 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Sampling by Combining Diffusion Models with Annealed Langevin Dynamics
Oct 30, 2025Given a noisy linear measurement $y = Ax + \xi$ of a distribution $p(x)$, and a good approximation to the prior $p(x)$, when can we sample from the posterior $p(x \mid y)$? Posterior sampling provides an accurate and fair framework for tasks such as inpainting, deblurring, and MRI reconstruction, and several heuristics attempt to approximate it. Unfortunately, approximate posterior sampling is computationally intractable in general. To sidestep this hardness, we focus on (local or global) log-concave distributions $p(x)$. In this regime, Langevin dynamics yields posterior samples when the exact scores of $p(x)$ are available, but it is brittle to score--estimation error, requiring an MGF bound (sub-exponential error). By contrast, in the unconditional setting, diffusion models succeed with only an $L^2$ bound on the score error. We prove that combining diffusion models with an annealed variant of Langevin dynamics achieves conditional sampling in polynomial time using merely an $L^4$ bound on the score error.
BirdRecorder's AI on Sky: Safeguarding birds of prey by detection and classification of tiny objects around wind turbines
Aug 25, 2025



The urgent need for renewable energy expansion, particularly wind power, is hindered by conflicts with wildlife conservation. To address this, we developed BirdRecorder, an advanced AI-based anti-collision system to protect endangered birds, especially the red kite (Milvus milvus). Integrating robotics, telemetry, and high-performance AI algorithms, BirdRecorder aims to detect, track, and classify avian species within a range of 800 m to minimize bird-turbine collisions. BirdRecorder integrates advanced AI methods with optimized hardware and software architectures to enable real-time image processing. Leveraging Single Shot Detector (SSD) for detection, combined with specialized hardware acceleration and tracking algorithms, our system achieves high detection precision while maintaining the speed necessary for real-time decision-making. By combining these components, BirdRecorder outperforms existing approaches in both accuracy and efficiency. In this paper, we summarize results on field tests and performance of the BirdRecorder system. By bridging the gap between renewable energy expansion and wildlife conservation, BirdRecorder contributes to a more sustainable coexistence of technology and nature.
Near-Polynomially Competitive Active Logistic Regression
Mar 07, 2025


We address the problem of active logistic regression in the realizable setting. It is well known that active learning can require exponentially fewer label queries compared to passive learning, in some cases using $\log \frac{1}{\eps}$ rather than $\poly(1/\eps)$ labels to get error $\eps$ larger than the optimum. We present the first algorithm that is polynomially competitive with the optimal algorithm on every input instance, up to factors polylogarithmic in the error and domain size. In particular, if any algorithm achieves label complexity polylogarithmic in $\eps$, so does ours. Our algorithm is based on efficient sampling and can be extended to learn more general class of functions. We further support our theoretical results with experiments demonstrating performance gains for logistic regression compared to existing active learning algorithms.
Phi-4 Technical Report
