 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Posterior Sampling is Computationally Intractable
Feb 20, 2024
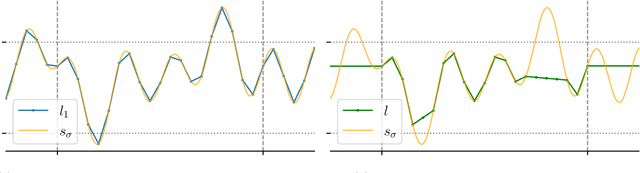
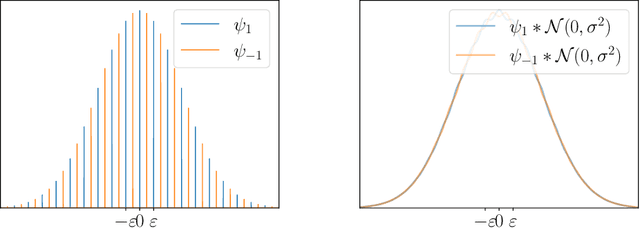
Diffusion models are a remarkably effective way of learning and sampling from a distribution $p(x)$. In posterior sampling, one is also given a measurement model $p(y \mid x)$ and a measurement $y$, and would like to sample from $p(x \mid y)$. Posterior sampling is useful for tasks such as inpainting, super-resolution, and MRI reconstruction, so a number of recent works have given algorithms to heuristically approximate it; but none are known to converge to the correct distribution in polynomial time. In this paper we show that posterior sampling is \emph{computationally intractable}: under the most basic assumption in cryptography -- that one-way functions exist -- there are instances for which \emph{every} algorithm takes superpolynomial time, even though \emph{unconditional} sampling is provably fast. We also show that the exponential-time rejection sampling algorithm is essentially optimal under the stronger plausible assumption that there are one-way functions that take exponential time to invert.
Sample-Efficient Training for Diffusion
Nov 23, 2023Score-based diffusion models have become the most popular approach to deep generative modeling of images, largely due to their empirical performance and reliability. Recently, a number of theoretical works \citep{chen2022, Chen2022ImprovedAO, Chenetal23flowode, benton2023linear} have shown that diffusion models can efficiently sample, assuming $L^2$-accurate score estimates. The score-matching objective naturally approximates the true score in $L^2$, but the sample complexity of existing bounds depends \emph{polynomially} on the data radius and desired Wasserstein accuracy. By contrast, the time complexity of sampling is only logarithmic in these parameters. We show that estimating the score in $L^2$ \emph{requires} this polynomial dependence, but that a number of samples that scales polylogarithmically in the Wasserstein accuracy actually do suffice for sampling. We show that with a polylogarithmic number of samples, the ERM of the score-matching objective is $L^2$ accurate on all but a probability $\delta$ fraction of the true distribution, and that this weaker guarantee is sufficient for efficient sampling.
L1 Regression with Lewis Weights Subsampling
May 19, 2021We consider the problem of finding an approximate solution to $\ell_1$ regression while only observing a small number of labels. Given an $n \times d$ unlabeled data matrix $X$, we must choose a small set of $m \ll n$ rows to observe the labels of, then output an estimate $\widehat{\beta}$ whose error on the original problem is within a $1 + \varepsilon$ factor of optimal. We show that sampling from $X$ according to its Lewis weights and outputting the empirical minimizer succeeds with probability $1-\delta$ for $m > O(\frac{1}{\varepsilon^2} d \log \frac{d}{\varepsilon \delta})$. This is analogous to the performance of sampling according to leverage scores for $\ell_2$ regression, but with exponentially better dependence on $\delta$. We also give a corresponding lower bound of $\Omega(\frac{d}{\varepsilon^2} + (d + \frac{1}{\varepsilon^2}) \log\frac{1}{\delta})$.