 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZebraPose: Zebra Detection and Pose Estimation using only Synthetic Data
Aug 20, 2024Synthetic data is increasingly being used to address the lack of labeled images in uncommon domains for deep learning tasks. A prominent example is 2D pose estimation of animals, particularly wild species like zebras, for which collecting real-world data is complex and impractical. However, many approaches still require real images, consistency and style constraints, sophisticated animal models, and/or powerful pre-trained networks to bridge the syn-to-real gap. Moreover, they often assume that the animal can be reliably detected in images or videos, a hypothesis that often does not hold, e.g. in wildlife scenarios or aerial images. To solve this, we use synthetic data generated with a 3D photorealistic simulator to obtain the first synthetic dataset that can be used for both detection and 2D pose estimation of zebras without applying any of the aforementioned bridging strategies. Unlike previous works, we extensively train and benchmark our detection and 2D pose estimation models on multiple real-world and synthetic datasets using both pre-trained and non-pre-trained backbones. These experiments show how the models trained from scratch and only with synthetic data can consistently generalize to real-world images of zebras in both tasks. Moreover, we show it is possible to easily generalize those same models to 2D pose estimation of horses with a minimal amount of real-world images to account for the domain transfer. Code, results, trained models; and the synthetic, training, and validation data, including 104K manually labeled frames, are provided as open-source at https://zebrapose.is.tue.mpg.de/
DynaPix SLAM: A Pixel-Based Dynamic SLAM Approach
Sep 18, 2023In static environments, visual simultaneous localization and mapping (V-SLAM) methods achieve remarkable performance. However, moving objects severely affect core modules of such systems like state estimation and loop closure detection. To address this, dynamic SLAM approaches often use semantic information, geometric constraints, or optical flow to mask features associated with dynamic entities. These are limited by various factors such as a dependency on the quality of the underlying method, poor generalization to unknown or unexpected moving objects, and often produce noisy results, e.g. by masking static but movable objects or making use of predefined thresholds. In this paper, to address these trade-offs, we introduce a novel visual SLAM system, DynaPix, based on per-pixel motion probability values. Our approach consists of a new semantic-free probabilistic pixel-wise motion estimation module and an improved pose optimization process. Our per-pixel motion probability estimation combines a novel static background differencing method on both images and optical flows from splatted frames. DynaPix fully integrates those motion probabilities into both map point selection and weighted bundle adjustment within the tracking and optimization modules of ORB-SLAM2. We evaluate DynaPix against ORB-SLAM2 and DynaSLAM on both GRADE and TUM-RGBD datasets, obtaining lower errors and longer trajectory tracking times. We will release both source code and data upon acceptance of this work.
Simulation of Dynamic Environments for SLAM
May 07, 2023



Simulation engines are widely adopted in robotics. However, they lack either full simulation control, ROS integration, realistic physics, or photorealism. Recently, synthetic data generation and realistic rendering has advanced tasks like target tracking and human pose estimation. However, when focusing on vision applications, there is usually a lack of information like sensor measurements or time continuity. On the other hand, simulations for most robotics tasks are performed in (semi)static environments, with specific sensors and low visual fidelity. To solve this, we introduced in our previous work a fully customizable framework for generating realistic animated dynamic environments (GRADE) [1]. We use GRADE to generate an indoor dynamic environment dataset and then compare multiple SLAM algorithms on different sequences. By doing that, we show how current research over-relies on known benchmarks, failing to generalize. Our tests with refined YOLO and Mask R-CNN models provide further evidence that additional research in dynamic SLAM is necessary. The code, results, and generated data are provided as open-source at https://eliabntt.github.io/grade-rrSimulation of Dynamic Environments for SLAM
Learning from synthetic data generated with GRADE
May 07, 2023



