 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Polynomially Competitive Active Logistic Regression
Mar 07, 2025


We address the problem of active logistic regression in the realizable setting. It is well known that active learning can require exponentially fewer label queries compared to passive learning, in some cases using $\log \frac{1}{\eps}$ rather than $\poly(1/\eps)$ labels to get error $\eps$ larger than the optimum. We present the first algorithm that is polynomially competitive with the optimal algorithm on every input instance, up to factors polylogarithmic in the error and domain size. In particular, if any algorithm achieves label complexity polylogarithmic in $\eps$, so does ours. Our algorithm is based on efficient sampling and can be extended to learn more general class of functions. We further support our theoretical results with experiments demonstrating performance gains for logistic regression compared to existing active learning algorithms.
Toward a Flexible Framework for Linear Representation Hypothesis Using Maximum Likelihood Estimation
Feb 22, 2025Linear representation hypothesis posits that high-level concepts are encoded as linear directions in the representation spaces of LLMs. Park et al. (2024) formalize this notion by unifying multiple interpretations of linear representation, such as 1-dimensional subspace representation and interventions, using a causal inner product. However, their framework relies on single-token counterfactual pairs and cannot handle ambiguous contrasting pairs, limiting its applicability to complex or context-dependent concepts. We introduce a new notion of binary concepts as unit vectors in a canonical representation space, and utilize LLMs' (neural) activation differences along with maximum likelihood estimation (MLE) to compute concept directions (i.e., steering vectors). Our method, Sum of Activation-base Normalized Difference (SAND), formalizes the use of activation differences modeled as samples from a von Mises-Fisher (vMF) distribution, providing a principled approach to derive concept directions. We extend the applicability of Park et al. (2024) by eliminating the dependency on unembedding representations and single-token pairs. Through experiments with LLaMA models across diverse concepts and benchmarks, we demonstrate that our lightweight approach offers greater flexibility, superior performance in activation engineering tasks like monitoring and manipulation.
Point-set Distances for Learning Representations of 3D Point Clouds
Feb 08, 2021

