 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Graph Representation Learning Methods Robust to Graph Sparsity and Asymmetric Node Information?
May 19, 2022
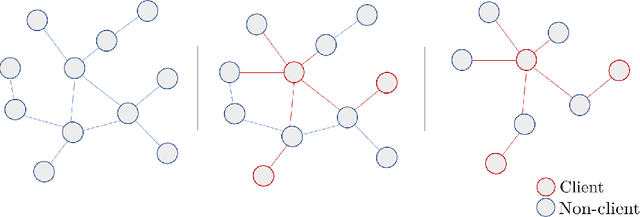
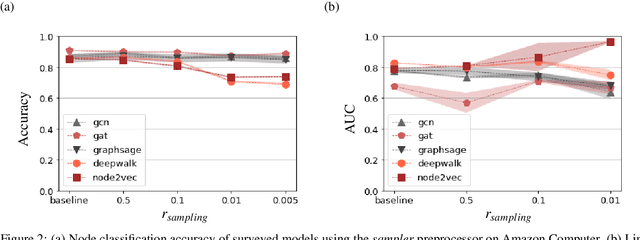
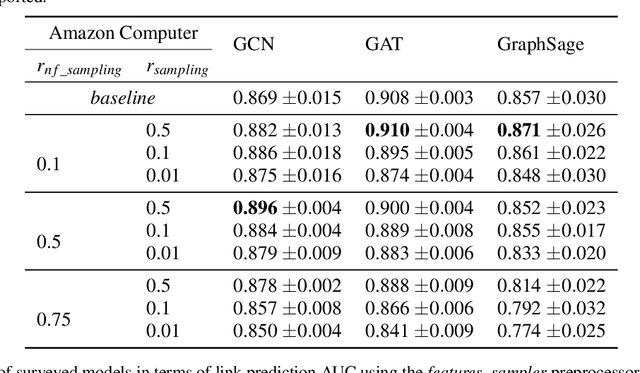
The growing popularity of Graph Representation Learning (GRL) methods has resulted in the development of a large number of models applied to a miscellany of domains. Behind this diversity of domains, there is a strong heterogeneity of graphs, making it difficult to estimate the expected performance of a model on a new graph, especially when the graph has distinctive characteristics that have not been encountered in the benchmark yet. To address this, we have developed an experimental pipeline, to assess the impact of a given property on the models performances. In this paper, we use this pipeline to study the effect of two specificities encountered on banks transactional graphs resulting from the partial view a bank has on all the individuals and transactions carried out on the market. These specific features are graph sparsity and asymmetric node information. This study demonstrates the robustness of GRL methods to these distinctive characteristics. We believe that this work can ease the evaluation of GRL methods to specific characteristics and foster the development of such methods on transactional graphs.
About Graph Degeneracy, Representation Learning and Scalability
Sep 04, 2020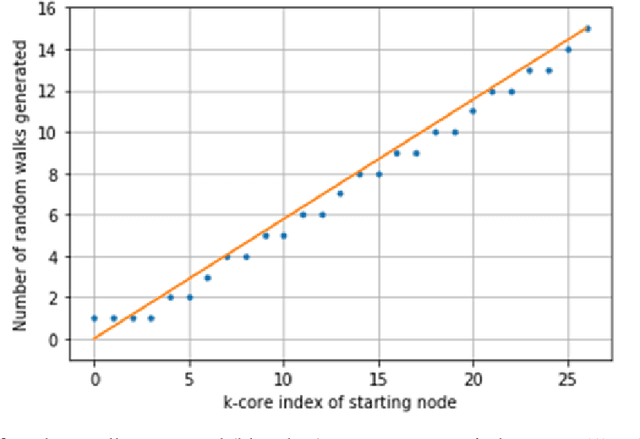

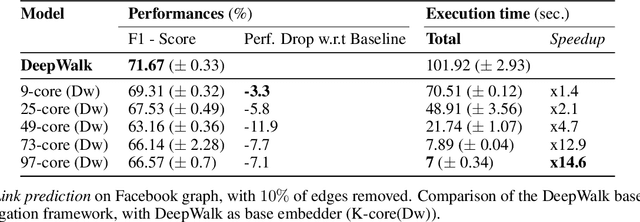
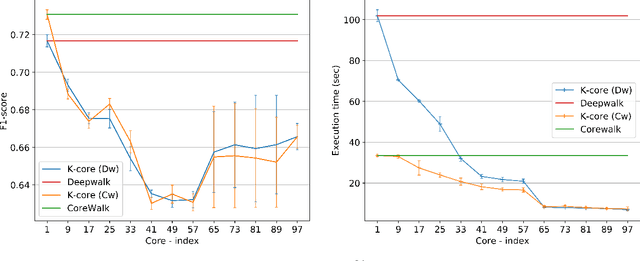
Graphs or networks are a very convenient way to represent data with lots of interaction. Recently, Machine Learning on Graph data has gained a lot of traction. In particular, vertex classification and missing edge detection have very interesting applications, ranging from drug discovery to recommender systems. To achieve such tasks, tremendous work has been accomplished to learn embedding of nodes and edges into finite-dimension vector spaces. This task is called