 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthForge: Synthesizing High-Quality Face Dataset with Controllable 3D Generative Models
Jun 12, 2024



Recent advancements in generative models have unlocked the capabilities to render photo-realistic data in a controllable fashion. Trained on the real data, these generative models are capable of producing realistic samples with minimal to no domain gap, as compared to the traditional graphics rendering. However, using the data generated using such models for training downstream tasks remains under-explored, mainly due to the lack of 3D consistent annotations. Moreover, controllable generative models are learned from massive data and their latent space is often too vast to obtain meaningful sample distributions for downstream task with limited generation. To overcome these challenges, we extract 3D consistent annotations from an existing controllable generative model, making the data useful for downstream tasks. Our experiments show competitive performance against state-of-the-art models using only generated synthetic data, demonstrating potential for solving downstream tasks. Project page: https://synth-forge.github.io
Semi-Supervised Domain Adaptation by Similarity based Pseudo-label Injection
Sep 05, 2022One of the primary challenges in Semi-supervised Domain Adaptation (SSDA) is the skewed ratio between the number of labeled source and target samples, causing the model to be biased towards the source domain. Recent works in SSDA show that aligning only the labeled target samples with the source samples potentially leads to incomplete domain alignment of the target domain to the source domain. In our approach, to align the two domains, we leverage contrastive losses to learn a semantically meaningful and a domain agnostic feature space using the supervised samples from both domains. To mitigate challenges caused by the skewed label ratio, we pseudo-label the unlabeled target samples by comparing their feature representation to those of the labeled samples from both the source and target domains. Furthermore, to increase the support of the target domain, these potentially noisy pseudo-labels are gradually injected into the labeled target dataset over the course of training. Specifically, we use a temperature scaled cosine similarity measure to assign a soft pseudo-label to the unlabeled target samples. Additionally, we compute an exponential moving average of the soft pseudo-labels for each unlabeled sample. These pseudo-labels are progressively injected or removed) into the (from) the labeled target dataset based on a confidence threshold to supplement the alignment of the source and target distributions. Finally, we use a supervised contrastive loss on the labeled and pseudo-labeled datasets to align the source and target distributions. Using our proposed approach, we showcase state-of-the-art performance on SSDA benchmarks - Office-Home, DomainNet and Office-31.
CLUDA : Contrastive Learning in Unsupervised Domain Adaptation for Semantic Segmentation
Aug 27, 2022
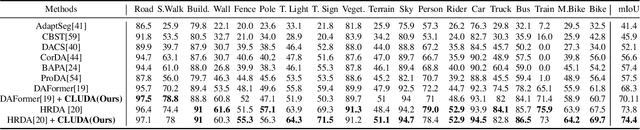
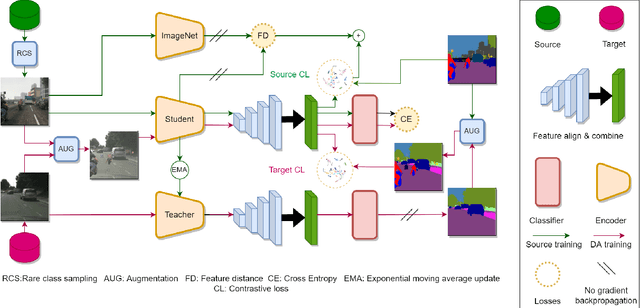
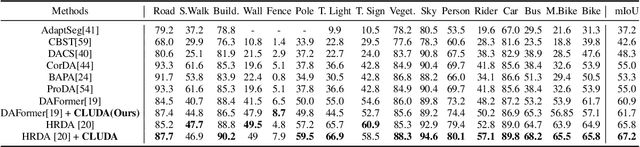
In this work, we propose CLUDA, a simple, yet novel method for performing unsupervised domain adaptation (UDA) for semantic segmentation by incorporating contrastive losses into a student-teacher learning paradigm, that makes use of pseudo-labels generated from the target domain by the teacher network. More specifically, we extract a multi-level fused-feature map from the encoder, and apply contrastive loss across different classes and different domains, via source-target mixing of images. We consistently improve performance on various feature encoder architectures and for different domain adaptation datasets in semantic segmentation. Furthermore, we introduce a learned-weighted contrastive loss to improve upon on a state-of-the-art multi-resolution training approach in UDA. We produce state-of-the-art results on GTA $\rightarrow$ Cityscapes (74.4 mIOU, +0.6) and Synthia $\rightarrow$ Cityscapes (67.2 mIOU, +1.4) datasets. CLUDA effectively demonstrates contrastive learning in UDA as a generic method, which can be easily integrated into any existing UDA for semantic segmentation tasks. Please refer to the supplementary material for the details on implementation.
