 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFNet-4D: Joint Object Reconstruction and Flow Estimation from 4D Point Clouds
Mar 30, 2022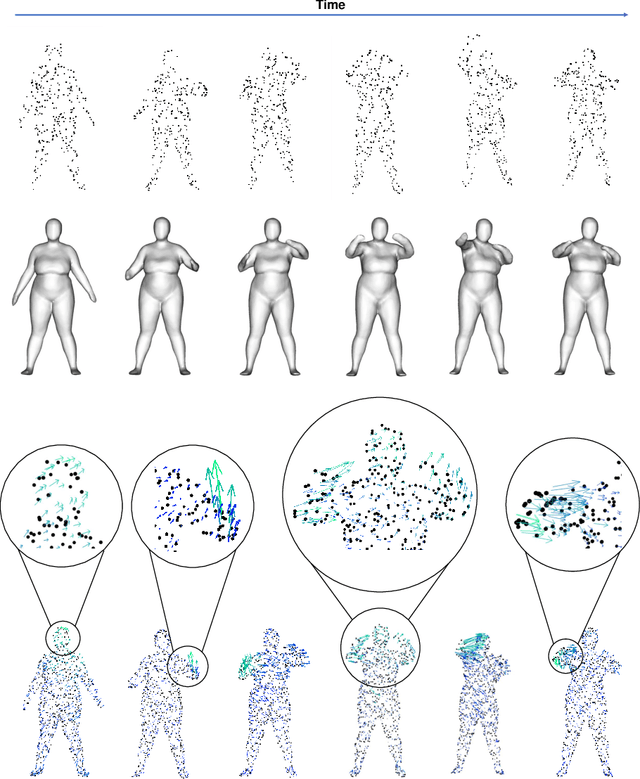
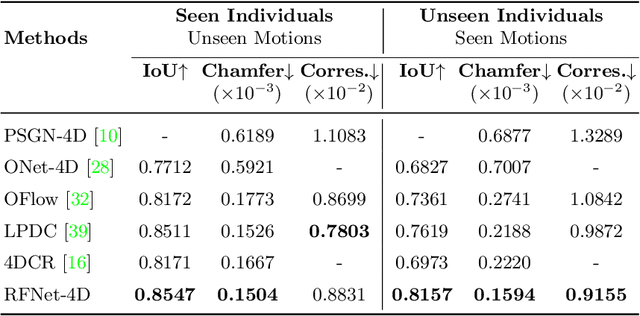
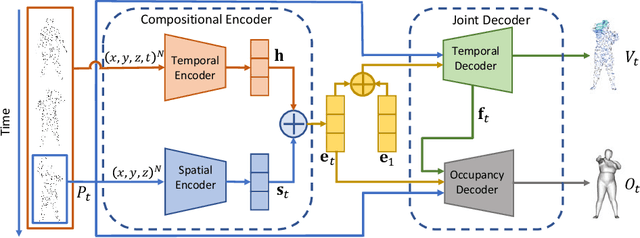
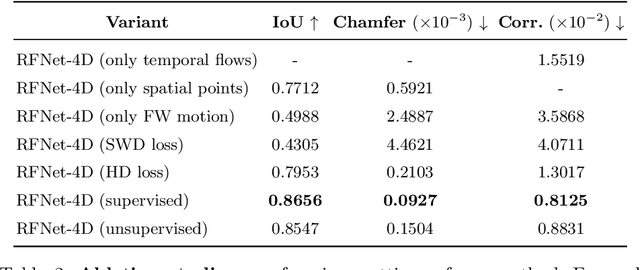
Object reconstruction from 3D point clouds has achieved impressive progress in the computer vision and computer graphics research field. However, reconstruction from time-varying point clouds (a.k.a. 4D point clouds) is generally overlooked. In this paper, we propose a new network architecture, namely RFNet-4D, that jointly reconstructs objects and their motion flows from 4D point clouds. The key insight is that simultaneously performing both tasks via learning spatial and temporal features from a sequence of point clouds can leverage individual tasks and lead to improved overall performance. The proposed network can be trained using both supervised and unsupervised learning. To prove this ability, we design a temporal vector field learning module using an unsupervised learning approach for flow estimation, leveraged by supervised learning of spatial structures for object reconstruction. Extensive experiments and analyses on benchmark dataset validated the effectiveness and efficiency of our method. As shown in experimental results, our method achieves state-of-the-art performance on both flow estimation and object reconstruction while performing much faster than existing methods in both training and inference.
