 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Responsible Foundation Model Development Cheatsheet: A Review of Tools & Resources
Jun 26, 2024


Foundation model development attracts a rapidly expanding body of contributors, scientists, and applications. To help shape responsible development practices, we introduce the Foundation Model Development Cheatsheet: a growing collection of 250+ tools and resources spanning text, vision, and speech modalities. We draw on a large body of prior work to survey resources (e.g. software, documentation, frameworks, guides, and practical tools) that support informed data selection, processing, and understanding, precise and limitation-aware artifact documentation, efficient model training, advance awareness of the environmental impact from training, careful model evaluation of capabilities, risks, and claims, as well as responsible model release, licensing and deployment practices. We hope this curated collection of resources helps guide more responsible development. The process of curating this list, enabled us to review the AI development ecosystem, revealing what tools are critically missing, misused, or over-used in existing practices. We find that (i) tools for data sourcing, model evaluation, and monitoring are critically under-serving ethical and real-world needs, (ii) evaluations for model safety, capabilities, and environmental impact all lack reproducibility and transparency, (iii) text and particularly English-centric analyses continue to dominate over multilingual and multi-modal analyses, and (iv) evaluation of systems, rather than just models, is needed so that capabilities and impact are assessed in context.
Predicting positive transfer for improved low-resource speech recognition using acoustic pseudo-tokens
Feb 03, 2024



While massively multilingual speech models like wav2vec 2.0 XLSR-128 can be directly fine-tuned for automatic speech recognition (ASR), downstream performance can still be relatively poor on languages that are under-represented in the pre-training data. Continued pre-training on 70-200 hours of untranscribed speech in these languages can help -- but what about languages without that much recorded data? For such cases, we show that supplementing the target language with data from a similar, higher-resource 'donor' language can help. For example, continued pre-training on only 10 hours of low-resource Punjabi supplemented with 60 hours of donor Hindi is almost as good as continued pretraining on 70 hours of Punjabi. By contrast, sourcing data from less similar donors like Bengali does not improve ASR performance. To inform donor language selection, we propose a novel similarity metric based on the sequence distribution of induced acoustic units: the Acoustic Token Distribution Similarity (ATDS). Across a set of typologically different target languages (Punjabi, Galician, Iban, Setswana), we show that the ATDS between the target language and its candidate donors precisely predicts target language ASR performance.
Developing Speech Processing Pipelines for Police Accountability
Jun 09, 2023Police body-worn cameras have the potential to improve accountability and transparency in policing. Yet in practice, they result in millions of hours of footage that is never reviewed. We investigate the potential of large pre-trained speech models for facilitating reviews, focusing on ASR and officer speech detection in footage from traffic stops. Our proposed pipeline includes training data alignment and filtering, fine-tuning with resource constraints, and combining officer speech detection with ASR for a fully automated approach. We find that (1) fine-tuning strongly improves ASR performance on officer speech (WER=12-13%), (2) ASR on officer speech is much more accurate than on community member speech (WER=43.55-49.07%), (3) domain-specific tasks like officer speech detection and diarization remain challenging. Our work offers practical applications for reviewing body camera footage and general guidance for adapting pre-trained speech models to noisy multi-speaker domains.
Making More of Little Data: Improving Low-Resource Automatic Speech Recognition Using Data Augmentation
May 19, 2023