ViTOL: Vision Transformer for Weakly Supervised Object Localization
Apr 14, 2022
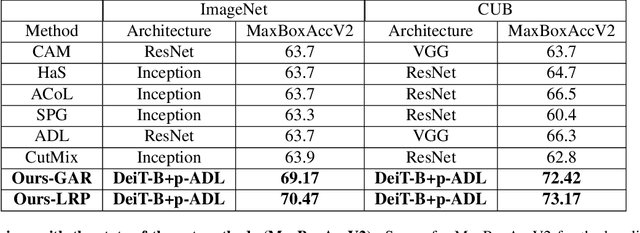
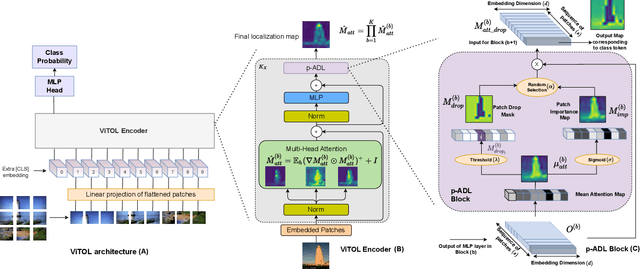
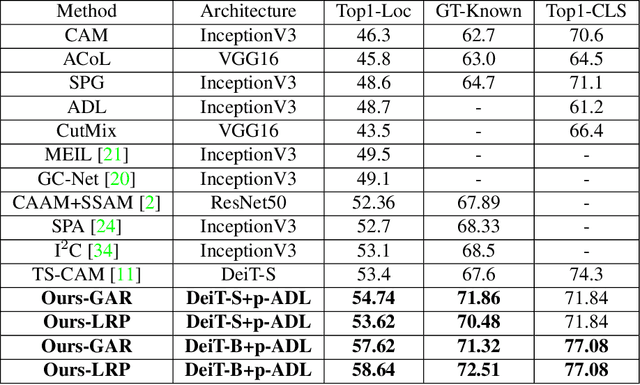
Weakly supervised object localization (WSOL) aims at predicting object locations in an image using only image-level category labels. Common challenges that image classification models encounter when localizing objects are, (a) they tend to look at the most discriminative features in an image that confines the localization map to a very small region, (b) the localization maps are class agnostic, and the models highlight objects of multiple classes in the same image and, (c) the localization performance is affected by background noise. To alleviate the above challenges we introduce the following simple changes through our proposed method ViTOL. We leverage the vision-based transformer for self-attention and introduce a patch-based attention dropout layer (p-ADL) to increase the coverage of the localization map and a gradient attention rollout mechanism to generate class-dependent attention maps. We conduct extensive quantitative, qualitative and ablation experiments on the ImageNet-1K and CUB datasets. We achieve state-of-the-art MaxBoxAcc-V2 localization scores of 70.47% and 73.17% on the two datasets respectively. Code is available on https://github.com/Saurav-31/ViTOL
AirCapRL: Autonomous Aerial Human Motion Capture using Deep Reinforcement Learning
Aug 01, 2020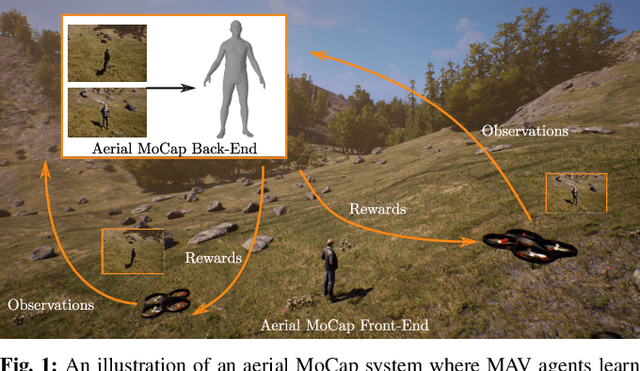



In this letter, we introduce a deep reinforcement learning (RL) based multi-robot formation controller for the task of autonomous aerial human motion capture (MoCap). We focus on vision-based MoCap, where the objective is to estimate the trajectory of body pose and shape of a single moving person using multiple micro aerial vehicles. State-of-the-art solutions to this problem are based on classical control methods, which depend on hand-crafted system and observation models. Such models are difficult to derive and generalize across different systems. Moreover, the non-linearity and non-convexities of these models lead to sub-optimal controls. In our work, we formulate this problem as a sequential decision making task to achieve the vision-based motion capture objectives, and solve it using a deep neural network-based RL method. We leverage proximal policy optimization (PPO) to train a stochastic decentralized control policy for formation control. The neural network is trained in a parallelized setup in synthetic environments. We performed extensive simulation experiments to validate our approach. Finally, real-robot experiments demonstrate that our policies generalize to real world conditions. Video Link: https://bit.ly/38SJfjo Supplementary: https://bit.ly/3evfo1O
Energy Conscious Over-actuated Multi-Agent Payload Transport Robot: Simulations and Preliminary Physical Validation
Sep 10, 2019



In this work, we consider a multi-wheeled payload transport system. Each of the wheels can be selectively actuated. When they are not actuated, wheels are free moving and do not consume battery power. The payload transport system is modeled as an actuated multi-agent system, with each wheel-motor pair as an agent. Kinematic and dynamic models are developed to ensure that the payload transport system moves as desired. We design optimization formulations to decide on the number of wheels to be active and which of the wheels to be active so that the battery is conserved and the wear on the motors is reduced. Our multi-level control framework over the agents ensures that near-optimal number of agents is active for the payload transport system to function. Through simulation studies we show that our solution ensures energy efficient operation and increases the distance traveled by the payload transport system, for the same battery power. We have built the payload transport system and provide results for preliminary experimental validation.
