 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Lower Bounds for Diffusion Sampling
Apr 12, 2026Diffusion models generate samples by iteratively querying learned score estimates. A rapidly growing literature focuses on accelerating sampling by minimizing the number of score evaluations, yet the information-theoretic limits of such acceleration remain unclear. In this work, we establish the first score query lower bounds for diffusion sampling. We prove that for $d$-dimensional distributions, given access to score estimates with polynomial accuracy $\varepsilon=d^{-O(1)}$ (in any $L^p$ sense), any sampling algorithm requires $\widetildeΩ(\sqrt{d})$ adaptive score queries. In particular, our proof shows that any sampler must search over $\widetildeΩ(\sqrt{d})$ distinct noise levels, providing a formal explanation for why multiscale noise schedules are necessary in practice.
Posterior Sampling by Combining Diffusion Models with Annealed Langevin Dynamics
Oct 30, 2025Given a noisy linear measurement $y = Ax + \xi$ of a distribution $p(x)$, and a good approximation to the prior $p(x)$, when can we sample from the posterior $p(x \mid y)$? Posterior sampling provides an accurate and fair framework for tasks such as inpainting, deblurring, and MRI reconstruction, and several heuristics attempt to approximate it. Unfortunately, approximate posterior sampling is computationally intractable in general. To sidestep this hardness, we focus on (local or global) log-concave distributions $p(x)$. In this regime, Langevin dynamics yields posterior samples when the exact scores of $p(x)$ are available, but it is brittle to score--estimation error, requiring an MGF bound (sub-exponential error). By contrast, in the unconditional setting, diffusion models succeed with only an $L^2$ bound on the score error. We prove that combining diffusion models with an annealed variant of Langevin dynamics achieves conditional sampling in polynomial time using merely an $L^4$ bound on the score error.
Spectral Guarantees for Adversarial Streaming PCA
Aug 19, 2024In streaming PCA, we see a stream of vectors $x_1, \dotsc, x_n \in \mathbb{R}^d$ and want to estimate the top eigenvector of their covariance matrix. This is easier if the spectral ratio $R = \lambda_1 / \lambda_2$ is large. We ask: how large does $R$ need to be to solve streaming PCA in $\widetilde{O}(d)$ space? Existing algorithms require $R = \widetilde{\Omega}(d)$. We show: (1) For all mergeable summaries, $R = \widetilde{\Omega}(\sqrt{d})$ is necessary. (2) In the insertion-only model, a variant of Oja's algorithm gets $o(1)$ error for $R = O(\log n \log d)$. (3) No algorithm with $o(d^2)$ space gets $o(1)$ error for $R = O(1)$. Our analysis is the first application of Oja's algorithm to adversarial streams. It is also the first algorithm for adversarial streaming PCA that is designed for a spectral, rather than Frobenius, bound on the tail; and the bound it needs is exponentially better than is possible by adapting a Frobenius guarantee.
Diffusion Posterior Sampling is Computationally Intractable
Feb 20, 2024
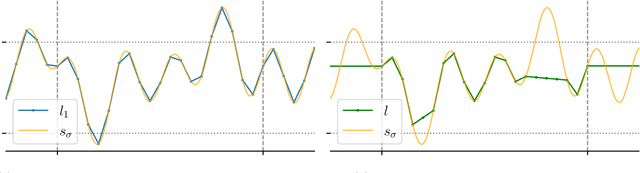
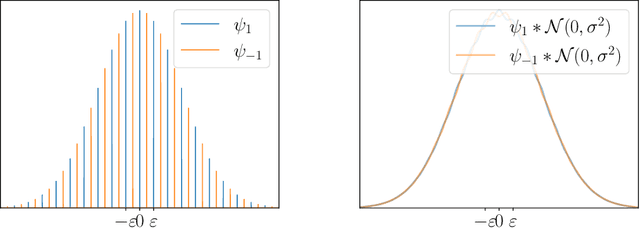
Diffusion models are a remarkably effective way of learning and sampling from a distribution $p(x)$. In posterior sampling, one is also given a measurement model $p(y \mid x)$ and a measurement $y$, and would like to sample from $p(x \mid y)$. Posterior sampling is useful for tasks such as inpainting, super-resolution, and MRI reconstruction, so a number of recent works have given algorithms to heuristically approximate it; but none are known to converge to the correct distribution in polynomial time. In this paper we show that posterior sampling is \emph{computationally intractable}: under the most basic assumption in cryptography -- that one-way functions exist -- there are instances for which \emph{every} algorithm takes superpolynomial time, even though \emph{unconditional} sampling is provably fast. We also show that the exponential-time rejection sampling algorithm is essentially optimal under the stronger plausible assumption that there are one-way functions that take exponential time to invert.
Sample-Efficient Training for Diffusion
Nov 23, 2023Score-based diffusion models have become the most popular approach to deep generative modeling of images, largely due to their empirical performance and reliability. Recently, a number of theoretical works \citep{chen2022, Chen2022ImprovedAO, Chenetal23flowode, benton2023linear} have shown that diffusion models can efficiently sample, assuming $L^2$-accurate score estimates. The score-matching objective naturally approximates the true score in $L^2$, but the sample complexity of existing bounds depends \emph{polynomially} on the data radius and desired Wasserstein accuracy. By contrast, the time complexity of sampling is only logarithmic in these parameters. We show that estimating the score in $L^2$ \emph{requires} this polynomial dependence, but that a number of samples that scales polylogarithmically in the Wasserstein accuracy actually do suffice for sampling. We show that with a polylogarithmic number of samples, the ERM of the score-matching objective is $L^2$ accurate on all but a probability $\delta$ fraction of the true distribution, and that this weaker guarantee is sufficient for efficient sampling.