 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Policy Optimization without Drifting Apart
Jun 11, 2026RL post-training has become increasingly pivotal for improving diffusion policies, but existing diffusion policy-gradient methods are often unstable and cannot achieve reliable policy improvement. We identify the cause as the double-drift phenomenon: optimizing a variational surrogate can let the ELBO separate from the true log-likelihood, which then makes the resulting proxy policy gradient misaligned with the true policy gradient of expected return. We propose \textbf{DiPOD}, a diffusion policy optimization framework that maintains tight-bound behavior throughout training by interleaving self-distillation with policy-improving gradient updates. This leads to a simple and practical algorithm: augmenting each diffusion policy-gradient update with an on-policy ELBO regularizer. Across diffusion language model post-training and continuous-control diffusion policies, DiPOD substantially stabilizes training and reaches higher rewards than previous methods.
Streaming Video Generation with Streaming Force Control
Jun 05, 2026We introduce StreamForce, a streaming video generation framework that enables physically grounded control through continuous force inputs. Unlike prior video models that train separate models for different force types, assume fixed forces, or rely on non-causal processing, StreamForce is a causal and unified model that responds instantly and coherently to both local and global, time-varying forces. To achieve this, we design a unified force representation as a control signal and develop a distillation pipeline for force-controllable video generation. Our model combines autoregressive efficiency with force responsiveness, sustaining stable photometric and dynamic realism. StreamForce runs at up to 16.6 FPS on a single GPU, achieving state-of-the-art performance in both force adherence and motion realism. Project website: https://neu-vi.github.io/StreamForce/
Self-Improving 4D Perception via Self-Distillation
Apr 09, 2026Large-scale multi-view reconstruction models have made remarkable progress, but most existing approaches still rely on fully supervised training with ground-truth 3D/4D annotations. Such annotations are expensive and particularly scarce for dynamic scenes, limiting scalability. We propose SelfEvo, a self-improving framework that continually improves pretrained multi-view reconstruction models using unlabeled videos. SelfEvo introduces a self-distillation scheme using spatiotemporal context asymmetry, enabling self-improvement for learning-based 4D perception without external annotations. We systematically study design choices that make self-improvement effective, including loss signals, forms of asymmetry, and other training strategies. Across eight benchmarks spanning diverse datasets and domains, SelfEvo consistently improves pretrained baselines and generalizes across base models (e.g. VGGT and $π^3$), with significant gains on dynamic scenes. Overall, SelfEvo achieves up to 36.5% relative improvement in video depth estimation and 20.1% in camera estimation, without using any labeled data. Project Page: https://self-evo.github.io/.
Maximum Likelihood Reinforcement Learning
Feb 02, 2026Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Jan 16, 2026Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program is a long-standing goal of computer vision. Yet even strong VLMs aren't able to achieve this in one-shot as they lack fine-grained spatial and physical grounding capability. Our key insight is that closing this gap requires interleaved multimodal reasoning through iterative execution and verification. Stemming from this, we present VIGA (Vision-as-Inverse-Graphic Agent) that starts from an empty world and reconstructs or edits scenes through a closed-loop write-run-render-compare-revise procedure. To support long-horizon reasoning, VIGA combines (i) a skill library that alternates generator and verifier roles and (ii) an evolving context memory that contains plans, code diffs, and render history. VIGA is task-agnostic as it doesn't require auxiliary modules, covering a wide range of tasks such as 3D reconstruction, multi-step scene editing, 4D physical interaction, and 2D document editing, etc. Empirically, we found VIGA substantially improves one-shot baselines on BlenderGym (35.32%) and SlideBench (117.17%). Moreover, VIGA is also model-agnostic as it doesn't require finetuning, enabling a unified protocol to evaluate heterogeneous foundation VLMs. To better support this protocol, we introduce BlenderBench, a challenging benchmark that stress-tests interleaved multimodal reasoning with graphics engine, where VIGA improves by 124.70%.