Multiple Drones driven Hexagonally Partitioned Area Exploration: Simulation and Evaluation
Jun 02, 2019



In this paper, we simulated a distributed, cooperative path planning technique for multiple drones ($\sim$200) to explore an unknown region ($\sim$10,000 connected units) in the presence of obstacles. The map of an unknown region is dynamically created based on the information obtained from sensors and other drones. The unknown area is considered as connected region made up of hexagonal unit cells. These cells are grouped to form larger cells called sub-areas. We use two types of communication, one long range and another more frequently used short range communication. The short range communication within drones in smaller proximity helps avoid obstacles and re-exploration of cells already explored by companion drones located in same subarea. The long range communication helps drones identify next sub area to be targeted by individual drones based on weighted RNN (Reverse nearest neighbour).\par Simulation results show that using weighted RNN with two types of communication in a hexagonal representation of subareas makes exploration more efficient, scalable and resilient to communication failures.
Loosely Coupled Payload Transport System with Robot Replacement
Apr 05, 2019
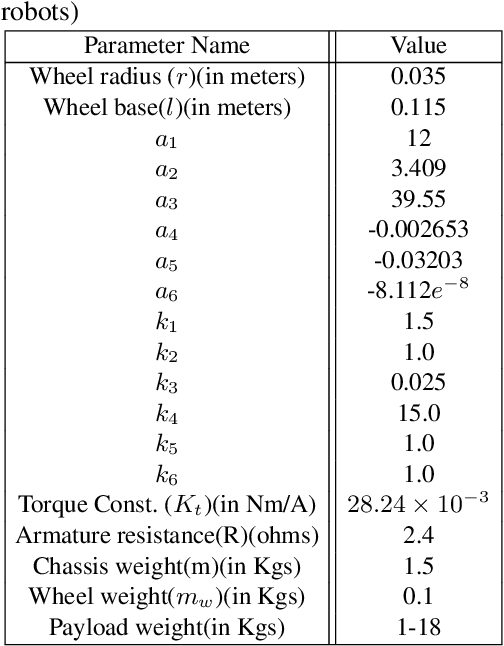
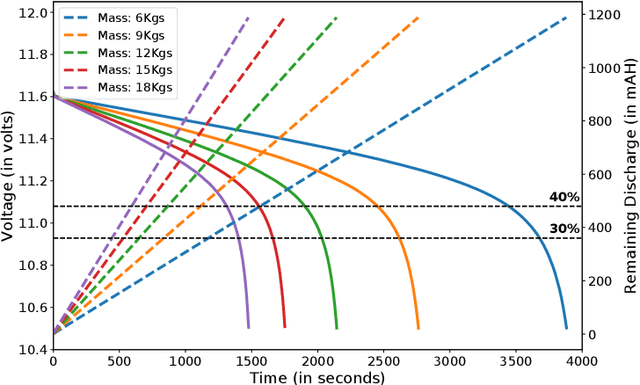
In this work, we present an algorithm for robot replacement to increase the operational time of a multi-robot payload transport system. Our system comprises a group of nonholonomic wheeled mobile robots traversing on a known trajectory. We design a multi-robot system with loosely coupled robots that ensures the system lasts much longer than the battery life of an individual robot. A system level optimization is presented, to decide on the operational state (charging or discharging) of each robot in the system. The charging state implies that the robot is not in a formation and is kept on charge whereas the discharging state implies that the robot is a part of the formation. Robot battery recharge hubs are present along the trajectory. Robots in the formation can be replaced at these hub locations with charged robots using a replacement mechanism. We showcase the efficacy of the proposed scheduling framework through simulations and experiments with real robots.
