 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
Beyond Release: Access Considerations for Generative AI Systems
Feb 23, 2025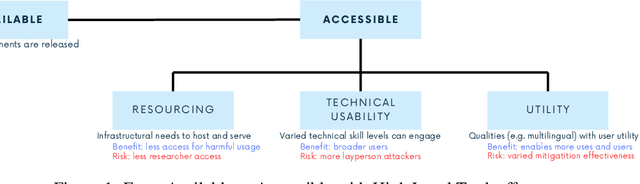
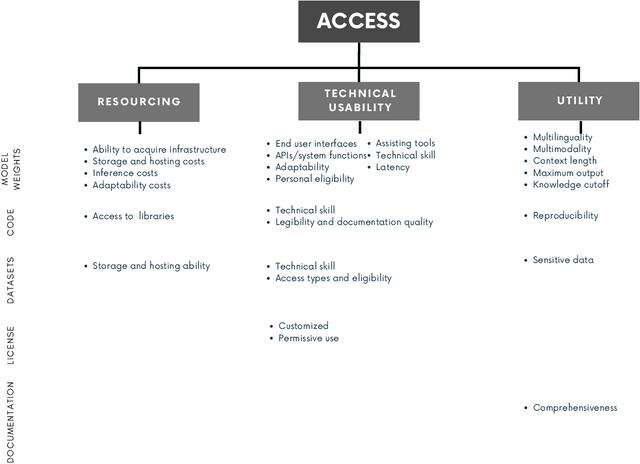
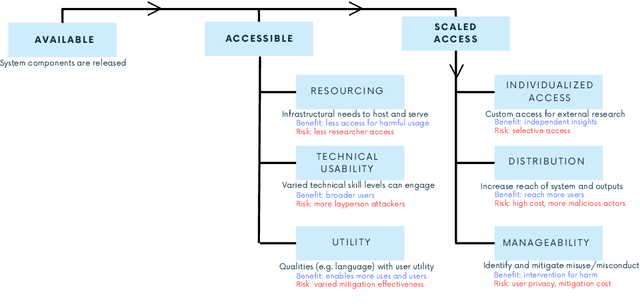
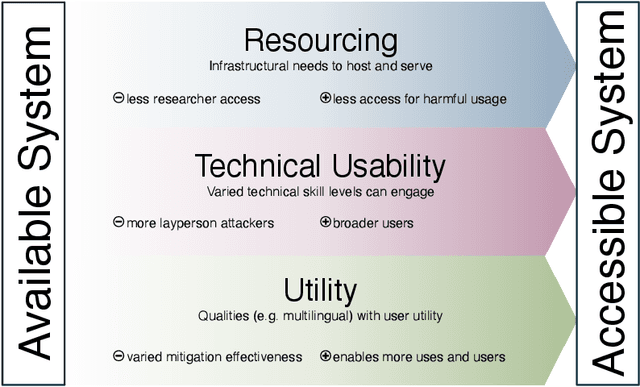
Generative AI release decisions determine whether system components are made available, but release does not address many other elements that change how users and stakeholders are able to engage with a system. Beyond release, access to system components informs potential risks and benefits. Access refers to practical needs, infrastructurally, technically, and societally, in order to use available components in some way. We deconstruct access along three axes: resourcing, technical usability, and utility. Within each category, a set of variables per system component clarify tradeoffs. For example, resourcing requires access to computing infrastructure to serve model weights. We also compare the accessibility of four high performance language models, two open-weight and two closed-weight, showing similar considerations for all based instead on access variables. Access variables set the foundation for being able to scale or increase access to users; we examine the scale of access and how scale affects ability to manage and intervene on risks. This framework better encompasses the landscape and risk-benefit tradeoffs of system releases to inform system release decisions, research, and policy.
