann series. These modifications allow OFTv2 to achieve up to 10x faster training and 3x lower GPU memory usage without compromising performance. In addition, we extend OFTv2 to support finetuning quantized foundation models and show that it outperforms the popular QLoRA in training stability, efficiency, and memory usage.
Reparameterized LLM Training via Orthogonal Equivalence Transformation
Jun 09, 2025While large language models (LLMs) are driving the rapid advancement of artificial intelligence, effectively and reliably training these large models remains one of the field's most significant challenges. To address this challenge, we propose POET, a novel reParameterized training algorithm that uses Orthogonal Equivalence Transformation to optimize neurons. Specifically, POET reparameterizes each neuron with two learnable orthogonal matrices and a fixed random weight matrix. Because of its provable preservation of spectral properties of weight matrices, POET can stably optimize the objective function with improved generalization. We further develop efficient approximations that make POET flexible and scalable for training large-scale neural networks. Extensive experiments validate the effectiveness and scalability of POET in training LLMs.
Can Large Language Models Understand Symbolic Graphics Programs?
Aug 15, 2024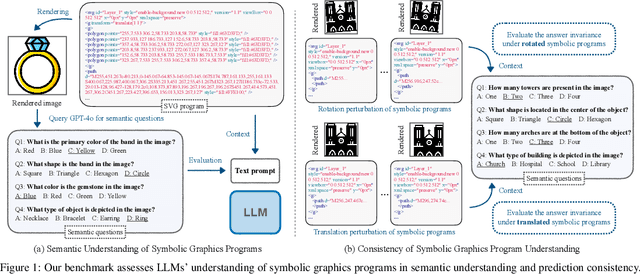

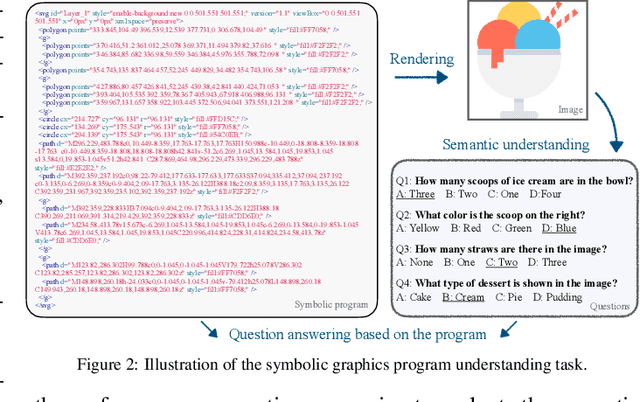
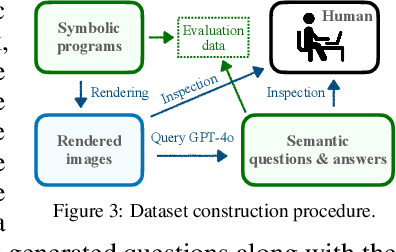
Assessing the capabilities of large language models (LLMs) is often challenging, in part, because it is hard to find tasks to which they have not been exposed during training. We take one step to address this challenge by turning to a new task: focusing on symbolic graphics programs, which are a popular representation for graphics content that procedurally generates visual data. LLMs have shown exciting promise towards program synthesis, but do they understand symbolic graphics programs? Unlike conventional programs, symbolic graphics programs can be translated to graphics content. Here, we characterize an LLM's understanding of symbolic programs in terms of their ability to answer questions related to the graphics content. This task is challenging as the questions are difficult to answer from the symbolic programs alone -- yet, they would be easy to answer from the corresponding graphics content as we verify through a human experiment. To understand symbolic programs, LLMs may need to possess the ability to imagine how the corresponding graphics content would look without directly accessing the rendered visual content. We use this task to evaluate LLMs by creating a large benchmark for the semantic understanding of symbolic graphics programs. This benchmark is built via program-graphics correspondence, hence requiring minimal human efforts. We evaluate current LLMs on our benchmark to elucidate a preliminary assessment of their ability to reason about visual scenes from programs. We find that this task distinguishes existing LLMs and models considered good at reasoning perform better. Lastly, we introduce Symbolic Instruction Tuning (SIT) to improve this ability. Specifically, we query GPT4-o with questions and images generated by symbolic programs. Such data are then used to finetune an LLM. We also find that SIT data can improve the general instruction following ability of LLMs.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023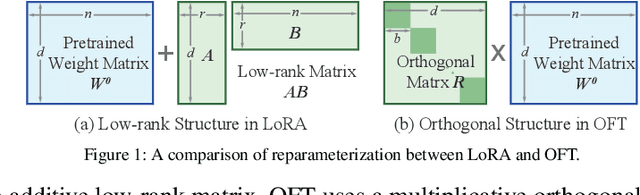
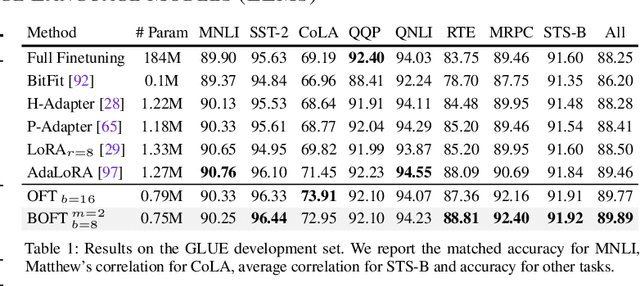
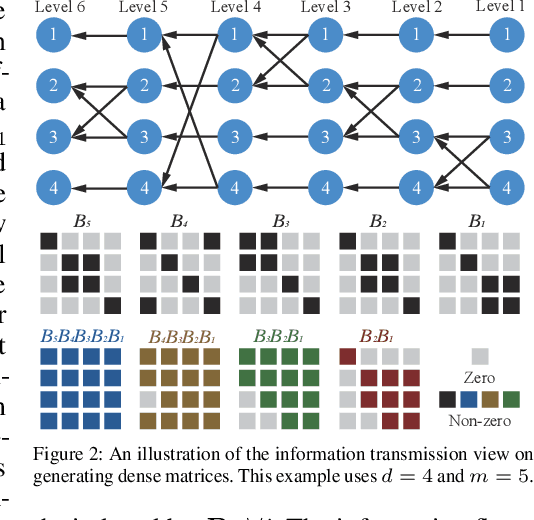
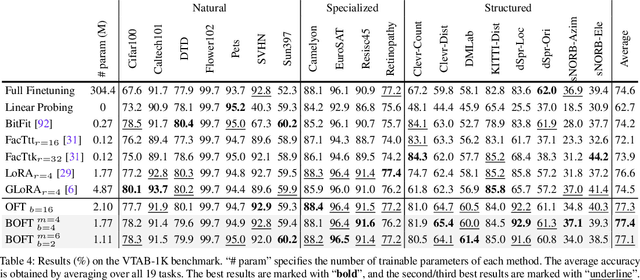
Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.