* 20 Pages
Motion Planning for Multi-Mobile-Manipulator Payload Transport Systems
Mar 18, 2019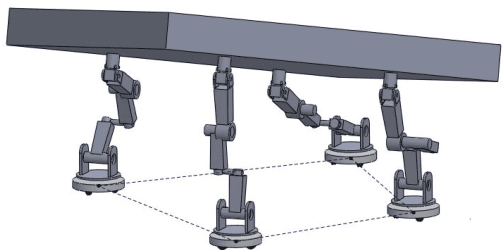
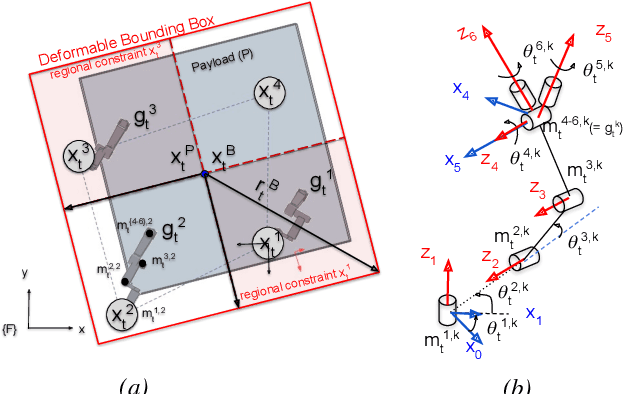
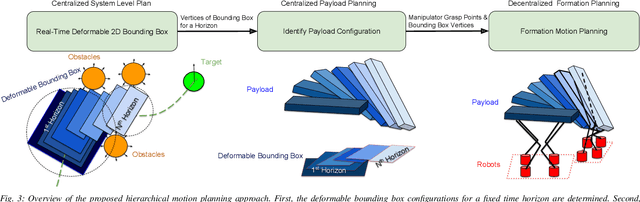
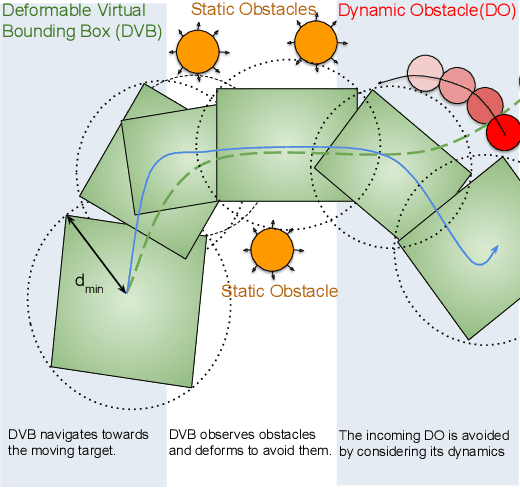
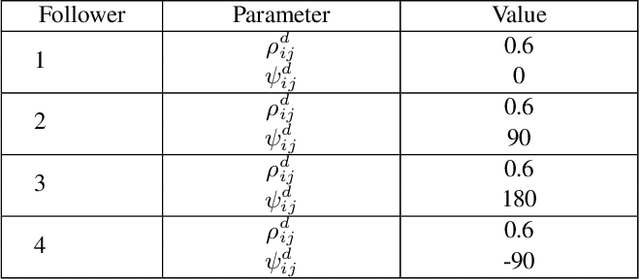
In this paper, a kinematic motion planning algorithm for cooperative spatial payload manipulation is presented. A hierarchical approach is introduced to compute real-time collision-free motion plans for a formation of mobile manipulator robots. Initially, collision-free configurations of a deformable 2-D virtual bounding box are identified, over a planning horizon, to define a convex workspace for the entire system. Then, 3-D payload configurations whose projections lie within the defined convex workspace are computed. Finally, a convex decentralized model-predictive controller is formulated to plan collision-free trajectories for the formation of mobile manipulators. This approach facilitates real-time motion planning for the system and is scalable in the number of robots. The algorithm is validated in simulated dynamic environments. Simulation video: https://youtu.be/9EKj7RwRs_4.