Point-set Distances for Learning Representations of 3D Point Clouds
Feb 08, 2021

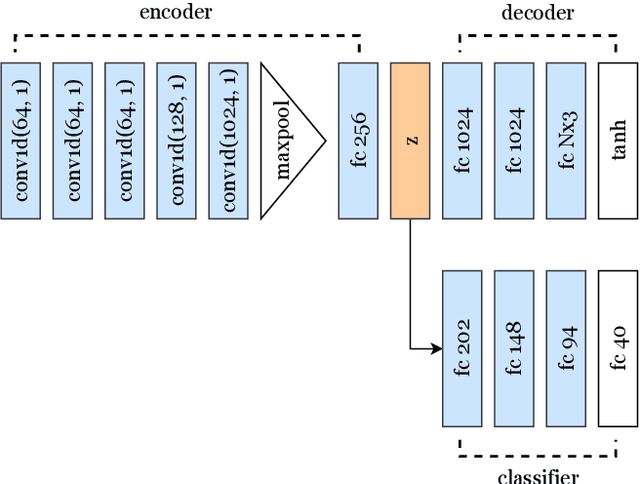
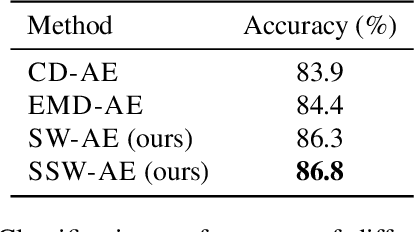
Learning an effective representation of 3D point clouds requires a good metric to measure the discrepancy between two 3D point sets, which is non-trivial due to their irregularity. Most of the previous works resort to using the Chamfer discrepancy or Earth Mover's distance, but those metrics are either ineffective in measuring the differences between point clouds or computationally expensive. In this paper, we conduct a systematic study with extensive experiments on distance metrics for 3D point clouds. From this study, we propose to use a variant of the Wasserstein distance, named the sliced Wasserstein distance, for learning representations of 3D point clouds. Experiments show that the sliced Wasserstein distance allows the neural network to learn a more efficient representation compared to the Chamfer discrepancy. We demonstrate the efficiency of the sliced Wasserstein metric on several tasks in 3D computer vision including training a point cloud autoencoder, generative modeling, transfer learning, and point cloud registration.
LCD: Learned Cross-Domain Descriptors for 2D-3D Matching
Nov 21, 2019

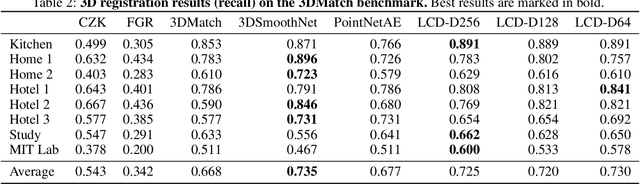

In this work, we present a novel method to learn a local cross-domain descriptor for 2D image and 3D point cloud matching. Our proposed method is a dual auto-encoder neural network that maps 2D and 3D input into a shared latent space representation. We show that such local cross-domain descriptors in the shared embedding are more discriminative than those obtained from individual training in 2D and 3D domains. To facilitate the training process, we built a new dataset by collecting $\approx 1.4$ millions of 2D-3D correspondences with various lighting conditions and settings from publicly available RGB-D scenes. Our descriptor is evaluated in three main experiments: 2D-3D matching, cross-domain retrieval, and sparse-to-dense depth estimation. Experimental results confirm the robustness of our approach as well as its competitive performance not only in solving cross-domain tasks but also in being able to generalize to solve sole 2D and 3D tasks. Our dataset and code are released publicly at \url{https://hkust-vgd.github.io/lcd}.