The Responsible Foundation Model Development Cheatsheet: A Review of Tools & Resources
Jun 26, 2024


Foundation model development attracts a rapidly expanding body of contributors, scientists, and applications. To help shape responsible development practices, we introduce the Foundation Model Development Cheatsheet: a growing collection of 250+ tools and resources spanning text, vision, and speech modalities. We draw on a large body of prior work to survey resources (e.g. software, documentation, frameworks, guides, and practical tools) that support informed data selection, processing, and understanding, precise and limitation-aware artifact documentation, efficient model training, advance awareness of the environmental impact from training, careful model evaluation of capabilities, risks, and claims, as well as responsible model release, licensing and deployment practices. We hope this curated collection of resources helps guide more responsible development. The process of curating this list, enabled us to review the AI development ecosystem, revealing what tools are critically missing, misused, or over-used in existing practices. We find that (i) tools for data sourcing, model evaluation, and monitoring are critically under-serving ethical and real-world needs, (ii) evaluations for model safety, capabilities, and environmental impact all lack reproducibility and transparency, (iii) text and particularly English-centric analyses continue to dominate over multilingual and multi-modal analyses, and (iv) evaluation of systems, rather than just models, is needed so that capabilities and impact are assessed in context.
CIVICS: Building a Dataset for Examining Culturally-Informed Values in Large Language Models
May 22, 2024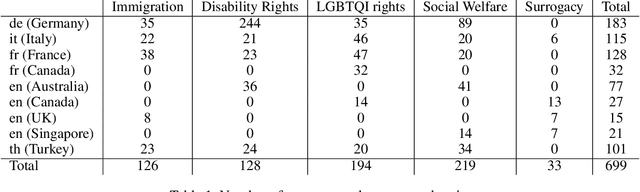
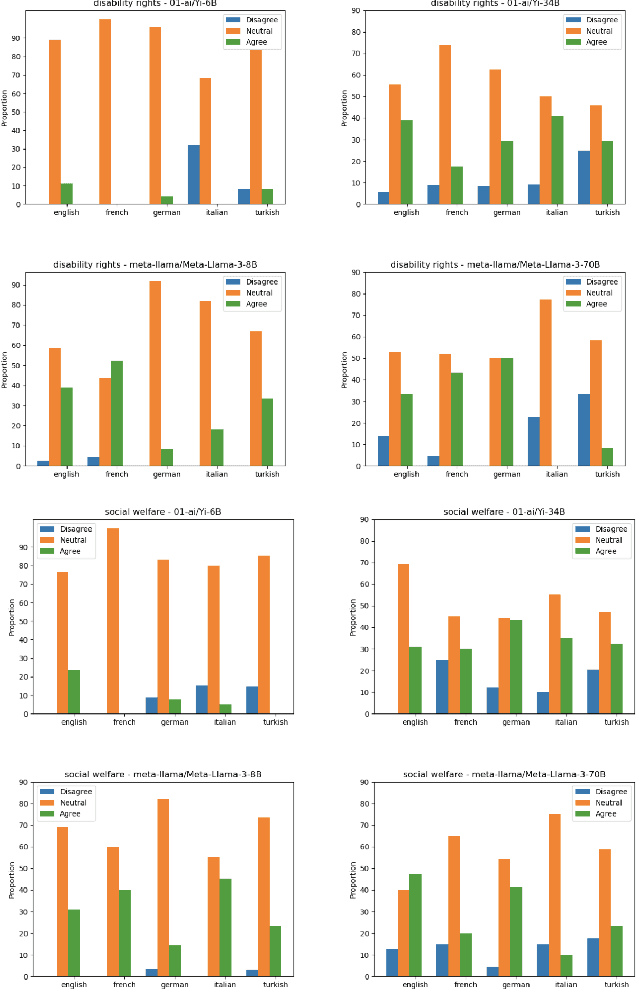

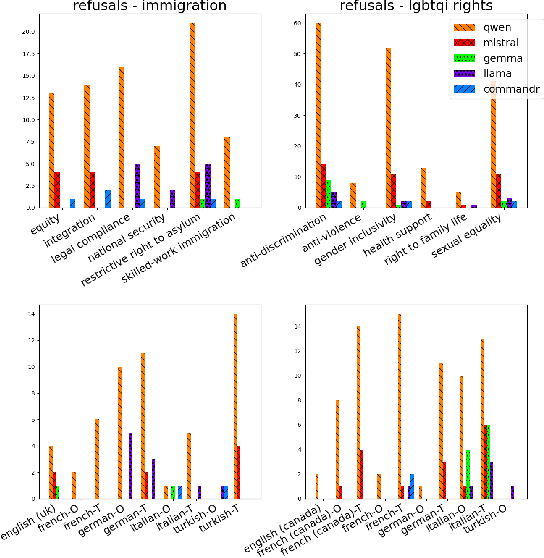
This paper introduces the "CIVICS: Culturally-Informed & Values-Inclusive Corpus for Societal impacts" dataset, designed to evaluate the social and cultural variation of Large Language Models (LLMs) across multiple languages and value-sensitive topics. We create a hand-crafted, multilingual dataset of value-laden prompts which address specific socially sensitive topics, including LGBTQI rights, social welfare, immigration, disability rights, and surrogacy. CIVICS is designed to generate responses showing LLMs' encoded and implicit values. Through our dynamic annotation processes, tailored prompt design, and experiments, we investigate how open-weight LLMs respond to value-sensitive issues, exploring