Active Perception based Formation Control for Multiple Aerial Vehicles
Jan 23, 2019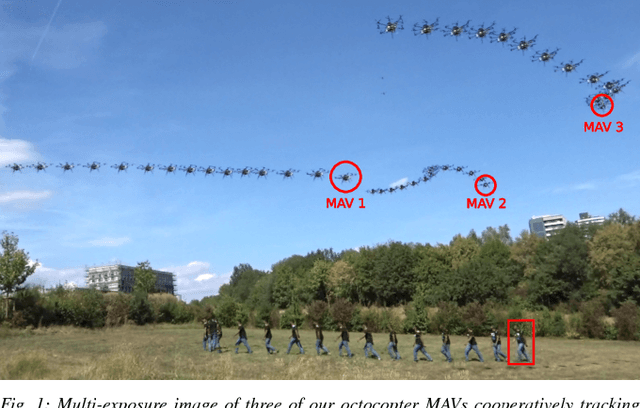
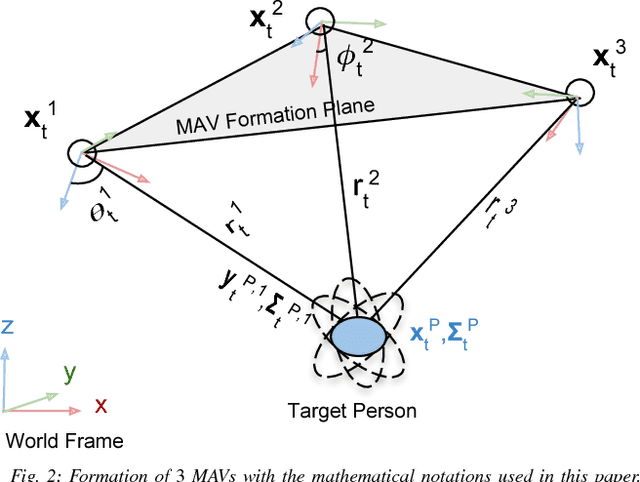
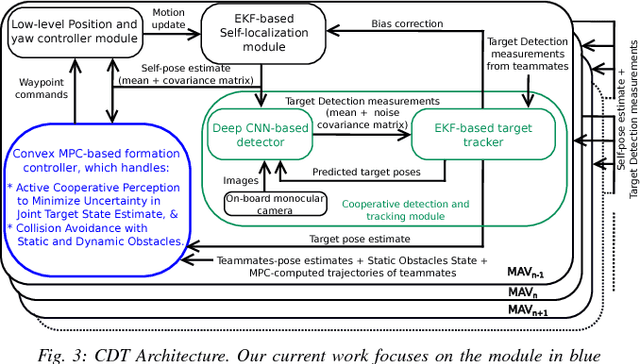
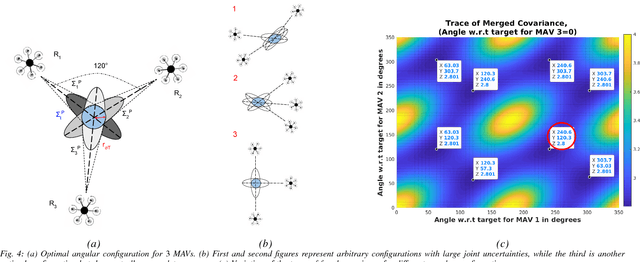
Autonomous motion capture (mocap) systems for outdoor scenarios involving flying or mobile cameras rely on i) a robotic front-end to track and follow a human subject in real-time while he/she performs physical activities, and ii) an algorithmic back-end that estimates full body human pose and shape from the saved videos. In this paper we present a novel front-end for our aerial mocap system that consists of multiple micro aerial vehicles (MAVs) with only on-board cameras and computation. In previous work, we presented an approach for cooperative detection and tracking (CDT) of a subject using multiple MAVs. However, it did not ensure optimal view-point configurations of the MAVs to minimize the uncertainty in the person's cooperatively tracked 3D position estimate. In this article we introduce an active approach for CDT. In contrast to cooperatively tracking only the 3D positions of the person, the MAVs can now actively compute optimal local motion plans, resulting in optimal view-point configurations, which minimize the uncertainty in the tracked estimate. We achieve this by decoupling the goal of active tracking as a convex quadratic objective and non-convex constraints corresponding to angular configurations of the MAVs w.r.t. the person. We derive it using Gaussian observation model assumptions within the CDT algorithm. We also show how we embed all the non-convex constraints, including those for dynamic and static obstacle avoidance, as external control inputs in the MPC dynamics. Multiple real robot experiments and comparisons involving 3 MAVs in several challenging scenarios are presented (video link : https://youtu.be/1qWW2zWvRhA). Extensive simulation results demonstrate the scalability and robustness of our approach. ROS-based source code is also provided.