 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartMocap: Joint Estimation of Human and Camera Motion using Uncalibrated RGB Cameras
Sep 28, 2022
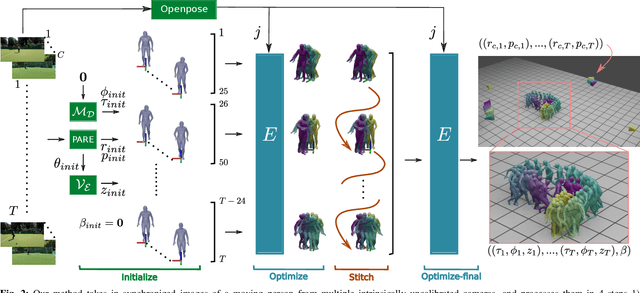

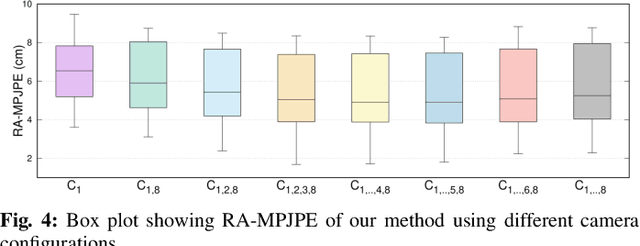
Markerless human motion capture (mocap) from multiple RGB cameras is a widely studied problem. Existing methods either need calibrated cameras or calibrate them relative to a static camera, which acts as the reference frame for the mocap system. The calibration step has to be done a priori for every capture session, which is a tedious process, and re-calibration is required whenever cameras are intentionally or accidentally moved. In this paper, we propose a mocap method which uses multiple static and moving extrinsically uncalibrated RGB cameras. The key components of our method are as follows. First, since the cameras and the subject can move freely, we select the ground plane as a common reference to represent both the body and the camera motions unlike existing methods which represent bodies in the camera coordinate. Second, we learn a probability distribution of short human motion sequences ($\sim$1sec) relative to the ground plane and leverage it to disambiguate between the camera and human motion. Third, we use this distribution as a motion prior in a novel multi-stage optimization approach to fit the SMPL human body model and the camera poses to the human body keypoints on the images. Finally, we show that our method can work on a variety of datasets ranging from aerial cameras to smartphones. It also gives more accurate results compared to the state-of-the-art on the task of monocular human mocap with a static camera. Our code is available for research purposes on https://github.com/robot-perception-group/SmartMocap.
AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation
Jan 20, 2022
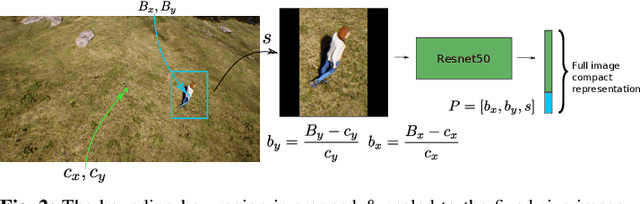


In this letter, we present a novel markerless 3D human motion capture (MoCap) system for unstructured, outdoor environments that uses a team of autonomous unmanned aerial vehicles (UAVs) with on-board RGB cameras and computation. Existing methods are limited by calibrated cameras and off-line processing. Thus, we present the first method (AirPose) to estimate human pose and shape using images captured by multiple extrinsically uncalibrated flying cameras. AirPose itself calibrates the cameras relative to the person instead of relying on any pre-calibration. It uses distributed neural networks running on each UAV that communicate viewpoint-independent information with each other about the person (i.e., their 3D shape and articulated pose). The person's shape and pose are parameterized using the SMPL-X body model, resulting in a compact representation, that minimizes communication between the UAVs. The network is trained using synthetic images of realistic virtual environments, and fine-tuned on a small set of real images. We also introduce an optimization-based post-processing method (AirPose$^{+}$) for offline applications that require higher MoCap quality. We make our method's code and data available for research at https://github.com/robot-perception-group/AirPose. A video describing the approach and results is available at https://youtu.be/xLYe1TNHsfs.
AirCapRL: Autonomous Aerial Human Motion Capture using Deep Reinforcement Learning
Aug 01, 2020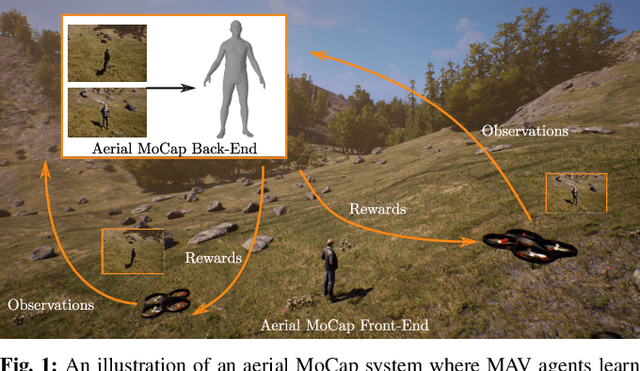



In this letter, we introduce a deep reinforcement learning (RL) based multi-robot formation controller for the task of autonomous aerial human motion capture (MoCap). We focus on vision-based MoCap, where the objective is to estimate the trajectory of body pose and shape of a single moving person using multiple micro aerial vehicles. State-of-the-art solutions to this problem are based on classical control methods, which depend on hand-crafted system and observation models. Such models are difficult to derive and generalize across different systems. Moreover, the non-linearity and non-convexities of these models lead to sub-optimal controls. In our work, we formulate this problem as a sequential decision making task to achieve the vision-based motion capture objectives, and solve it using a deep neural network-based RL method. We leverage proximal policy optimization (PPO) to train a stochastic decentralized control policy for formation control. The neural network is trained in a parallelized setup in synthetic environments. We performed extensive simulation experiments to validate our approach. Finally, real-robot experiments demonstrate that our policies generalize to real world conditions. Video Link: https://bit.ly/38SJfjo Supplementary: https://bit.ly/3evfo1O