 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeaMUSEd: An Open MUSE Reproduction
Jan 03, 2024



We present aMUSEd, an open-source, lightweight masked image model (MIM) for text-to-image generation based on MUSE. With 10 percent of MUSE's parameters, aMUSEd is focused on fast image generation. We believe MIM is under-explored compared to latent diffusion, the prevailing approach for text-to-image generation. Compared to latent diffusion, MIM requires fewer inference steps and is more interpretable. Additionally, MIM can be fine-tuned to learn additional styles with only a single image. We hope to encourage further exploration of MIM by demonstrating its effectiveness on large-scale text-to-image generation and releasing reproducible training code. We also release checkpoints for two models which directly produce images at 256x256 and 512x512 resolutions.
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Nov 09, 2023



Latent Consistency Models (LCMs) have achieved impressive performance in accelerating text-to-image generative tasks, producing high-quality images with minimal inference steps. LCMs are distilled from pre-trained latent diffusion models (LDMs), requiring only ~32 A100 GPU training hours. This report further extends LCMs' potential in two aspects: First, by applying LoRA distillation to Stable-Diffusion models including SD-V1.5, SSD-1B, and SDXL, we have expanded LCM's scope to larger models with significantly less memory consumption, achieving superior image generation quality. Second, we identify the LoRA parameters obtained through LCM distillation as a universal Stable-Diffusion acceleration module, named LCM-LoRA. LCM-LoRA can be directly plugged into various Stable-Diffusion fine-tuned models or LoRAs without training, thus representing a universally applicable accelerator for diverse image generation tasks. Compared with previous numerical PF-ODE solvers such as DDIM, DPM-Solver, LCM-LoRA can be viewed as a plug-in neural PF-ODE solver that possesses strong generalization abilities. Project page: https://github.com/luosiallen/latent-consistency-model.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Datasets: A Community Library for Natural Language Processing
Sep 07, 2021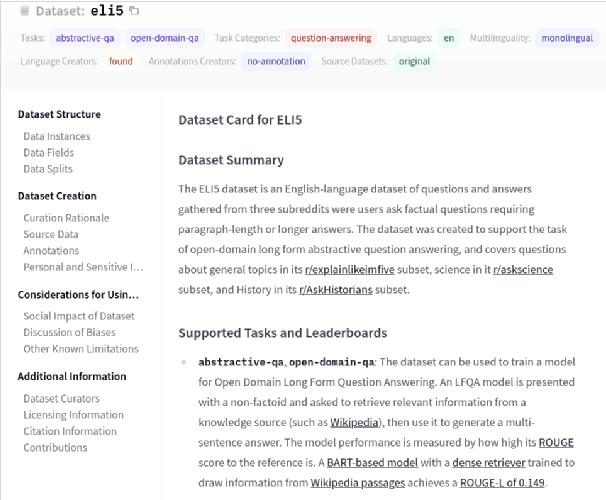
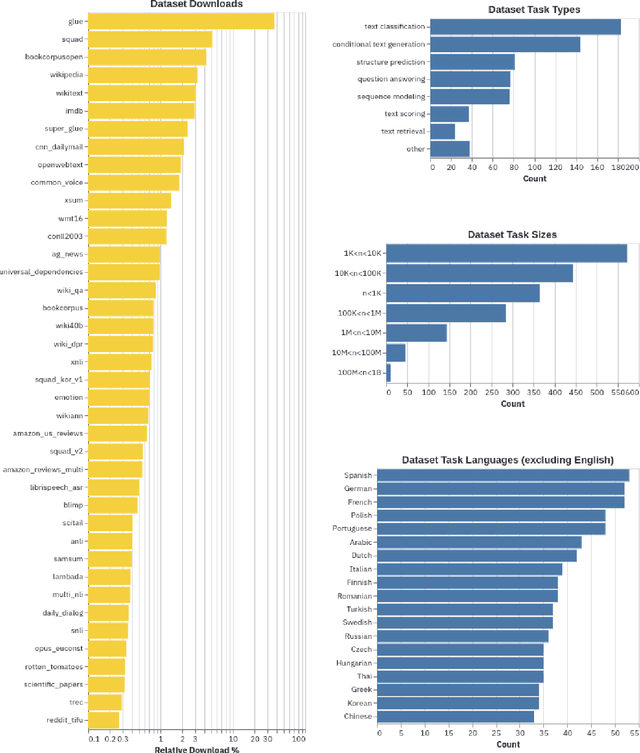
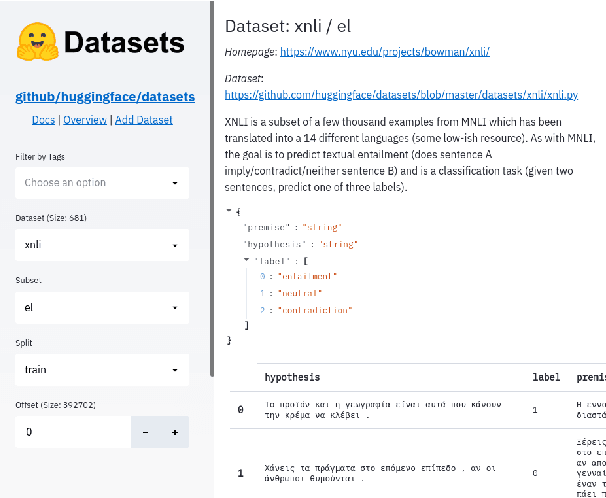
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.