 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Synthetic Lesional MR Images in Automated Focal Cortical Dysplasia Detection in Low-Data Scenarios
Jun 05, 2026Background and Purpose: Automated detection of focal cortical dysplasia (FCD) requires large volumes of voxelwise lesion-delineated MRI data, which are difficult to acquire. This study aims to generate synthetic MRI data exhibiting FCD, assess their realism, and evaluate their impact on automated FCD detection, particularly in reducing the need for manual annotations. Methods: T1-weighted (T1w) and T2-weighted Fluid-Attenuated Inversion Recovery (FLAIR) MRI scans from 131 FCD patients and 90 healthy controls from multiple (3) sites were retrospectively studied. Synthetic MRIs were generated by conditioning a generative network on binary FCD masks. Two neuroradiologists identified real images from a random set of 14 real and 14 synthetic scans. Three nnU-Net models were trained to detect FCD using: (i) real-only (35 FCD / 35 controls), (ii) real (35 FCD / 35 controls) plus synthetic augmentation, and (iii) expanded real data (70 FCD / 70 controls). Results: Experts showed limited ability to distinguish real from synthetic images, with classification accuracy of 60% for T1w and 70% for FLAIR (inter-rater agreement kappa = 0.86). Augmenting automated FCD detection with synthetic data increased sensitivity by 8.14% (p = 0.12) and improved model confidence at true lesion sites (0.83 +/- 0.11 to 0.89 +/- 0.12; p = 0.02). The expanded real-data model further improved sensitivity to 73.8% (p < 0.001) and confidence to 0.90 +/- 0.14 (p = 0.01). Conclusion: Conditional generative networks can generate realistic synthetic FCD-MRIs, reducing labeled data needs by approximately 20% while maintaining equivalent sensitivity. Equivalent amounts of real data, when available, remain more effective than synthetic augmentation.
Quality assessment of brain structural MR images: Comparing generalization of deep learning versus hand-crafted feature-based machine learning methods to new sites
Mar 17, 2026Quality assessment of brain structural MR images is critical for large-scale neuroimaging studies, where motion artifacts can significantly bias clinical estimates. While visual rating remains the gold standard, it is time-consuming and subjective. This study evaluates the relative performance and generalization capabilities of two prominent Automated Quality Assessment (AQA) methods: MRIQC, which uses hand-crafted image-quality metrics with traditional machine learning, and CNNQC, which utilizes a deep learning (DL) architecture. Using a heterogeneous dataset of 1,098 T1-weighted volumes from 17 different sites, we assessed performance on both seen sites and entirely new sites using a leave-one-site-out (LOSO) approach. Our results indicate that both DL and traditional ML methods struggle to generalize to new scanners or sites. While MRIQC generally achieved higher accuracy across most unseen sites, CNNQC demonstrated higher sensitivity for detecting poor-quality scans. Given that DL-based methods like CNNQC offer higher computational efficiency and do not require expensive pre-processing, they may be preferred for widespread deployment, provided that future work focuses on improving cross-site generalizability.
Estimation of 3T MR images from 1.5T images regularized with Physics based Constraint
Dec 31, 2024Limited accessibility to high field MRI scanners (such as 7T, 11T) has motivated the development of post-processing methods to improve low field images. Several existing post-processing methods have shown the feasibility to improve 3T images to produce 7T-like images [3,18]. It has been observed that improving lower field (LF, <=1.5T) images comes with additional challenges due to poor image quality such as the function mapping 1.5T and higher field (HF, 3T) images is more complex than the function relating 3T and 7T images [10]. Except for [10], no method has been addressed to improve <=1.5T MRI images. Further, most of the existing methods [3,18] including [10] require example images, and also often rely on pixel to pixel correspondences between LF and HF images which are usually inaccurate for <=1.5T images. The focus of this paper is to address the unsupervised framework for quality improvement of 1.5T images and avoid the expensive requirements of example images and associated image registration. The LF and HF images are assumed to be related by a linear transformation (LT). The unknown HF image and unknown LT are estimated in alternate minimization framework. Further, a physics based constraint is proposed that provides an additional non-linear function relating LF and HF images in order to achieve the desired high contrast in estimated HF image. The experimental results demonstrate that the proposed approach provides processed 1.5T images, i.e., estimated 3T-like images with improved image quality, and is comparably better than the existing methods addressing similar problems. The improvement in image quality is also shown to provide better tissue segmentation and volume quantification as compared to scanner acquired 1.5T images.
* conference paper
Direct Punjabi to English speech translation using discrete units
Feb 25, 2024



Speech-to-speech translation is yet to reach the same level of coverage as text-to-text translation systems. The current speech technology is highly limited in its coverage of over 7000 languages spoken worldwide, leaving more than half of the population deprived of such technology and shared experiences. With voice-assisted technology (such as social robots and speech-to-text apps) and auditory content (such as podcasts and lectures) on the rise, ensuring that the technology is available for all is more important than ever. Speech translation can play a vital role in mitigating technological disparity and creating a more inclusive society. With a motive to contribute towards speech translation research for low-resource languages, our work presents a direct speech-to-speech translation model for one of the Indic languages called Punjabi to English. Additionally, we explore the performance of using a discrete representation of speech called discrete acoustic units as input to the Transformer-based translation model. The model, abbreviated as Unit-to-Unit Translation (U2UT), takes a sequence of discrete units of the source language (the language being translated from) and outputs a sequence of discrete units of the target language (the language being translated to). Our results show that the U2UT model performs better than the Speech-to-Unit Translation (S2UT) model by a 3.69 BLEU score.