The performance of automatic speech recognition (ASR) systems has advanced substantially in recent years, particularly for languages for which a large amount of transcribed speech is available. Unfortunately, for low-resource languages, such as minority languages, regional languages or dialects, ASR performance generally remains much lower. In this study, we investigate whether data augmentation techniques could help improve low-resource ASR performance, focusing on four typologically diverse minority languages or language variants (West Germanic: Gronings, West-Frisian; Malayo-Polynesian: Besemah, Nasal). For all four languages, we examine the use of self-training, where an ASR system trained with the available human-transcribed data is used to generate transcriptions, which are then combined with the original data to train a new ASR system. For Gronings, for which there was a pre-existing text-to-speech (TTS) system available, we also examined the use of TTS to generate ASR training data from text-only sources. We find that using a self-training approach consistently yields improved performance (a relative WER reduction up to 20.5% compared to using an ASR system trained on 24 minutes of manually transcribed speech). The performance gain from TTS augmentation for Gronings was even stronger (up to 25.5% relative reduction in WER compared to a system based on 24 minutes of manually transcribed speech). In sum, our results show the benefit of using self-training or (if possible) TTS-generated data as an efficient solution to overcome the limitations of data availability for resource-scarce languages in order to improve ASR performance.
Leveraging supplementary text data to kick-start automatic speech recognition system development with limited transcriptions
Feb 09, 2023
Recent research using pre-trained transformer models suggests that just 10 minutes of transcribed speech may be enough to fine-tune such a model for automatic speech recognition (ASR) -- at least if we can also leverage vast amounts of text data (803 million tokens). But is that much text data necessary? We study the use of different amounts of text data, both for creating a lexicon that constrains ASR decoding to possible words (e.g. *dogz vs. dogs), and for training larger language models that bias the system toward probable word sequences (e.g. too dogs vs. two dogs). We perform experiments using 10 minutes of transcribed speech from English (for replicating prior work) and two additional pairs of languages differing in the availability of supplemental text data: Gronings and Frisian (~7.5M token corpora available), and Besemah and Nasal (only small lexica available). For all languages, we found that using only a lexicon did not appreciably improve ASR performance. For Gronings and Frisian, we found that lexica and language models derived from 'novel-length' 80k token subcorpora reduced the word error rate (WER) to 39% on average. Our findings suggest that where a text corpus in the upper tens of thousands of tokens or more is available, fine-tuning a transformer model with just tens of minutes of transcribed speech holds some promise towards obtaining human-correctable transcriptions near the 30% WER rule-of-thumb.
Automated speech tools for helping communities process restricted-access corpora for language revival efforts
Apr 24, 2022
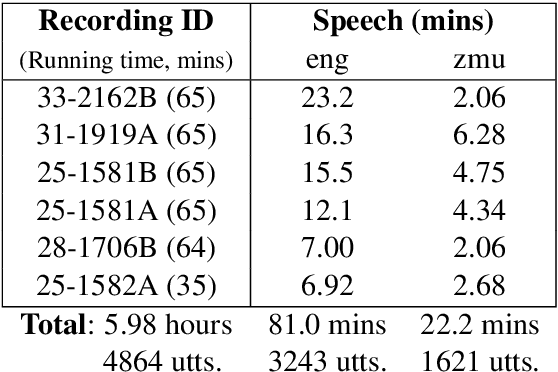
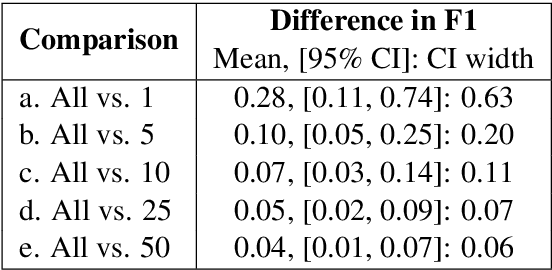
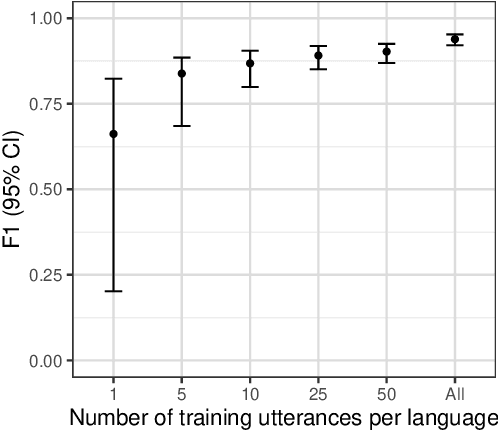
Many archival recordings of speech from endangered languages remain unannotated and inaccessible to community members and language learning programs. One bottleneck is the time-intensive nature of annotation. An even narrower bottleneck occurs for recordings with access constraints, such as language that must be vetted or filtered by authorised community members before annotation can begin. We propose a privacy-preserving workflow to widen both bottlenecks for recordings where speech in the endangered language is intermixed with a more widely-used language such as English for meta-linguistic commentary and questions (e.g. What is the word for 'tree'?). We integrate voice activity detection (VAD), spoken language identification (SLI), and automatic speech recognition (ASR) to transcribe the metalinguistic content, which an authorised person can quickly scan to triage recordings that can be annotated by people with lower levels of access. We report work-in-progress processing 136 hours archival audio containing a mix of English and Muruwari. Our collaborative work with the Muruwari custodian of the archival materials show that this workflow reduces metalanguage transcription time by 20% even given only minimal amounts of annotated training data: 10 utterances per language for SLI and for ASR at most 39 minutes, and possibly as little as 39 seconds.
Leveraging neural representations for facilitating access to untranscribed speech from endangered languages
Mar 26, 2021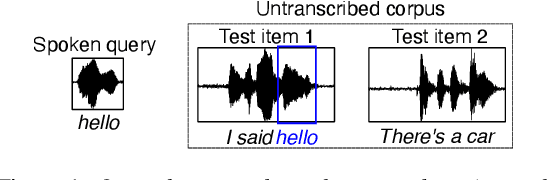
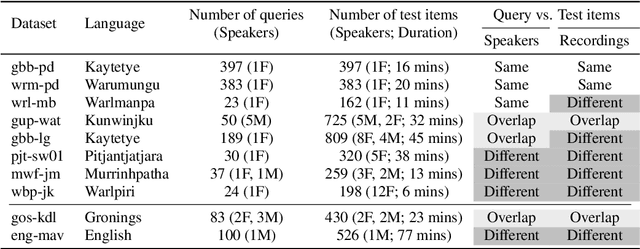
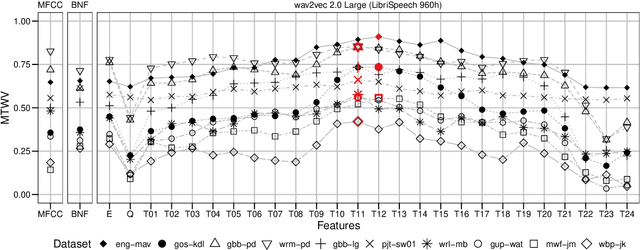
For languages with insufficient resources to train speech recognition systems, query-by-example spoken term detection (QbE-STD) offers a way of accessing an untranscribed speech corpus by helping identify regions where spoken query terms occur. Yet retrieval performance can be poor when the query and corpus are spoken by different speakers and produced in different recording conditions. Using data selected from a variety of speakers and recording conditions from 7 Australian Aboriginal languages and a regional variety of Dutch, all of which are endangered or vulnerable, we evaluated whether QbE-STD performance on these languages could be improved by leveraging representations extracted from the pre-trained English wav2vec 2.0 model. Compared to the use of Mel-frequency cepstral coefficients and bottleneck features, we find that representations from the middle layers of the wav2vec 2.0 Transformer offer large gains in task performance (between 56% and 86%). While features extracted using the pre-trained English model yielded improved detection on all the evaluation languages, better detection performance was associated with the evaluation language's phonological similarity to English.