 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reality of AI and Biorisk
Dec 02, 2024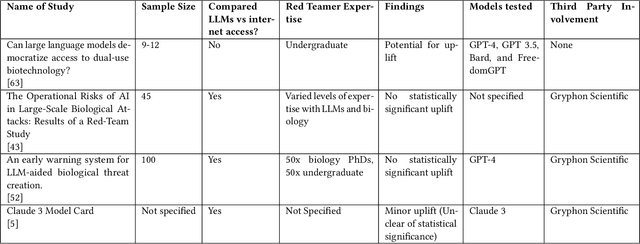
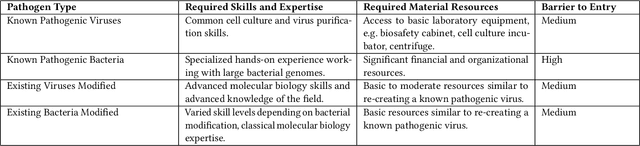
To accurately and confidently answer the question 'could an AI model or system increase biorisk', it is necessary to have both a sound theoretical threat model for how AI models or systems could increase biorisk and a robust method for testing that threat model. This paper provides an analysis of existing available research surrounding two AI and biorisk threat models: 1) access to information and planning via large language models (LLMs), and 2) the use of AI-enabled biological tools (BTs) in synthesizing novel biological artifacts. We find that existing studies around AI-related biorisk are nascent, often speculative in nature, or limited in terms of their methodological maturity and transparency. The available literature suggests that current LLMs and BTs do not pose an immediate risk, and more work is needed to develop rigorous approaches to understanding how future models could increase biorisks. We end with recommendations about how empirical work can be expanded to more precisely target biorisk and ensure rigor and validity of findings.
Deep Learning for Automated Screening of Tuberculosis from Indian Chest X-rays: Analysis and Update
Nov 19, 2020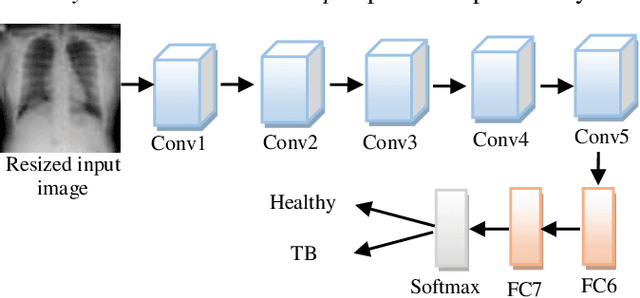
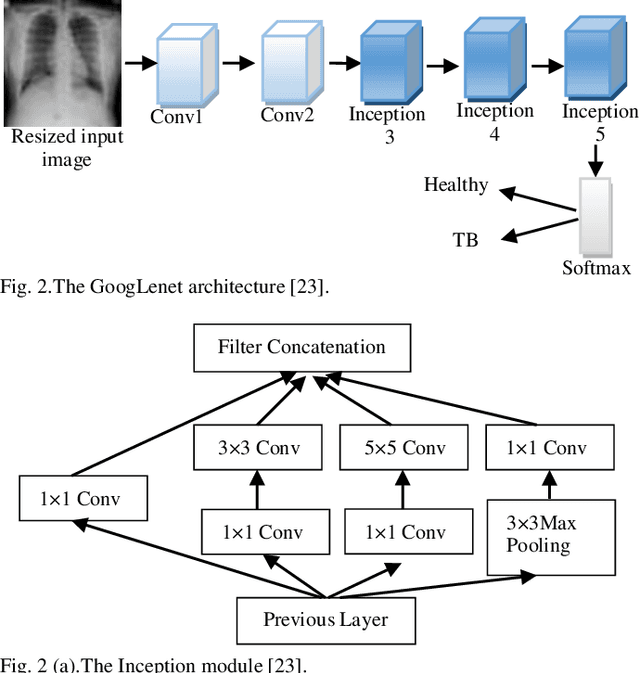
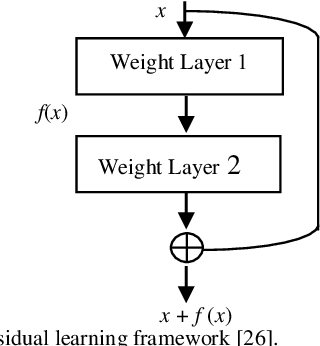
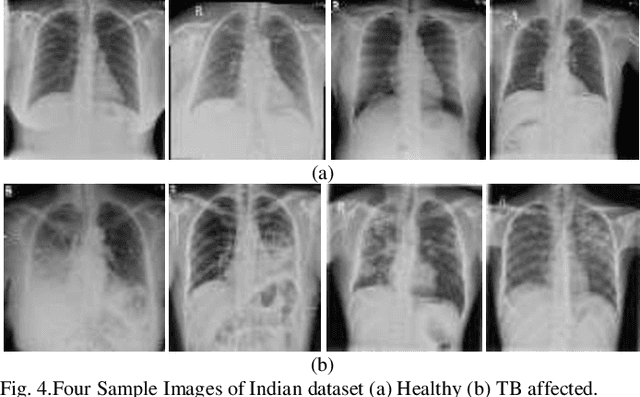
Background and Objective: Tuberculosis (TB) is a significant public health issue and a leading cause of death worldwide. Millions of deaths can be averted by early diagnosis and successful treatment of TB patients. Automated diagnosis of TB holds vast potential to assist medical experts in expediting and improving its diagnosis, especially in developing