their behavior across diverse linguistic and cultural contexts. Using two experimental set-ups based on log-probabilities and long-form responses, we show social and cultural variability across different LLMs. Specifically, experiments involving long-form responses demonstrate that refusals are triggered disparately across models, but consistently and more frequently in English or translated statements. Moreover, specific topics and sources lead to more pronounced differences across model answers, particularly on immigration, LGBTQI rights, and social welfare. As shown by our experiments, the CIVICS dataset aims to serve as a tool for future research, promoting reproducibility and transparency across broader linguistic settings, and furthering the development of AI technologies that respect and reflect global cultural diversities and value pluralism. The CIVICS dataset and tools will be made available upon publication under open licenses; an anonymized version is currently available at https://huggingface.co/CIVICS-dataset.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
On the Societal Impact of Open Foundation Models
Feb 27, 2024

Foundation models are powerful technologies: how they are released publicly directly shapes their societal impact. In this position paper, we focus on open foundation models, defined here as those with broadly available model weights (e.g. Llama 2, Stable Diffusion XL). We identify five distinctive properties (e.g. greater customizability, poor monitoring) of open foundation models that lead to both their benefits and risks. Open foundation models present significant benefits, with some caveats, that span innovation, competition, the distribution of decision-making power, and transparency. To understand their risks of misuse, we design a risk assessment framework for analyzing their marginal risk. Across several misuse vectors (e.g. cyberattacks, bioweapons), we find that current research is insufficient to effectively characterize the marginal risk of open foundation models relative to pre-existing technologies. The framework helps explain why the marginal risk is low in some cases, clarifies disagreements about misuse risks by revealing that past work has focused on different subsets of the framework with different assumptions, and articulates a way forward for more constructive debate. Overall, our work helps support a more grounded assessment of the societal impact of open foundation models by outlining what research is needed to empirically validate their theoretical benefits and risks.