Graph Representation Learning. However, Graph Representation Learning techniques often display prohibitive time and memory complexities, preventing their use in real-time with business size graphs. In this paper, we address this issue by leveraging a degeneracy property of Graphs - the K-Core Decomposition. We present two techniques taking advantage of this decomposition to reduce the time and memory consumption of walk-based Graph Representation Learning algorithms. We evaluate the performances, expressed in terms of quality of embedding and computational resources, of the proposed techniques on several academic datasets. Our code is available at https://github.com/SBrandeis/kcore-embedding
A*3D Dataset: Towards Autonomous Driving in Challenging Environments
Sep 17, 2019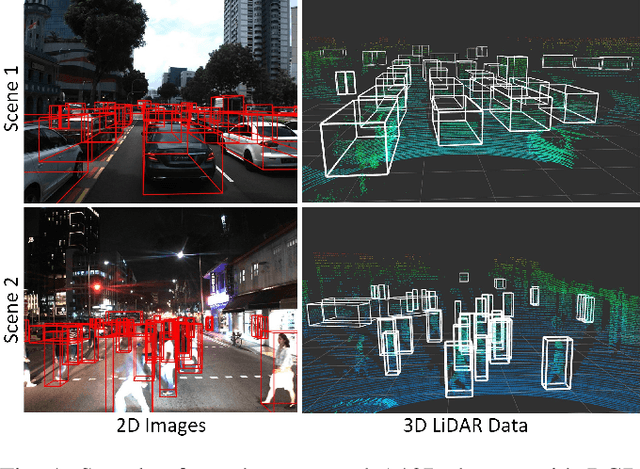
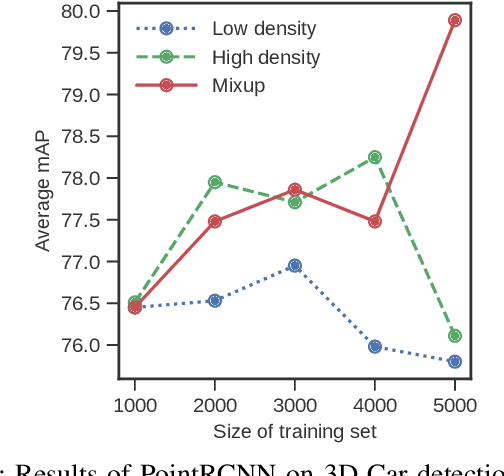
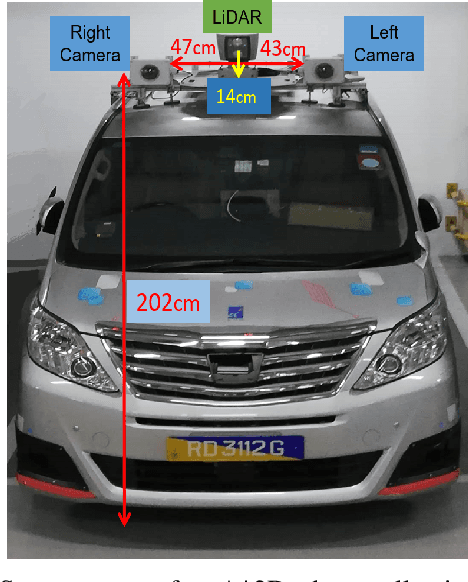
With the increasing global popularity of self-driving cars, there is an immediate need for challenging real-world datasets for benchmarking and training various computer vision tasks such as 3D object detection. Existing datasets either represent simple scenarios or provide only day-time data. In this paper, we introduce a new challenging A*3D dataset which consists of RGB images and LiDAR data with significant diversity of scene, time, and weather. The dataset consists of high-density images ($\approx~10$ times more than the pioneering KITTI dataset), heavy occlusions, a large number of night-time frames ($\approx~3$ times the nuScenes dataset), addressing the gaps in the existing datasets to push the boundaries of tasks in autonomous driving research to more challenging highly diverse environments. The dataset contains $39\text{K}$ frames, $7$ classes, and $230\text{K}$ 3D object annotations. An extensive 3D object detection benchmark evaluation on the A*3D dataset for various attributes such as high density, day-time/night-time, gives interesting insights into the advantages and limitations of training and testing 3D object detection in real-world setting.