 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
The Limits of AI Data Transparency Policy: Three Disclosure Fallacies
Jan 26, 2026Data transparency has emerged as a rallying cry for addressing concerns about AI: data quality, privacy, and copyright chief among them. Yet while these calls are crucial for accountability, current transparency policies often fall short of their intended aims. Similar to nutrition facts for food, policies aimed at nutrition facts for AI currently suffer from a limited consideration of research on effective disclosures. We offer an institutional perspective and identify three common fallacies in policy implementations of data disclosures for AI. First, many data transparency proposals exhibit a specification gap between the stated goals of data transparency and the actual disclosures necessary to achieve such goals. Second, reform attempts exhibit an enforcement gap between required disclosures on paper and enforcement to ensure compliance in fact. Third, policy proposals manifest an impact gap between disclosed information and meaningful changes in developer practices and public understanding. Informed by the social science on transparency, our analysis identifies affirmative paths for transparency that are effective rather than merely symbolic.
The 2025 Foundation Model Transparency Index
Dec 11, 2025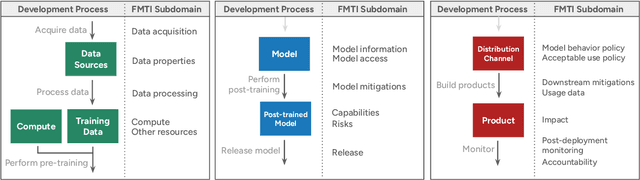
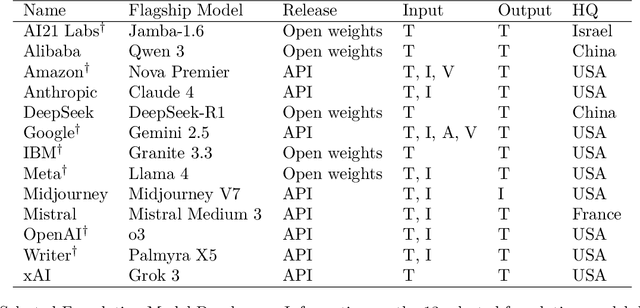
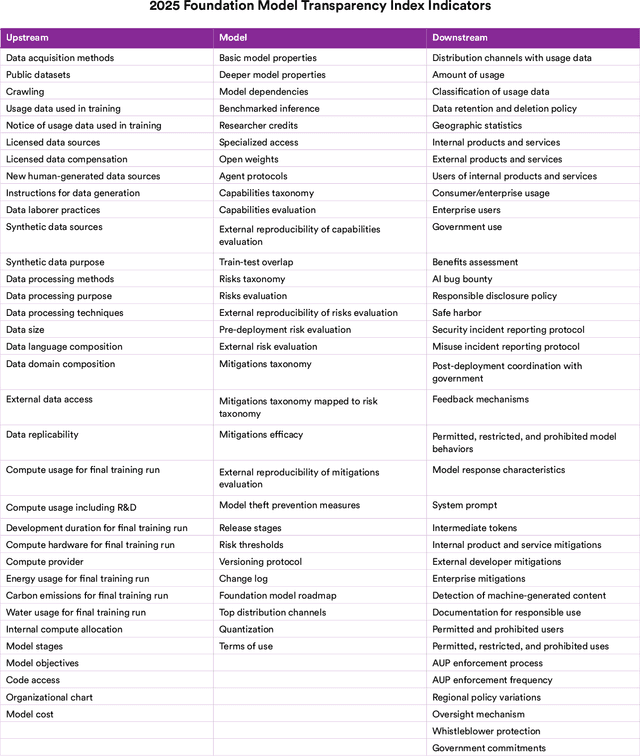
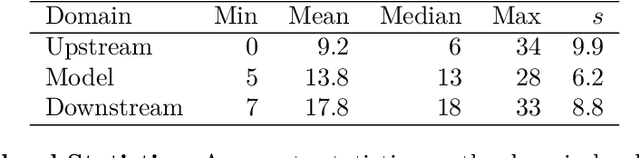
Foundation model developers are among the world's most important companies. As these companies become increasingly consequential, how do their transparency practices evolve? The 2025 Foundation Model Transparency Index is the third edition of an annual effort to characterize and quantify the transparency of foundation model developers. The 2025 FMTI introduces new indicators related to data acquisition, usage data, and monitoring and evaluates companies like Alibaba, DeepSeek, and xAI for the first time. The 2024 FMTI reported that transparency was improving, but the 2025 FMTI finds this progress has deteriorated: the average score out of 100 fell from 58 in 2024 to 40 in 2025. Companies are most opaque about their training data and training compute as well as the post-deployment usage and impact of their flagship models. In spite of this general trend, IBM stands out as a positive outlier, scoring 95, in contrast to the lowest scorers, xAI and Midjourney, at just 14. The five members of the Frontier Model Forum we score end up in the middle of the Index: we posit that these companies avoid reputational harms from low scores but lack incentives to be transparency leaders. As policymakers around the world increasingly mandate certain types of transparency, this work reveals the current state of transparency for foundation model developers, how it may change given newly enacted policy, and where more aggressive policy interventions are necessary to address critical information deficits.