Recently, synthetic data generation and realistic rendering has advanced tasks like target tracking and human pose estimation. Simulations for most robotics applications are obtained in (semi)static environments, with specific sensors and low visual fidelity. To solve this, we present a fully customizable framework for generating realistic animated dynamic environments (GRADE) for robotics research, first introduced in [1]. GRADE supports full simulation control, ROS integration, realistic physics, while being in an engine that produces high visual fidelity images and ground truth data. We use GRADE to generate a dataset focused on indoor dynamic scenes with people and flying objects. Using this, we evaluate the performance of YOLO and Mask R-CNN on the tasks of segmenting and detecting people. Our results provide evidence that using data generated with GRADE can improve the model performance when used for a pre-training step. We also show that, even training using only synthetic data, can generalize well to real-world images in the same application domain such as the ones from the TUM-RGBD dataset. The code, results, trained models, and the generated data are provided as open-source at https://eliabntt.github.io/grade-rr.
* 5 pages, 5 tables, 2 figures. Accepted for the ICRA 2023 workshop Pretraining for Robotics (https://microsoft.github.io/robotics.pretraining.workshop.icra/). arXiv admin note: substantial text overlap with arXiv:2303.04466
Synthetic Data-based Detection of Zebras in Drone Imagery
Apr 30, 2023



Datasets that allow the training of common objects or human detectors are widely available. These come in the form of labelled real-world images and require either a significant amount of human effort, with a high probability of errors such as missing labels, or very constrained scenarios, e.g. VICON systems. Likewise, uncommon scenarios, like aerial views, animals, like wild zebras, or difficult-to-obtain information as human shapes, are hardly available. To overcome this, usage of synthetic data generation with realistic rendering technologies has recently gained traction and advanced tasks like target tracking and human pose estimation. However, subjects such as wild animals are still usually not well represented in such datasets. In this work, we first show that a pre-trained YOLO detector can not identify zebras in real images recorded from aerial viewpoints. To solve this, we present an approach for training an animal detector using only synthetic data. We start by generating a novel synthetic zebra dataset using GRADE, a state-of-the-art framework for data generation. The dataset includes RGB, depth, skeletal joint locations, pose, shape and instance segmentations for each subject. We use this to train a YOLO detector from scratch. Through extensive evaluations of our model with real-world data from i) limited datasets available on the internet and ii) a new one collected and manually labelled by us, we show that we can detect zebras by using only synthetic data during training. The code, results, trained models, and both the generated and training data are provided as open-source at https://keeper.mpdl.mpg.de/d/12abb3bb6b12491480d5/.
GRADE: Generating Realistic Animated Dynamic Environments for Robotics Research
Mar 08, 2023
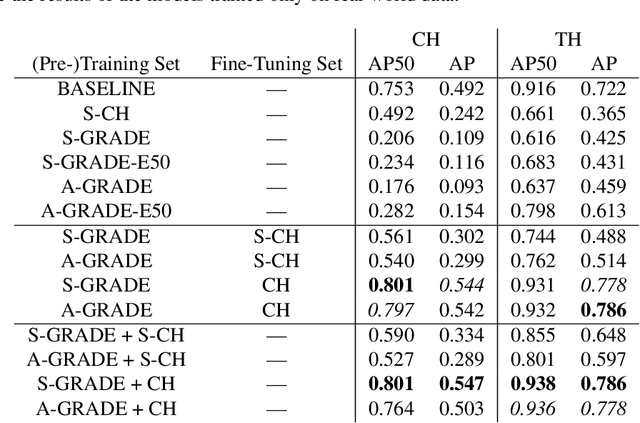

Simulation engines like Gazebo, Unity and Webots are widely adopted in robotics. However, they lack either full simulation control, ROS integration, realistic physics, or photorealism. Recently, synthetic data generation and realistic rendering advanced tasks like target tracking and human pose estimation. However, when focusing on vision applications, there is usually a lack of information like sensor measurements (e.g. IMU, LiDAR, joint state), or time continuity. On the other hand, simulations for most robotics applications are obtained in (semi)static environments, with specific sensor settings and low visual fidelity. In this work, we present a solution to these issues with a fully customizable framework for generating realistic animated dynamic environments (GRADE) for robotics research. The data produced can be post-processed, e.g. to add noise, and easily expanded with new information using the tools that we provide. To demonstrate GRADE, we use it to generate an indoor dynamic environment dataset and then compare different SLAM algorithms on the produced sequences. By doing that, we show how current research over-relies on well-known benchmarks and fails to generalize. Furthermore, our tests with YOLO and Mask R-CNN provide evidence that our data can improve training performance and generalize to real sequences. Finally, we show GRADE's flexibility by using it for indoor active SLAM, with diverse environment sources, and in a multi-robot scenario. In doing that, we employ different control, asset placement, and simulation techniques. The code, results, implementation details, and generated data are provided as open-source. The main project page is https://eliabntt.github.io/grade-rr while the accompanying video can be found at https://youtu.be/cmywCSD-9TU.
AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation
Jan 20, 2022
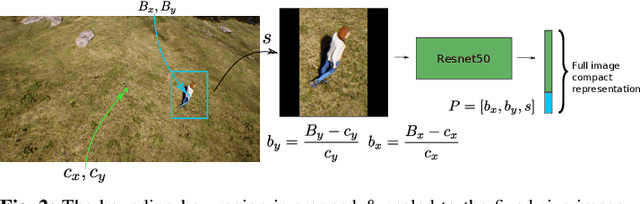