A*3D Dataset: Towards Autonomous Driving in Challenging Environments
Sep 17, 2019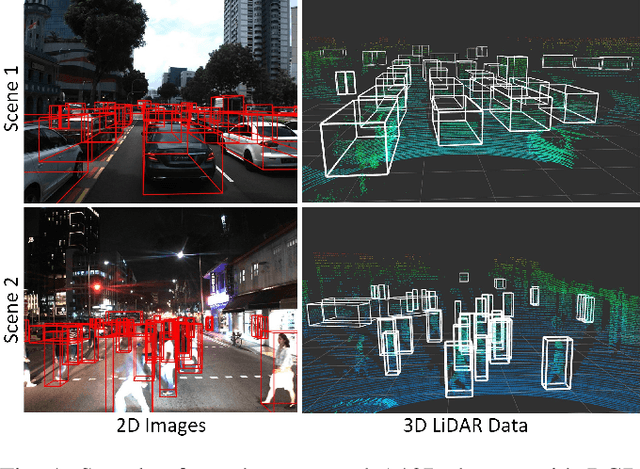
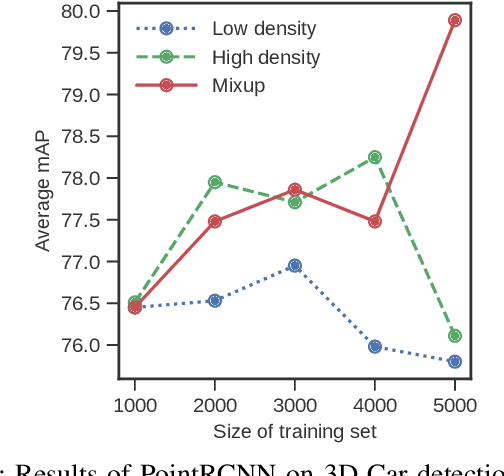
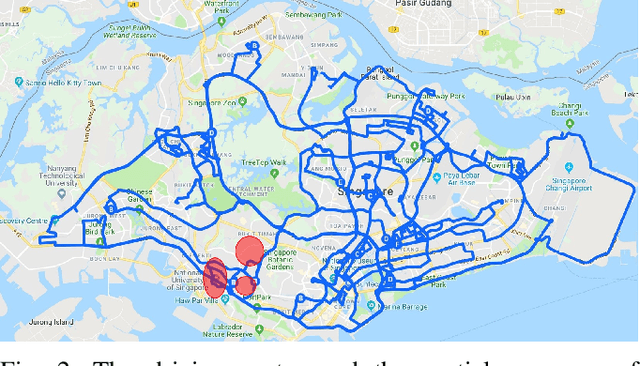
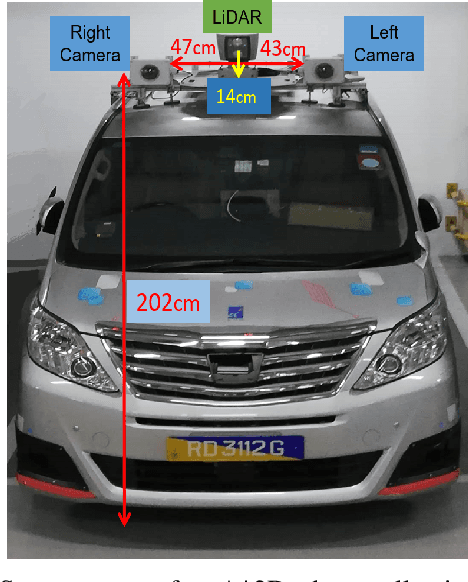
With the increasing global popularity of self-driving cars, there is an immediate need for challenging real-world datasets for benchmarking and training various computer vision tasks such as 3D object detection. Existing datasets either represent simple scenarios or provide only day-time data. In this paper, we introduce a new challenging A*3D dataset which consists of RGB images and LiDAR data with significant diversity of scene, time, and weather. The dataset consists of high-density images ($\approx~10$ times more than the pioneering KITTI dataset), heavy occlusions, a large number of night-time frames ($\approx~3$ times the nuScenes dataset), addressing the gaps in the existing datasets to push the boundaries of tasks in autonomous driving research to more challenging highly diverse environments. The dataset contains $39\text{K}$ frames, $7$ classes, and $230\text{K}$ 3D object annotations. An extensive 3D object detection benchmark evaluation on the A*3D dataset for various attributes such as high density, day-time/night-time, gives interesting insights into the advantages and limitations of training and testing 3D object detection in real-world setting.