countries like India, where there is a shortage of trained medical experts and radiologists. To date, several deep learning based methods for automated detection of TB from chest radiographs have been proposed. However, the performance of a few of these methods on the Indian chest radiograph data set has been suboptimal, possibly due to different texture of the lungs on chest radiographs of Indian subjects compared to other countries. Thus deep learning for accurate and automated diagnosis of TB on Indian datasets remains an important subject of research. Methods: The proposed work explores the performance of convolutional neural networks (CNNs) for the diagnosis of TB in Indian chest x-ray images. Three different pre-trained neural network models, AlexNet, GoogLenet, and ResNet are used to classify chest x-ray images into healthy or TB infected. The proposed approach does not require any pre-processing technique. Also, other works use pre-trained NNs as a tool for crafting features and then apply standard classification techniques. However, we attempt an end to end NN model based diagnosis of TB from chest x-rays. The proposed visualization tool can also be used by radiologists in the screening of large datasets. Results: The proposed method achieved 93.40% accuracy with 98.60% sensitivity to diagnose TB for the Indian population. Conclusions: The performance of the proposed method is also tested against techniques described in the literature. The proposed method outperforms the state of art on Indian and Shenzhen datasets.
Deep LF-Net: Semantic Lung Segmentation from Indian Chest Radiographs Including Severely Unhealthy Images
Nov 19, 2020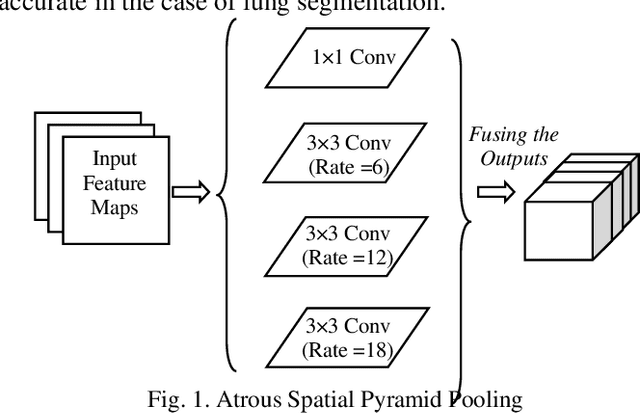
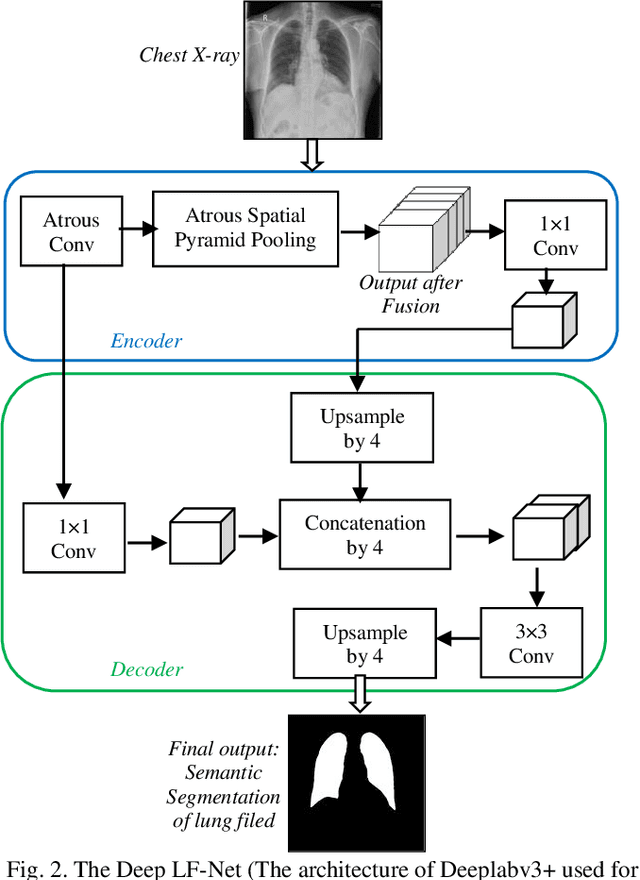
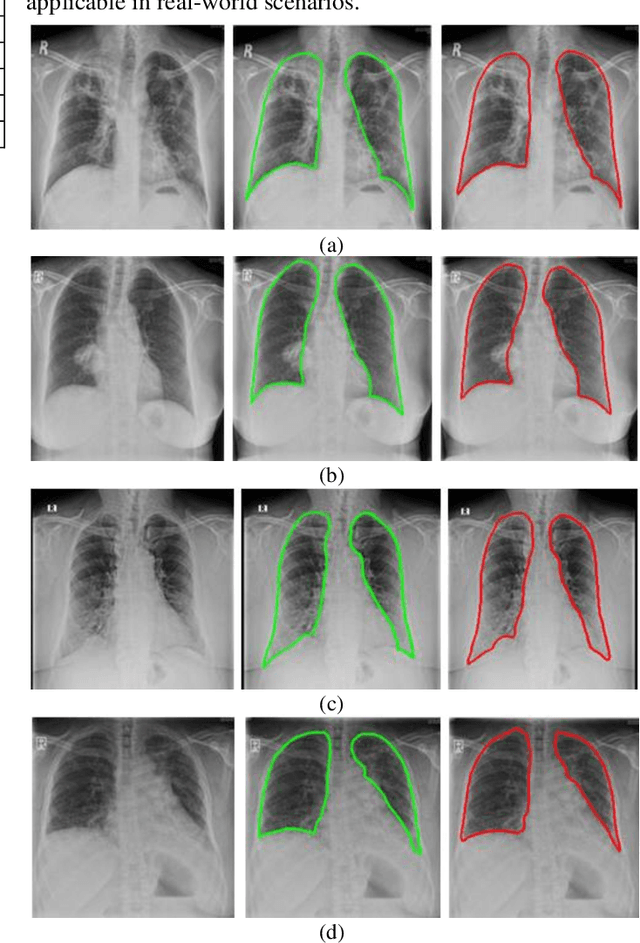
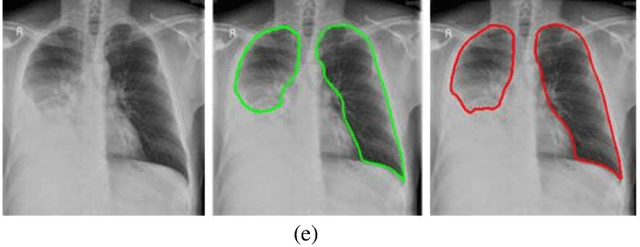