In this letter, we present a novel markerless 3D human motion capture (MoCap) system for unstructured, outdoor environments that uses a team of autonomous unmanned aerial vehicles (UAVs) with on-board RGB cameras and computation. Existing methods are limited by calibrated cameras and off-line processing. Thus, we present the first method (AirPose) to estimate human pose and shape using images captured by multiple extrinsically uncalibrated flying cameras. AirPose itself calibrates the cameras relative to the person instead of relying on any pre-calibration. It uses distributed neural networks running on each UAV that communicate viewpoint-independent information with each other about the person (i.e., their 3D shape and articulated pose). The person's shape and pose are parameterized using the SMPL-X body model, resulting in a compact representation, that minimizes communication between the UAVs. The network is trained using synthetic images of realistic virtual environments, and fine-tuned on a small set of real images. We also introduce an optimization-based post-processing method (AirPose$^{+}$) for offline applications that require higher MoCap quality. We make our method's code and data available for research at https://github.com/robot-perception-group/AirPose. A video describing the approach and results is available at https://youtu.be/xLYe1TNHsfs.
Active Visual SLAM with independently rotating camera
May 19, 2021
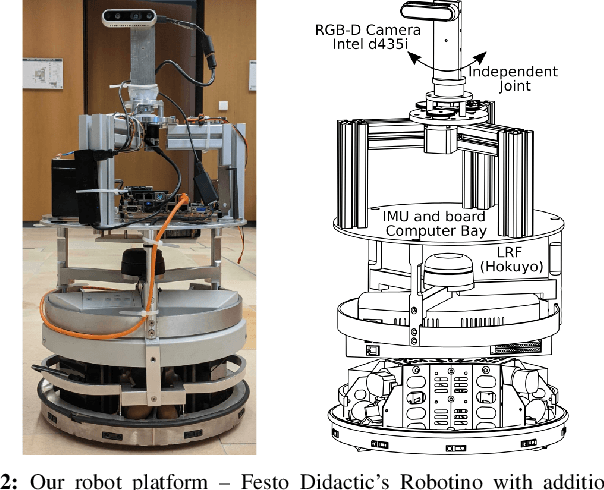
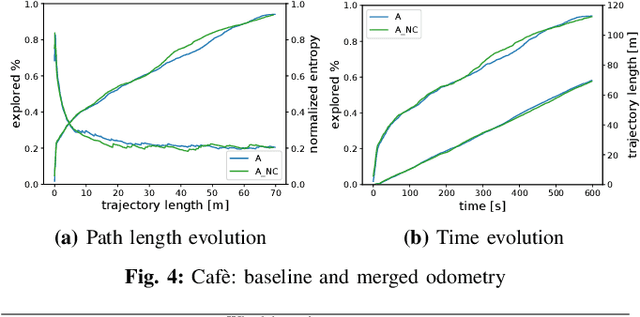
In active Visual-SLAM (V-SLAM), a robot relies on the information retrieved by its cameras to control its own movements for autonomous mapping of the environment. Cameras are usually statically linked to the robot's body, limiting the extra degrees of freedom for visual information acquisition. In this work, we overcome the aforementioned problem by introducing and leveraging an independently rotating camera on the robot base. This enables us to continuously control the heading of the camera, obtaining the desired optimal orientation for active V-SLAM, without rotating the robot itself. However, this additional degree of freedom introduces additional estimation uncertainties, which need to be accounted for. We do this by extending our robot's state estimate to include the camera state and jointly estimate the uncertainties. We develop our method based on a state-of-the-art active V-SLAM approach for omnidirectional robots, and evaluate it through rigorous simulation and real robot experiments. We obtain more accurate maps, with lower energy consumption, while maintaining the benefits of the active approach with respect to the baseline. We also demonstrate how our method easily generalizes to other non-omnidirectional robotic platforms, which was a limitation of the previous approach. Code and implementation details are provided as open-source.
iRotate: Active Visual SLAM for Omnidirectional Robots
Mar 22, 2021