Revisiting Point Cloud Classification: A New Benchmark Dataset and Classification Model on Real-World Data
Aug 19, 2019
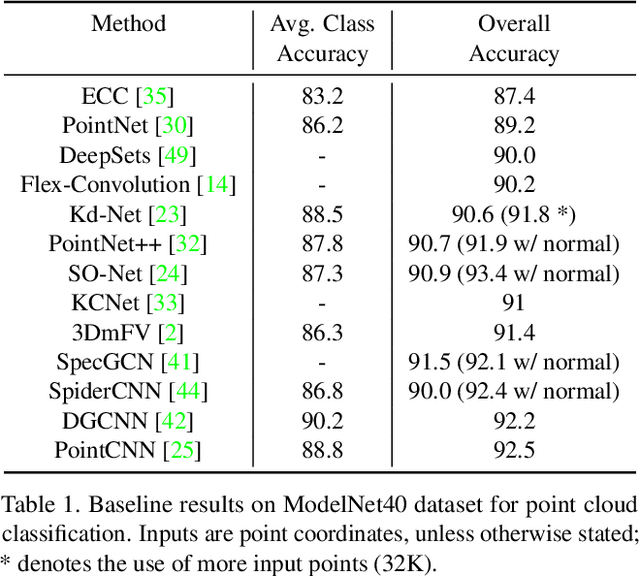


Deep learning techniques for point cloud data have demonstrated great potentials in solving classical problems in 3D computer vision such as 3D object classification and segmentation. Several recent 3D object classification methods have reported state-of-the-art performance on CAD model datasets such as ModelNet40 with high accuracy (~92%). Despite such impressive results, in this paper, we argue that object classification is still a challenging task when objects are framed with real-world settings. To prove this, we introduce ScanObjectNN, a new real-world point cloud object dataset based on scanned indoor scene data. From our comprehensive benchmark, we show that our dataset poses great challenges to existing point cloud classification techniques as objects from real-world scans are often cluttered with background and/or are partial due to occlusions. We identify three key open problems for point cloud object classification, and propose new point cloud classification neural networks that achieve state-of-the-art performance on classifying objects with cluttered background. Our dataset and code are publicly available in our project page https://hkust-vgd.github.io/scanobjectnn/.
JSIS3D: Joint Semantic-Instance Segmentation of 3D Point Clouds with Multi-Task Pointwise Networks and Multi-Value Conditional Random Fields
Apr 05, 2019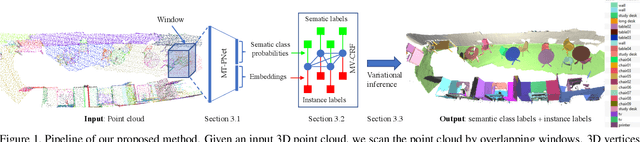

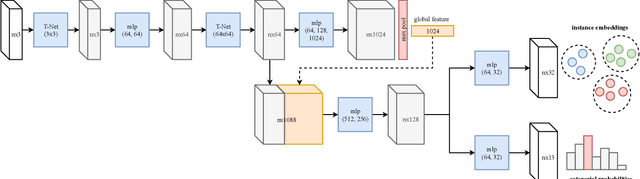

Deep learning techniques have become the to-go models for most vision-related tasks on 2D images. However, their power has not been fully realised on several tasks in 3D space, e.g., 3D scene understanding. In this work, we jointly address the problems of semantic and instance segmentation of 3D point clouds. Specifically, we develop a multi-task pointwise network that simultaneously performs two tasks: predicting the semantic classes of 3D points and embedding the points into high-dimensional vectors so that points of the same object instance are represented by similar embeddings. We then propose a multi-value conditional random field model to incorporate the semantic and instance labels and formulate the problem of semantic and instance segmentation as jointly optimising labels in the field model. The proposed method is thoroughly evaluated and compared with existing methods on different indoor scene datasets including S3DIS and SceneNN. Experimental results showed the robustness of the proposed joint semantic-instance segmentation scheme over its single components. Our method also achieved state-of-the-art performance on semantic segmentation.