Dec 12, 2024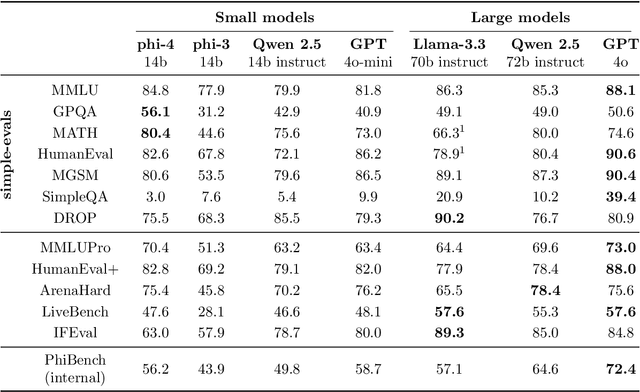
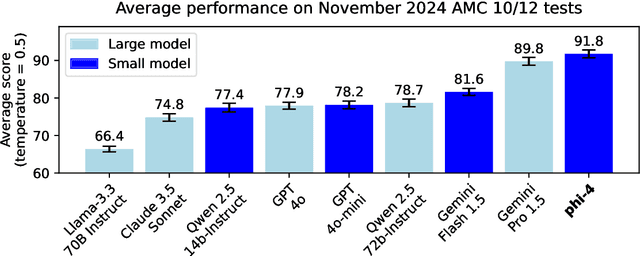

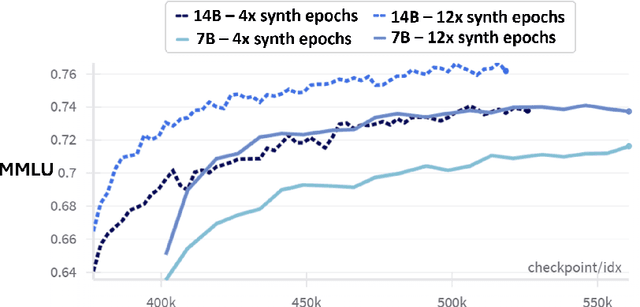
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Spectral Guarantees for Adversarial Streaming PCA
Aug 19, 2024In streaming PCA, we see a stream of vectors $x_1, \dotsc, x_n \in \mathbb{R}^d$ and want to estimate the top eigenvector of their covariance matrix. This is easier if the spectral ratio $R = \lambda_1 / \lambda_2$ is large. We ask: how large does $R$ need to be to solve streaming PCA in $\widetilde{O}(d)$ space? Existing algorithms require $R = \widetilde{\Omega}(d)$. We show: (1) For all mergeable summaries, $R = \widetilde{\Omega}(\sqrt{d})$ is necessary. (2) In the insertion-only model, a variant of Oja's algorithm gets $o(1)$ error for $R = O(\log n \log d)$. (3) No algorithm with $o(d^2)$ space gets $o(1)$ error for $R = O(1)$. Our analysis is the first application of Oja's algorithm to adversarial streams. It is also the first algorithm for adversarial streaming PCA that is designed for a spectral, rather than Frobenius, bound on the tail; and the bound it needs is exponentially better than is possible by adapting a Frobenius guarantee.
Airship Formations for Animal Motion Capture and Behavior Analysis
Apr 13, 2024Using UAVs for wildlife observation and motion capture offers manifold advantages for studying animals in the wild, especially grazing herds in open terrain. The aerial perspective allows observation at a scale and depth that is not possible on the ground, offering new insights into group behavior. However, the very nature of wildlife field-studies puts traditional fixed wing and multi-copter systems to their limits: limited flight time, noise and safety aspects affect their efficacy, where lighter than air systems can remain on station for many hours. Nevertheless, airships are challenging from a ground handling perspective as well as from a control point of view, being voluminous and highly affected by wind. In this work, we showcase a system designed to use airship formations to track, follow, and visually record wild horses from multiple angles, including airship design, simulation, control, on board computer vision, autonomous operation and practical aspects of field experiments.
Diffusion Posterior Sampling is Computationally Intractable
Feb 20, 2024
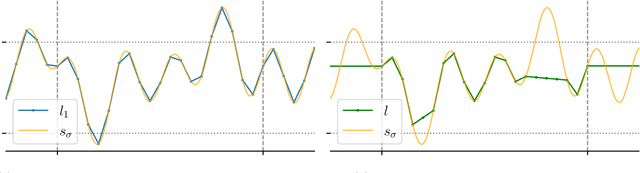
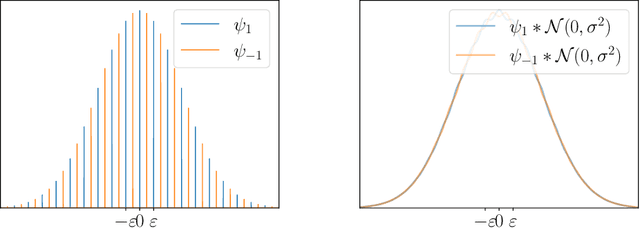
Diffusion models are a remarkably effective way of learning and sampling from a distribution $p(x)$. In posterior sampling, one is also given a measurement model $p(y \mid x)$ and a measurement $y$, and would like to sample from $p(x \mid y)$. Posterior sampling is useful for tasks such as inpainting, super-resolution, and MRI reconstruction, so a number of recent works have given algorithms to heuristically approximate it; but none are known to converge to the correct distribution in polynomial time. In this paper we show that posterior sampling is \emph{computationally intractable}: under the most basic assumption in cryptography -- that one-way functions exist -- there are instances for which \emph{every} algorithm takes superpolynomial time, even though \emph{unconditional} sampling is provably fast. We also show that the exponential-time rejection sampling algorithm is essentially optimal under the stronger plausible assumption that there are one-way functions that take exponential time to invert.