On the Standardization of Behavioral Use Clauses and Their Adoption for Responsible Licensing of AI
Feb 07, 2024Growing concerns over negligent or malicious uses of AI have increased the appetite for tools that help manage the risks of the technology. In 2018, licenses with behaviorial-use clauses (commonly referred to as Responsible AI Licenses) were proposed to give developers a framework for releasing AI assets while specifying their users to mitigate negative applications. As of the end of 2023, on the order of 40,000 software and model repositories have adopted responsible AI licenses licenses. Notable models licensed with behavioral use clauses include BLOOM (language) and LLaMA2 (language), Stable Diffusion (image), and GRID (robotics). This paper explores why and how these licenses have been adopted, and why and how they have been adapted to fit particular use cases. We use a mixed-methods methodology of qualitative interviews, clustering of license clauses, and quantitative analysis of license adoption. Based on this evidence we take the position that responsible AI licenses need standardization to avoid confusing users or diluting their impact. At the same time, customization of behavioral restrictions is also appropriate in some contexts (e.g., medical domains). We advocate for ``standardized customization'' that can meet users' needs and can be supported via tooling.
The BigCode Project Governance Card
Dec 06, 2023This document serves as an overview of the different mechanisms and areas of governance in the BigCode project. It aims to support transparency by providing relevant information about choices that were made during the project to the broader public, and to serve as an example of intentional governance of an open research project that future endeavors can leverage to shape their own approach. The first section, Project Structure, covers the project organization, its stated goals and values, its internal decision processes, and its funding and resources. The second section, Data and Model Governance, covers decisions relating to the questions of data subject consent, privacy, and model release.
Power Hungry Processing: Watts Driving the Cost of AI Deployment?
Nov 28, 2023


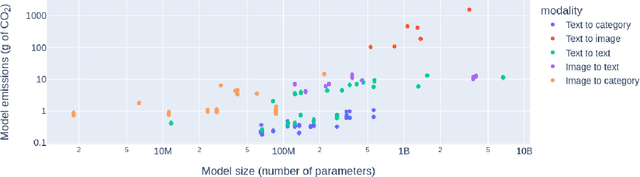
Recent years have seen a surge in the popularity of commercial AI products based on generative, multi-purpose AI systems promising a unified approach to building machine learning (ML) models into technology. However, this ambition of "generality" comes at a steep cost to the environment, given the amount of energy these systems require and the amount of carbon that they emit. In this work, we propose the first systematic comparison of the ongoing inference cost of various categories of ML systems, covering both task-specific (i.e. finetuned models that carry out a single task) and `general-purpose' models, (i.e. those trained for multiple tasks). We measure deployment cost as the amount of energy and carbon required to perform 1,000 inferences on representative benchmark dataset using these models. We find that multi-purpose, generative architectures are orders of magnitude more expensive than task-specific systems for a variety of tasks, even when controlling for the number of model parameters. We conclude with a discussion around the current trend of deploying multi-purpose generative ML systems, and caution that their utility should be more intentionally weighed against increased costs in terms of energy and emissions. All the data from our study can be accessed via an interactive demo to carry out further exploration and analysis.
Evaluating the Social Impact of Generative AI Systems in Systems and Society
Jun 12, 2023Generative AI systems across modalities, ranging from text, image, audio, and video, have broad social impacts, but there exists no official standard for means of evaluating those impacts and which impacts should be evaluated. We move toward a standard approach in evaluating a generative AI system for any modality, in two overarching categories: what is able to be evaluated in a base system that has no predetermined application and what is able to be evaluated in society. We describe specific social impact categories and how to approach and conduct evaluations in the base technical system, then in people and society. Our framework for a base system defines seven categories of social impact: bias, stereotypes, and representational harms; cultural values and sensitive content; disparate performance; privacy and data protection; financial costs; environmental costs; and data and content moderation labor costs. Suggested methods for evaluation apply to all modalities and analyses of the limitations of existing evaluations serve as a starting point for necessary investment in future evaluations. We offer five overarching categories for what is able to be evaluated in society, each with their own subcategories: trustworthiness and autonomy; inequality, marginalization, and violence; concentration of authority; labor and creativity; and ecosystem and environment. Each subcategory includes recommendations for mitigating harm. We are concurrently crafting an evaluation repository for the AI research community to contribute existing evaluations along the given categories. This version will be updated following a CRAFT session at ACM FAccT 2023.