Real-time Progressive 3D Semantic Segmentation for Indoor Scene
Apr 01, 2018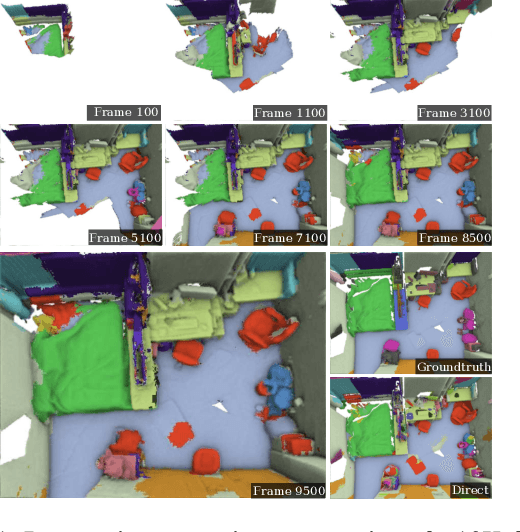
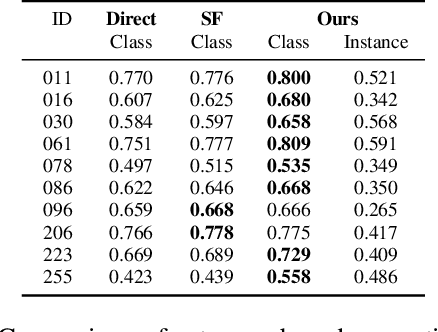
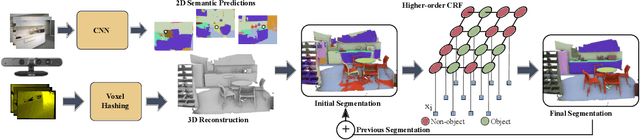
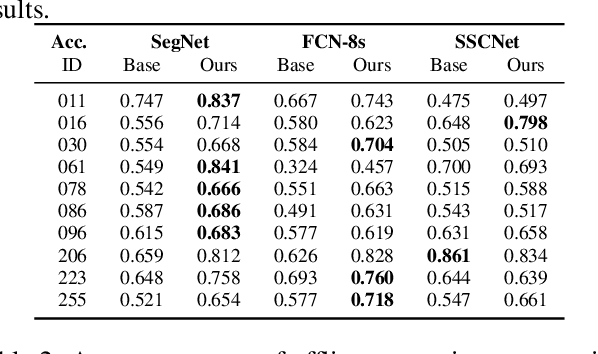
The widespread adoption of autonomous systems such as drones and assistant robots has created a need for real-time high-quality semantic scene segmentation. In this paper, we propose an efficient yet robust technique for on-the-fly dense reconstruction and semantic segmentation of 3D indoor scenes. To guarantee real-time performance, our method is built atop small clusters of voxels and a conditional random field with higher-order constraints from structural and object cues, enabling progressive dense semantic segmentation without any precomputation. We extensively evaluate our method on different indoor scenes including kitchens, offices, and bedrooms in the SceneNN and ScanNet datasets and show that our technique consistently produces state-of-the-art segmentation results in both qualitative and quantitative experiments.