Do AI Companies Make Good on Voluntary Commitments to the White House?
Aug 11, 2025Voluntary commitments are central to international AI governance, as demonstrated by recent voluntary guidelines from the White House to the G7, from Bletchley Park to Seoul. How do major AI companies make good on their commitments? We score companies based on their publicly disclosed behavior by developing a detailed rubric based on their eight voluntary commitments to the White House in 2023. We find significant heterogeneity: while the highest-scoring company (OpenAI) scores a 83% overall on our rubric, the average score across all companies is just 52%. The companies demonstrate systemically poor performance for their commitment to model weight security with an average score of 17%: 11 of the 16 companies receive 0% for this commitment. Our analysis highlights a clear structural shortcoming that future AI governance initiatives should correct: when companies make public commitments, they should proactively disclose how they meet their commitments to provide accountability, and these disclosures should be verifiable. To advance policymaking on corporate AI governance, we provide three directed recommendations that address underspecified commitments, the role of complex AI supply chains, and public transparency that could be applied towards AI governance initiatives worldwide.
Toward an Evaluation Science for Generative AI Systems
Mar 07, 2025There is an increasing imperative to anticipate and understand the performance and safety of generative AI systems in real-world deployment contexts. However, the current evaluation ecosystem is insufficient: Commonly used static benchmarks face validity challenges, and ad hoc case-by-case audits rarely scale. In this piece, we advocate for maturing an evaluation science for generative AI systems. While generative AI creates unique challenges for system safety engineering and measurement science, the field can draw valuable insights from the development of safety evaluation practices in other fields, including transportation, aerospace, and pharmaceutical engineering. In particular, we present three key lessons: Evaluation metrics must be applicable to real-world performance, metrics must be iteratively refined, and evaluation institutions and norms must be established. Applying these insights, we outline a concrete path toward a more rigorous approach for evaluating generative AI systems.
Beyond Release: Access Considerations for Generative AI Systems
Feb 23, 2025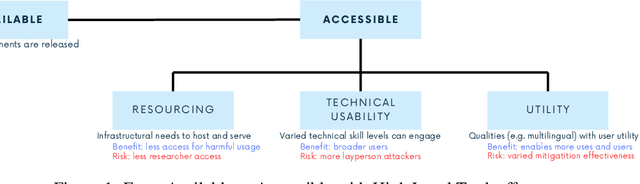
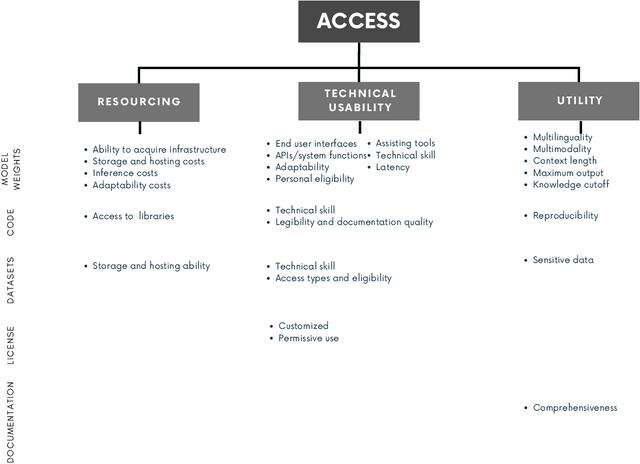
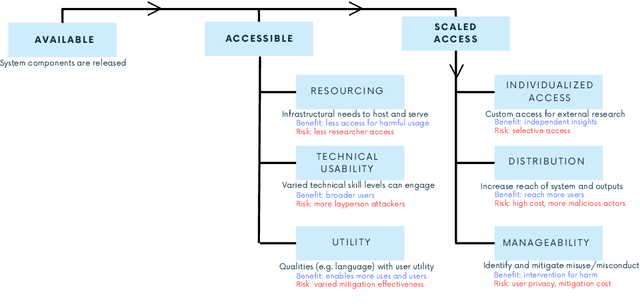
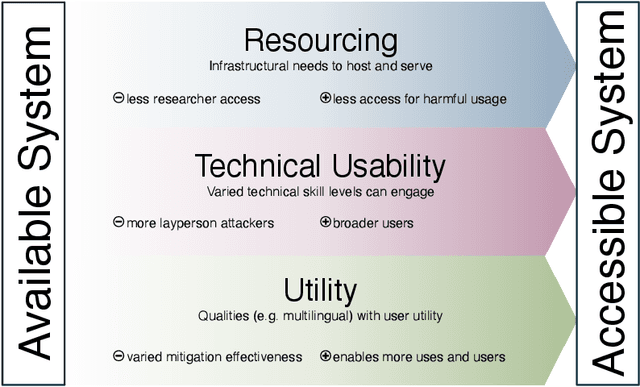
Generative AI release decisions determine whether system components are made available, but release does not address many other elements that change how users and stakeholders are able to engage with a system. Beyond release, access to system components informs potential risks and benefits. Access refers to practical needs, infrastructurally, technically, and societally, in order to use available components in some way. We deconstruct access along three axes: resourcing, technical usability, and utility. Within each category, a set of variables per system component clarify tradeoffs. For example, resourcing requires access to computing infrastructure to serve model weights. We also compare the accessibility of four high performance language models, two open-weight and two closed-weight, showing similar considerations for all based instead on access variables. Access variables set the foundation for being able to scale or increase access to users; we examine the scale of access and how scale affects ability to manage and intervene on risks. This framework better encompasses the landscape and risk-benefit tradeoffs of system releases to inform system release decisions, research, and policy.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
The Reality of AI and Biorisk
Dec 02, 2024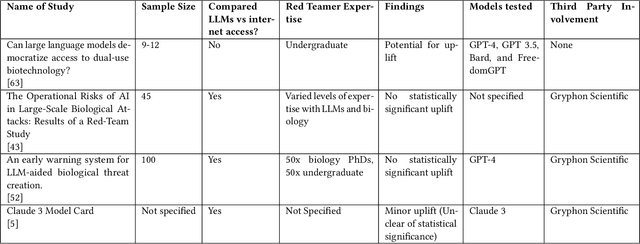
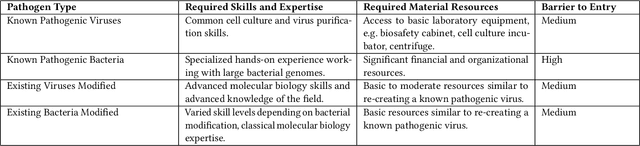