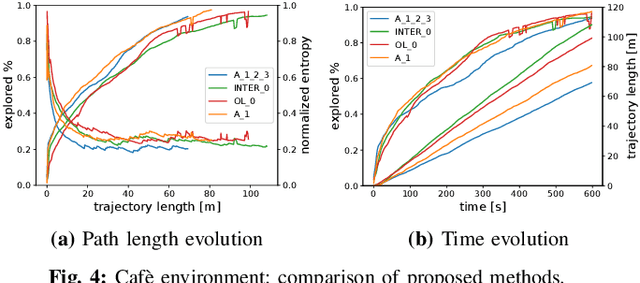
In this letter, we present an active visual SLAM approach for omnidirectional robots. The goal is to generate control commands that allow such a robot to simultaneously localize itself and map an unknown environment while maximizing the amount of information gained and consume as little energy as possible. Leveraging the robot's independent translation and rotation control, we introduce a multi-layered approach for active V-SLAM. The top layer decides on informative goal locations and generates highly informative paths to them. The second and third layers actively re-plan and execute the path, exploiting the continuously updated map. Moreover, they allow the robot to maximize its visibility of 3D visual features in the environment. Through rigorous simulations, real robot experiments and comparisons with the state-of-the-art methods, we demonstrate that our approach achieves similar coverage and lesser overall map entropy while keeping the traversed distance up to 36% less than the other methods. Code and implementation details are provided as open-source.
AirCapRL: Autonomous Aerial Human Motion Capture using Deep Reinforcement Learning
Aug 01, 2020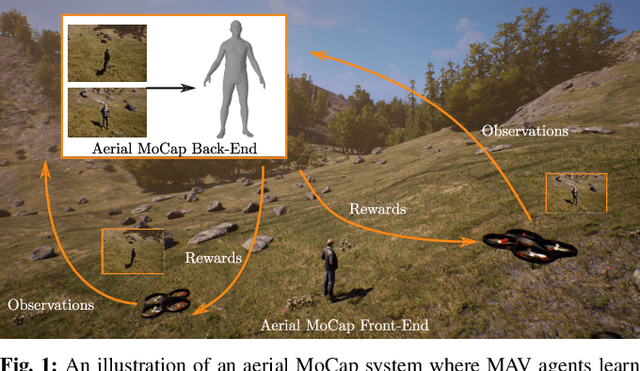



In this letter, we introduce a deep reinforcement learning (RL) based multi-robot formation controller for the task of autonomous aerial human motion capture (MoCap). We focus on vision-based MoCap, where the objective is to estimate the trajectory of body pose and shape of a single moving person using multiple micro aerial vehicles. State-of-the-art solutions to this problem are based on classical control methods, which depend on hand-crafted system and observation models. Such models are difficult to derive and generalize across different systems. Moreover, the non-linearity and non-convexities of these models lead to sub-optimal controls. In our work, we formulate this problem as a sequential decision making task to achieve the vision-based motion capture objectives, and solve it using a deep neural network-based RL method. We leverage proximal policy optimization (PPO) to train a stochastic decentralized control policy for formation control. The neural network is trained in a parallelized setup in synthetic environments. We performed extensive simulation experiments to validate our approach. Finally, real-robot experiments demonstrate that our policies generalize to real world conditions. Video Link: https://bit.ly/38SJfjo Supplementary: https://bit.ly/3evfo1O