 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Supply Chains: An Emerging Ecosystem of AI Actors, Products, and Services
Apr 28, 2025The widespread adoption of AI in recent years has led to the emergence of AI supply chains: complex networks of AI actors contributing models, datasets, and more to the development of AI products and services. AI supply chains have many implications yet are poorly understood. In this work, we take a first step toward a formal study of AI supply chains and their implications, providing two illustrative case studies indicating that both AI development and regulation are complicated in the presence of supply chains. We begin by presenting a brief historical perspective on AI supply chains, discussing how their rise reflects a longstanding shift towards specialization and outsourcing that signals the healthy growth of the AI industry. We then model AI supply chains as directed graphs and demonstrate the power of this abstraction by connecting examples of AI issues to graph properties. Finally, we examine two case studies in detail, providing theoretical and empirical results in both. In the first, we show that information passing (specifically, of explanations) along the AI supply chains is imperfect, which can result in misunderstandings that have real-world implications. In the second, we show that upstream design choices (e.g., by base model providers) have downstream consequences (e.g., on AI products fine-tuned on the base model). Together, our findings motivate further study of AI supply chains and their increasingly salient social, economic, regulatory, and technical implications.
On the Societal Impact of Open Foundation Models
Feb 27, 2024

Foundation models are powerful technologies: how they are released publicly directly shapes their societal impact. In this position paper, we focus on open foundation models, defined here as those with broadly available model weights (e.g. Llama 2, Stable Diffusion XL). We identify five distinctive properties (e.g. greater customizability, poor monitoring) of open foundation models that lead to both their benefits and risks. Open foundation models present significant benefits, with some caveats, that span innovation, competition, the distribution of decision-making power, and transparency. To understand their risks of misuse, we design a risk assessment framework for analyzing their marginal risk. Across several misuse vectors (e.g. cyberattacks, bioweapons), we find that current research is insufficient to effectively characterize the marginal risk of open foundation models relative to pre-existing technologies. The framework helps explain why the marginal risk is low in some cases, clarifies disagreements about misuse risks by revealing that past work has focused on different subsets of the framework with different assumptions, and articulates a way forward for more constructive debate. Overall, our work helps support a more grounded assessment of the societal impact of open foundation models by outlining what research is needed to empirically validate their theoretical benefits and risks.
Designing Data: Proactive Data Collection and Iteration for Machine Learning
Jan 24, 2023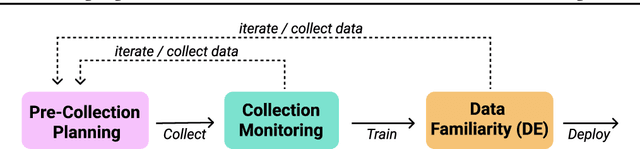


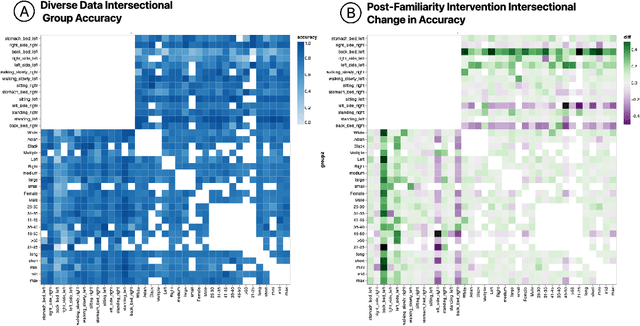
Lack of diversity in data collection has caused significant failures in machine learning (ML) applications. While ML developers perform post-collection interventions, these are time intensive and rarely comprehensive. Thus, new methods to track and manage data collection, iteration, and model training are necessary for evaluating whether datasets reflect real world variability. We present designing data, an iterative, bias mitigating approach to data collection connecting HCI concepts with ML techniques. Our process includes (1) Pre-Collection Planning, to reflexively prompt and document expected data distributions; (2) Collection Monitoring, to systematically encourage sampling diversity; and (3) Data Familiarity, to identify samples that are unfamiliar to a model through Out-of-Distribution (OOD) methods. We instantiate designing data through our own data collection and applied ML case study. We find models trained on "designed" datasets generalize better across intersectional groups than those trained on similarly sized but less targeted datasets, and that data familiarity is effective for debugging datasets.
Machine Learning Practices Outside Big Tech: How Resource Constraints Challenge Responsible Development
Oct 06, 2021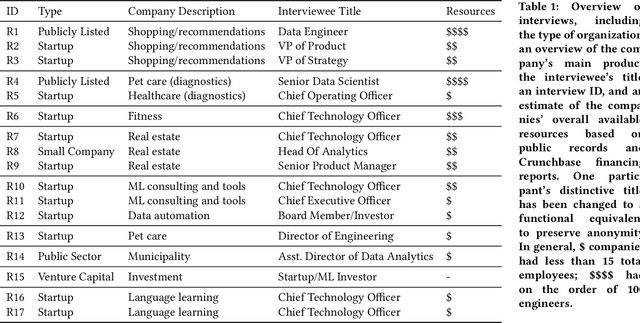
Practitioners from diverse occupations and backgrounds are increasingly using machine learning (ML) methods. Nonetheless, studies on ML Practitioners typically draw populations from Big Tech and academia, as researchers have easier access to these communities. Through this selection bias, past research often excludes the broader, lesser-resourced ML community -- for example, practitioners working at startups, at non-tech companies, and in the public sector. These practitioners share many of the same ML development difficulties and ethical conundrums as their Big Tech counterparts; however, their experiences are subject to additional under-studied challenges stemming from deploying ML with limited resources, increased existential risk, and absent access to in-house research teams. We contribute a qualitative analysis of 17 interviews with stakeholders from organizations which are less represented in prior studies. We uncover a number of tensions which are introduced or exacerbated by these organizations' resource constraints -- tensions between privacy and ubiquity, resource management and performance optimization, and access and monopolization. Increased academic focus on these practitioners can facilitate a more holistic understanding of ML limitations, and so is useful for prescribing a research agenda to facilitate responsible ML development for all.