To accurately and confidently answer the question 'could an AI model or system increase biorisk', it is necessary to have both a sound theoretical threat model for how AI models or systems could increase biorisk and a robust method for testing that threat model. This paper provides an analysis of existing available research surrounding two AI and biorisk threat models: 1) access to information and planning via large language models (LLMs), and 2) the use of AI-enabled biological tools (BTs) in synthesizing novel biological artifacts. We find that existing studies around AI-related biorisk are nascent, often speculative in nature, or limited in terms of their methodological maturity and transparency. The available literature suggests that current LLMs and BTs do not pose an immediate risk, and more work is needed to develop rigorous approaches to understanding how future models could increase biorisks. We end with recommendations about how empirical work can be expanded to more precisely target biorisk and ensure rigor and validity of findings.
Effective Mitigations for Systemic Risks from General-Purpose AI
Nov 14, 2024



The systemic risks posed by general-purpose AI models are a growing concern, yet the effectiveness of mitigations remains underexplored. Previous research has proposed frameworks for risk mitigation, but has left gaps in our understanding of the perceived effectiveness of measures for mitigating systemic risks. Our study addresses this gap by evaluating how experts perceive different mitigations that aim to reduce the systemic risks of general-purpose AI models. We surveyed 76 experts whose expertise spans AI safety; critical infrastructure; democratic processes; chemical, biological, radiological, and nuclear risks (CBRN); and discrimination and bias. Among 27 mitigations identified through a literature review, we find that a broad range of risk mitigation measures are perceived as effective in reducing various systemic risks and technically feasible by domain experts. In particular, three mitigation measures stand out: safety incident reports and security information sharing, third-party pre-deployment model audits, and pre-deployment risk assessments. These measures show both the highest expert agreement ratings (>60\%) across all four risk areas and are most frequently selected in experts' preferred combinations of measures (>40\%). The surveyed experts highlighted that external scrutiny, proactive evaluation and transparency are key principles for effective mitigation of systemic risks. We provide policy recommendations for implementing the most promising measures, incorporating the qualitative contributions from experts. These insights should inform regulatory frameworks and industry practices for mitigating the systemic risks associated with general-purpose AI.
Language model developers should report train-test overlap
Oct 10, 2024

Language models are extensively evaluated, but correctly interpreting evaluation results requires knowledge of train-test overlap which refers to the extent to which the language model is trained on the very data it is being tested on. The public currently lacks adequate information about train-test overlap: most models have no public train-test overlap statistics, and third parties cannot directly measure train-test overlap since they do not have access to the training data. To make this clear, we document the practices of 30 model developers, finding that just 9 developers report train-test overlap: 4 developers release training data under open-source licenses, enabling the community to directly measure train-test overlap, and 5 developers publish their train-test overlap methodology and statistics. By engaging with language model developers, we provide novel information about train-test overlap for three additional developers. Overall, we take the position that language model developers should publish train-test overlap statistics and/or training data whenever they report evaluation results on public test sets. We hope our work increases transparency into train-test overlap to increase the community-wide trust in model evaluations.