Visually Prompted Benchmarks Are Surprisingly Fragile
Dec 19, 2025



A key challenge in evaluating VLMs is testing models' ability to analyze visual content independently from their textual priors. Recent benchmarks such as BLINK probe visual perception through visual prompting, where questions about visual content are paired with coordinates to which the question refers, with the coordinates explicitly marked in the image itself. While these benchmarks are an important part of VLM evaluation, we find that existing models are surprisingly fragile to seemingly irrelevant details of visual prompting: simply changing a visual marker from red to blue can completely change rankings among models on a leaderboard. By evaluating nine commonly-used open- and closed-source VLMs on two visually prompted tasks, we demonstrate how details in benchmark setup, including visual marker design and dataset size, have a significant influence on model performance and leaderboard rankings. These effects can even be exploited to lift weaker models above stronger ones; for instance, slightly increasing the size of the visual marker results in open-source InternVL3-8B ranking alongside or better than much larger proprietary models like Gemini 2.5 Pro. We further show that low-level inference choices that are often ignored in benchmarking, such as JPEG compression levels in API calls, can also cause model lineup changes. These details have substantially larger impacts on visually prompted benchmarks than on conventional semantic VLM evaluations. To mitigate this instability, we curate existing datasets to create VPBench, a larger visually prompted benchmark with 16 visual marker variants. VPBench and additional analysis tools are released at https://lisadunlap.github.io/vpbench/.
Flow Matching Policy Gradients
Jul 28, 2025Flow-based generative models, including diffusion models, excel at modeling continuous distributions in high-dimensional spaces. In this work, we introduce Flow Policy Optimization (FPO), a simple on-policy reinforcement learning algorithm that brings flow matching into the policy gradient framework. FPO casts policy optimization as maximizing an advantage-weighted ratio computed from the conditional flow matching loss, in a manner compatible with the popular PPO-clip framework. It sidesteps the need for exact likelihood computation while preserving the generative capabilities of flow-based models. Unlike prior approaches for diffusion-based reinforcement learning that bind training to a specific sampling method, FPO is agnostic to the choice of diffusion or flow integration at both training and inference time. We show that FPO can train diffusion-style policies from scratch in a variety of continuous control tasks. We find that flow-based models can capture multimodal action distributions and achieve higher performance than Gaussian policies, particularly in under-conditioned settings.
St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
Apr 17, 2025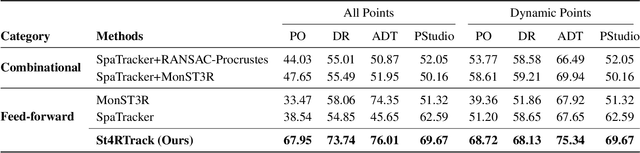
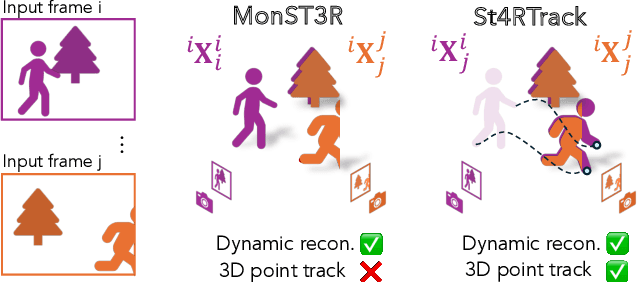
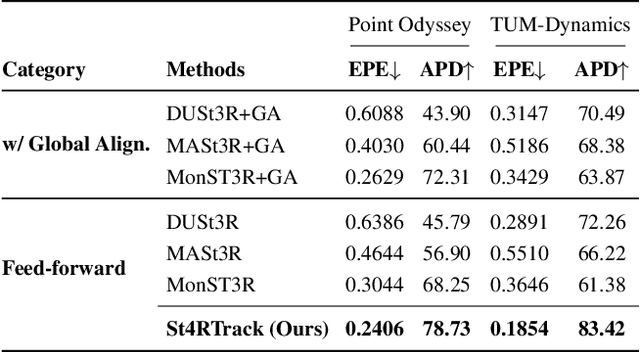
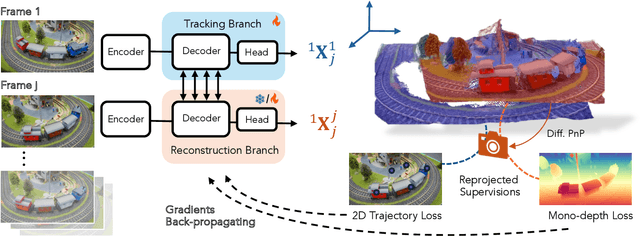
