 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets: A Community Library for Natural Language Processing
Sep 07, 2021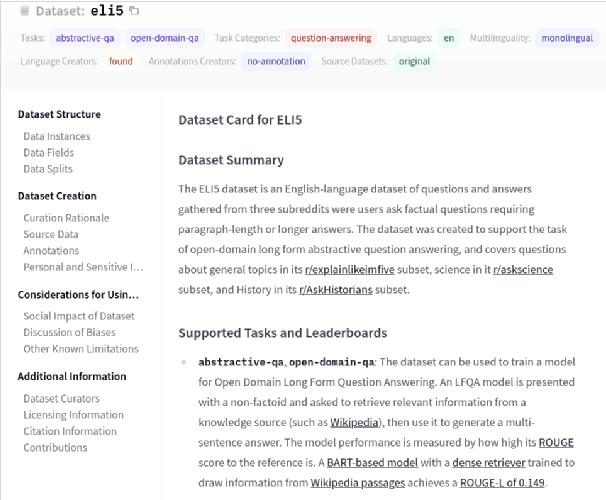
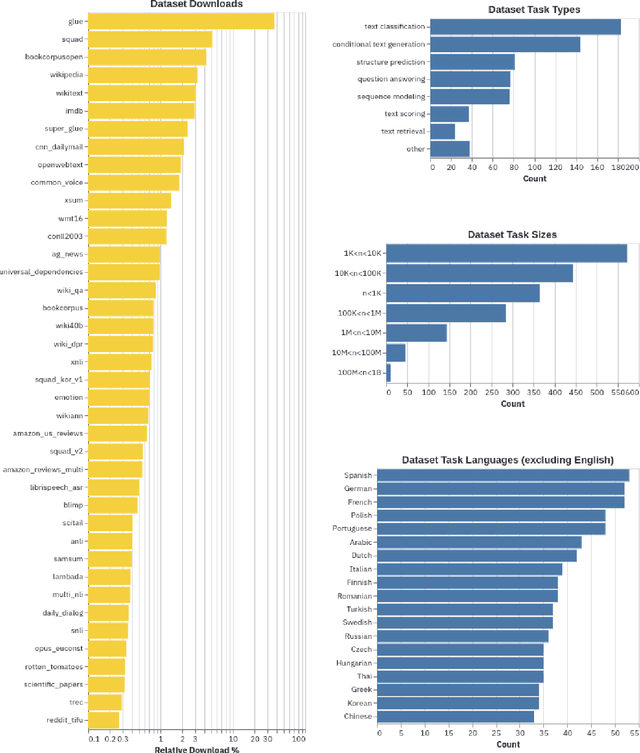
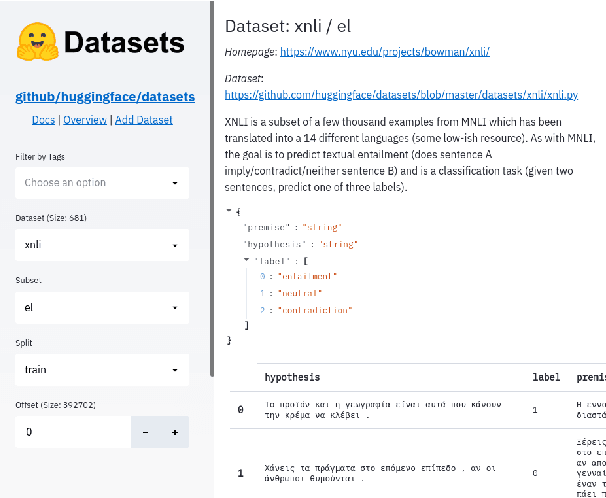
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.
About Graph Degeneracy, Representation Learning and Scalability
Sep 04, 2020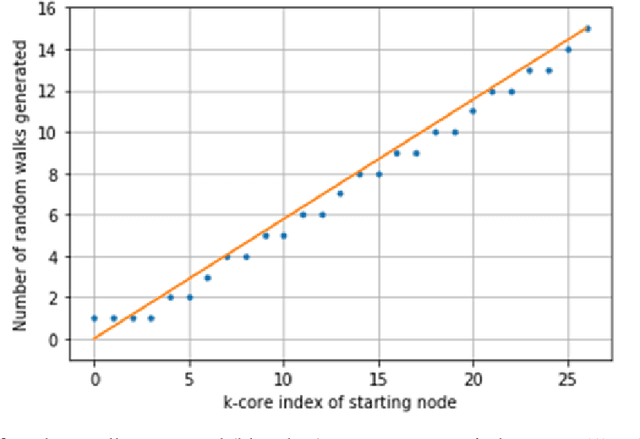

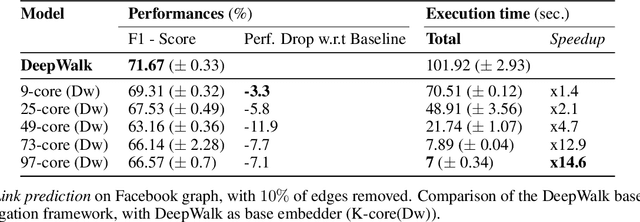
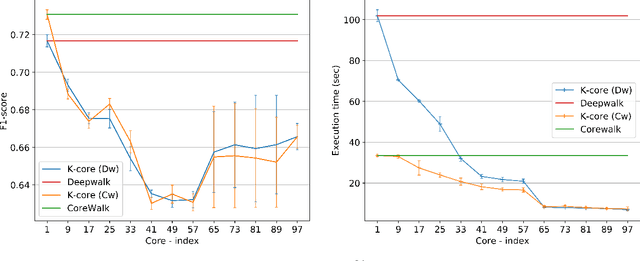
Graphs or networks are a very convenient way to represent data with lots of interaction. Recently, Machine Learning on Graph data has gained a lot of traction. In particular, vertex classification and missing edge detection have very interesting applications, ranging from drug discovery to recommender systems. To achieve such tasks, tremendous work has been accomplished to learn embedding of nodes and edges into finite-dimension vector spaces. This task is called Graph Representation Learning. However, Graph Representation Learning techniques often display prohibitive time and memory complexities, preventing their use in real-time with business size graphs. In this paper, we address this issue by leveraging a degeneracy property of Graphs - the K-Core Decomposition. We present two techniques taking advantage of this decomposition to reduce the time and memory consumption of walk-based Graph Representation Learning algorithms. We evaluate the performances, expressed in terms of quality of embedding and computational resources, of the proposed techniques on several academic datasets. Our code is available at https://github.com/SBrandeis/kcore-embedding