 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets: A Community Library for Natural Language Processing
Sep 07, 2021
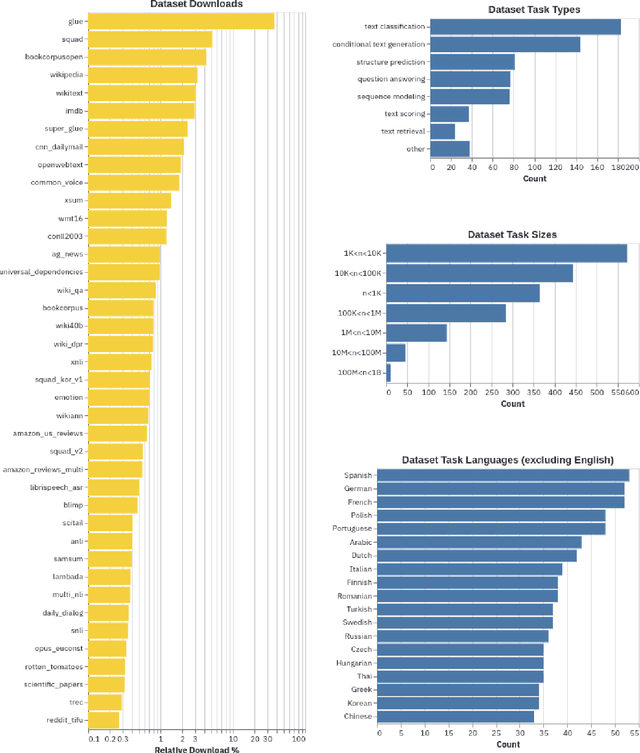
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.
Publishing and linking transport data on the Web
May 08, 2012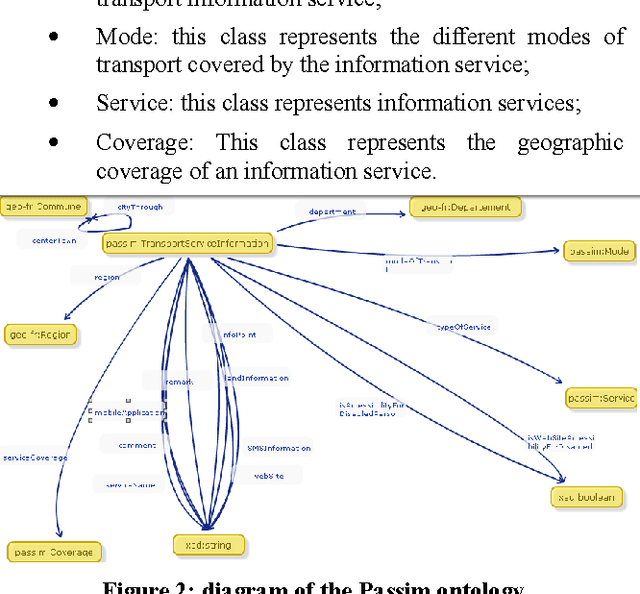
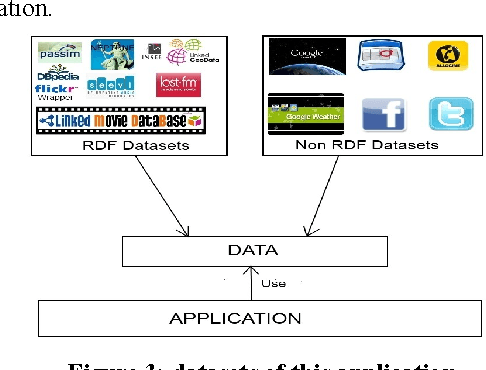
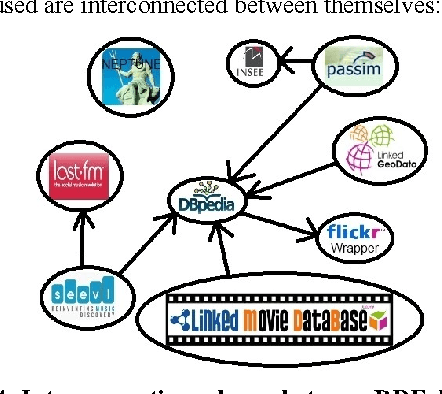
Without Linked Data, transport data is limited to applications exclusively around transport. In this paper, we present a workflow for publishing and linking transport data on the Web. So we will be able to develop transport applications and to add other features which will be created from other datasets. This will be possible because transport data will be linked to these datasets. We apply this workflow to two datasets: NEPTUNE, a French standard describing a transport line, and Passim, a directory containing relevant information on transport services, in every French city.