Dynamic 3D reconstruction and point tracking in videos are typically treated as separate tasks, despite their deep connection. We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate frame from RGB inputs. This is achieved by predicting two appropriately defined pointmaps for a pair of frames captured at different moments. Specifically, we predict both pointmaps at the same moment, in the same world, capturing both static and dynamic scene geometry while maintaining 3D correspondences. Chaining these predictions through the video sequence with respect to a reference frame naturally computes long-range correspondences, effectively combining 3D reconstruction with 3D tracking. Unlike prior methods that rely heavily on 4D ground truth supervision, we employ a novel adaptation scheme based on a reprojection loss. We establish a new extensive benchmark for world-frame reconstruction and tracking, demonstrating the effectiveness and efficiency of our unified, data-driven framework. Our code, model, and benchmark will be released.
ETCH: Generalizing Body Fitting to Clothed Humans via Equivariant Tightness
Mar 13, 2025Fitting a body to a 3D clothed human point cloud is a common yet challenging task. Traditional optimization-based approaches use multi-stage pipelines that are sensitive to pose initialization, while recent learning-based methods often struggle with generalization across diverse poses and garment types. We propose Equivariant Tightness Fitting for Clothed Humans, or ETCH, a novel pipeline that estimates cloth-to-body surface mapping through locally approximate SE(3) equivariance, encoding tightness as displacement vectors from the cloth surface to the underlying body. Following this mapping, pose-invariant body features regress sparse body markers, simplifying clothed human fitting into an inner-body marker fitting task. Extensive experiments on CAPE and 4D-Dress show that ETCH significantly outperforms state-of-the-art methods -- both tightness-agnostic and tightness-aware -- in body fitting accuracy on loose clothing (16.7% ~ 69.5%) and shape accuracy (average 49.9%). Our equivariant tightness design can even reduce directional errors by (67.2% ~ 89.8%) in one-shot (or out-of-distribution) settings. Qualitative results demonstrate strong generalization of ETCH, regardless of challenging poses, unseen shapes, loose clothing, and non-rigid dynamics. We will release the code and models soon for research purposes at https://boqian-li.github.io/ETCH/.
Predicting 4D Hand Trajectory from Monocular Videos
Jan 14, 2025



We present HaPTIC, an approach that infers coherent 4D hand trajectories from monocular videos. Current video-based hand pose reconstruction methods primarily focus on improving frame-wise 3D pose using adjacent frames rather than studying consistent 4D hand trajectories in space. Despite the additional temporal cues, they generally underperform compared to image-based methods due to the scarcity of annotated video data. To address these issues, we repurpose a state-of-the-art image-based transformer to take in multiple frames and directly predict a coherent trajectory. We introduce two types of lightweight attention layers: cross-view self-attention to fuse temporal information, and global cross-attention to bring in larger spatial context. Our method infers 4D hand trajectories similar to the ground truth while maintaining strong 2D reprojection alignment. We apply the method to both egocentric and allocentric videos. It significantly outperforms existing methods in global trajectory accuracy while being comparable to the state-of-the-art in single-image pose estimation. Project website: https://judyye.github.io/haptic-www