Sample-Efficient Training for Diffusion
Nov 23, 2023Score-based diffusion models have become the most popular approach to deep generative modeling of images, largely due to their empirical performance and reliability. Recently, a number of theoretical works \citep{chen2022, Chen2022ImprovedAO, Chenetal23flowode, benton2023linear} have shown that diffusion models can efficiently sample, assuming $L^2$-accurate score estimates. The score-matching objective naturally approximates the true score in $L^2$, but the sample complexity of existing bounds depends \emph{polynomially} on the data radius and desired Wasserstein accuracy. By contrast, the time complexity of sampling is only logarithmic in these parameters. We show that estimating the score in $L^2$ \emph{requires} this polynomial dependence, but that a number of samples that scales polylogarithmically in the Wasserstein accuracy actually do suffice for sampling. We show that with a polylogarithmic number of samples, the ERM of the score-matching objective is $L^2$ accurate on all but a probability $\delta$ fraction of the true distribution, and that this weaker guarantee is sufficient for efficient sampling.
Sharp Noisy Binary Search with Monotonic Probabilities
Nov 01, 2023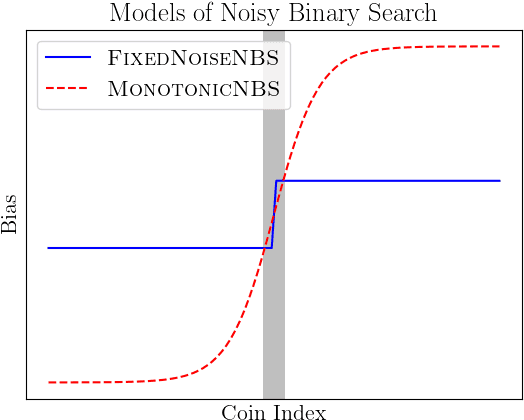

We revisit the noisy binary search model of Karp and Kleinberg, in which we have $n$ coins with unknown probabilities $p_i$ that we can flip. The coins are sorted by increasing $p_i$, and we would like to find where the probability crosses (to within $\varepsilon$) of a target value $\tau$. This generalized the fixed-noise model of Burnashev and Zigangirov , in which $p_i = \frac{1}{2} \pm \varepsilon$, to a setting where coins near the target may be indistinguishable from it. Karp and Kleinberg showed that $\Theta(\frac{1}{\varepsilon^2} \log n)$ samples are necessary and sufficient for this task. We produce a practical algorithm by solving two theoretical challenges: high-probability behavior and sharp constants. We give an algorithm that succeeds with probability $1-\delta$ from \[ \frac{1}{C_{\tau, \varepsilon}} \cdot \left(\lg n + O(\log^{2/3} n \log^{1/3} \frac{1}{\delta} + \log \frac{1}{\delta})\right) \] samples, where $C_{\tau, \varepsilon}$ is the optimal such constant achievable. For $\delta > n^{-o(1)}$ this is within $1 + o(1)$ of optimal, and for $\delta \ll 1$ it is the first bound within constant factors of optimal.
A Competitive Algorithm for Agnostic Active Learning
Oct 28, 2023For some hypothesis classes and input distributions, active agnostic learning needs exponentially fewer samples than passive learning; for other classes and distributions, it offers little to no improvement. The most popular algorithms for agnostic active learning express their performance in terms of a parameter called the disagreement coefficient, but it is known that these algorithms are inefficient on some inputs. We take a different approach to agnostic active learning, getting an algorithm that is competitive with the optimal algorithm for any binary hypothesis class $H$ and distribution $D_X$ over $X$. In particular, if any algorithm can use $m^*$ queries to get $O(\eta)$ error, then our algorithm uses $O(m^* \log |H|)$ queries to get $O(\eta)$ error. Our algorithm lies in the vein of the splitting-based approach of Dasgupta [2004], which gets a similar result for the realizable ($\eta = 0$) setting. We also show that it is NP-hard to do better than our algorithm's $O(\log |H|)$ overhead in general.