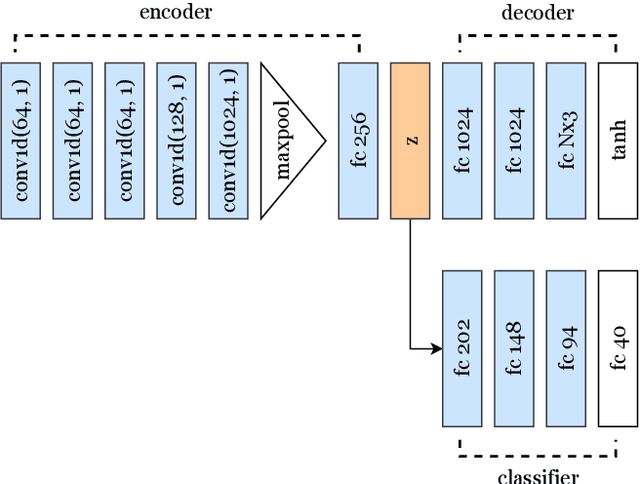
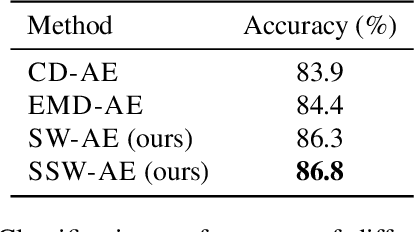
Learning an effective representation of 3D point clouds requires a good metric to measure the discrepancy between two 3D point sets, which is non-trivial due to their irregularity. Most of the previous works resort to using the Chamfer discrepancy or Earth Mover's distance, but those metrics are either ineffective in measuring the differences between point clouds or computationally expensive. In this paper, we conduct a systematic study with extensive experiments on distance metrics for 3D point clouds. From this study, we propose to use a variant of the Wasserstein distance, named the sliced Wasserstein distance, for learning representations of 3D point clouds. Experiments show that the sliced Wasserstein distance allows the neural network to learn a more efficient representation compared to the Chamfer discrepancy. We demonstrate the efficiency of the sliced Wasserstein metric on several tasks in 3D computer vision including training a point cloud autoencoder, generative modeling, transfer learning, and point cloud registration.
Detecting Hands and Recognizing Physical Contact in the Wild
Oct 19, 2020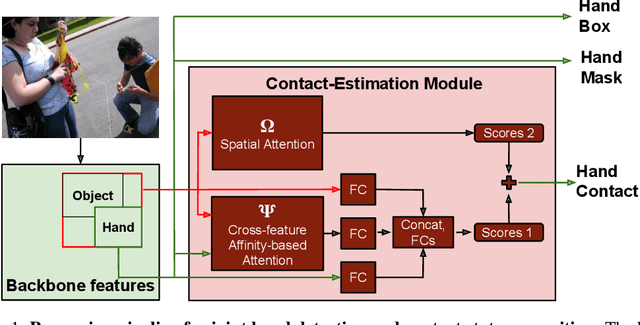
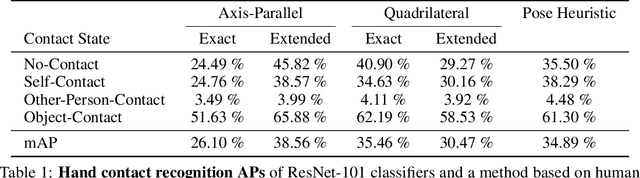
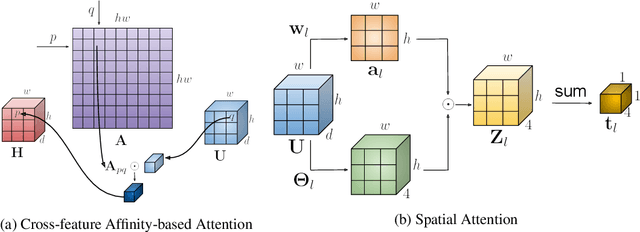
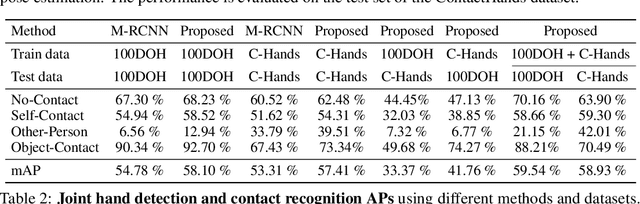
We investigate a new problem of detecting hands and recognizing their physical contact state in unconstrained conditions. This is a challenging inference task given the need to reason beyond the local appearance of hands. The lack of training annotations indicating which object or parts of an object the hand is in contact with further complicates the task. We propose a novel convolutional network based on Mask-RCNN that can jointly learn to localize hands and predict their physical contact to address this problem. The network uses outputs from another object detector to obtain locations of objects present in the scene. It uses these outputs and hand locations to recognize the hand's contact state using two attention mechanisms. The first attention mechanism is based on the hand and a region's affinity, enclosing the hand and the object, and densely pools features from this region to the hand region. The second attention module adaptively selects salient features from this plausible region of contact. To develop and evaluate our method's performance, we introduce a large-scale dataset called ContactHands, containing unconstrained images annotated with hand locations and contact states. The proposed network, including the parameters of attention modules, is end-to-end trainable. This network achieves approximately 7\% relative improvement over a baseline network that was built on the vanilla Mask-RCNN architecture and trained for recognizing hand contact states.
A Smart Security System with Face Recognition
Dec 03, 2018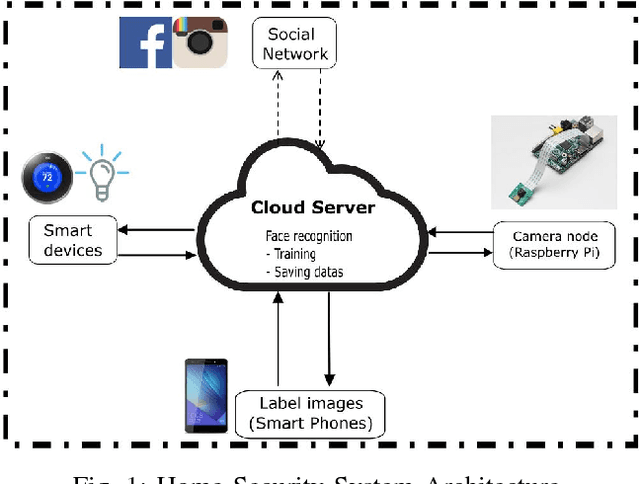

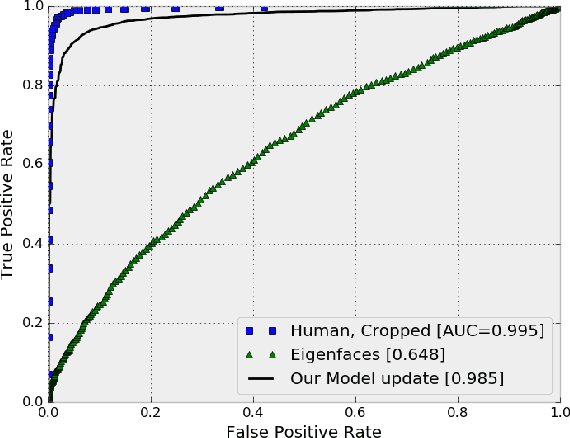
Web-based technology has improved drastically in the past decade. As a result, security technology has become a major help to protect our daily life. In this paper, we propose a robust security based on face recognition system (SoF). In particular, we develop this system to giving access into a home for authenticated users. The classifier is trained by using a new adaptive learning method. The training data are initially collected from social networks. The accuracy of the classifier is incrementally improved as the user starts using the system. A novel method has been introduced to improve the classifier model by human interaction and social media. By using a deep learning framework - TensorFlow, it will be easy to reuse the framework to adopt with many devices and applications.