A chest radiograph, commonly called chest x-ray (CxR), plays a vital role in the diagnosis of various lung diseases, such as lung cancer, tuberculosis, pneumonia, and many more. Automated segmentation of the lungs is an important step to design a computer-aided diagnostic tool for examination of a CxR. Precise lung segmentation is considered extremely challenging because of variance in the shape of the lung caused by health issues, age, and gender. The proposed work investigates the use of an efficient deep convolutional neural network for accurate segmentation of lungs from CxR. We attempt an end to end DeepLabv3+ network which integrates DeepLab architecture, encoder-decoder, and dilated convolution for semantic lung segmentation with fast training and high accuracy. We experimented with the different pre-trained base networks: Resnet18 and Mobilenetv2, associated with the Deeplabv3+ model for performance analysis. The proposed approach does not require any pre-processing technique on chest x-ray images before being fed to a neural network. Morphological operations were used to remove false positives that occurred during semantic segmentation. We construct a CxR dataset of the Indian population that contain healthy and unhealthy CxRs of clinically confirmed patients of tuberculosis, chronic obstructive pulmonary disease, interstitial lung disease, pleural effusion, and lung cancer. The proposed method is tested on 688 images of our Indian CxR dataset including images with severe abnormal findings to validate its robustness. We also experimented on commonly used benchmark datasets such as Japanese Society of Radiological Technology; Montgomery County, USA; and Shenzhen, China for state-of-the-art comparison. The performance of our method is tested against techniques described in the literature and achieved the highest accuracy for lung segmentation on Indian and public datasets.