Predicting positive transfer for improved low-resource speech recognition using acoustic pseudo-tokens
Feb 03, 2024



While massively multilingual speech models like wav2vec 2.0 XLSR-128 can be directly fine-tuned for automatic speech recognition (ASR), downstream performance can still be relatively poor on languages that are under-represented in the pre-training data. Continued pre-training on 70-200 hours of untranscribed speech in these languages can help -- but what about languages without that much recorded data? For such cases, we show that supplementing the target language with data from a similar, higher-resource 'donor' language can help. For example, continued pre-training on only 10 hours of low-resource Punjabi supplemented with 60 hours of donor Hindi is almost as good as continued pretraining on 70 hours of Punjabi. By contrast, sourcing data from less similar donors like Bengali does not improve ASR performance. To inform donor language selection, we propose a novel similarity metric based on the sequence distribution of induced acoustic units: the Acoustic Token Distribution Similarity (ATDS). Across a set of typologically different target languages (Punjabi, Galician, Iban, Setswana), we show that the ATDS between the target language and its candidate donors precisely predicts target language ASR performance.
Fall Detection from Audios with Audio Transformers
Aug 23, 2022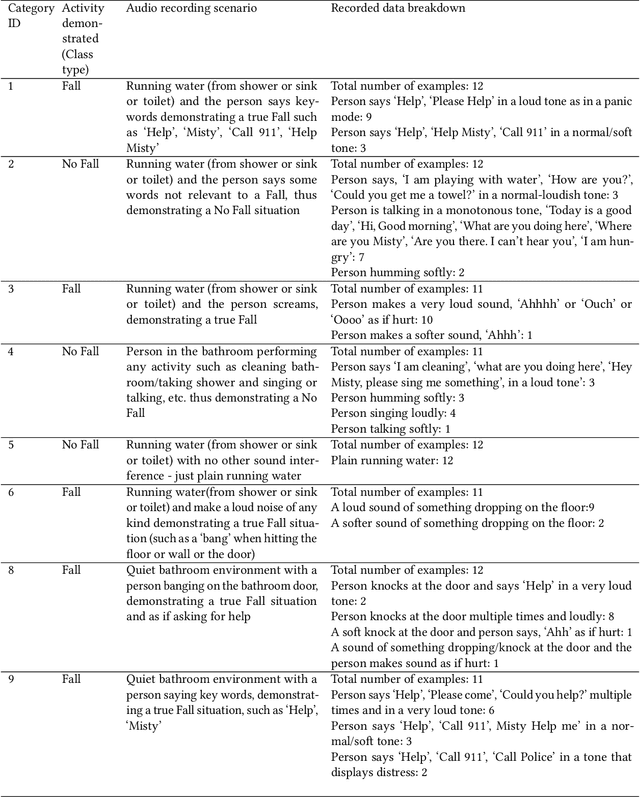
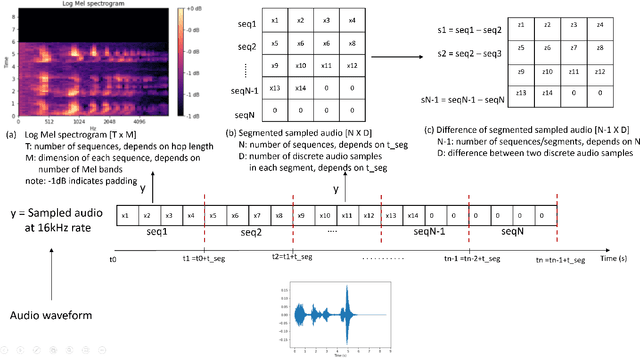
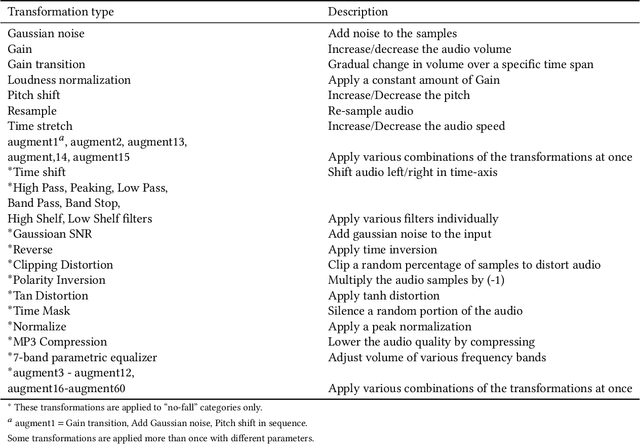
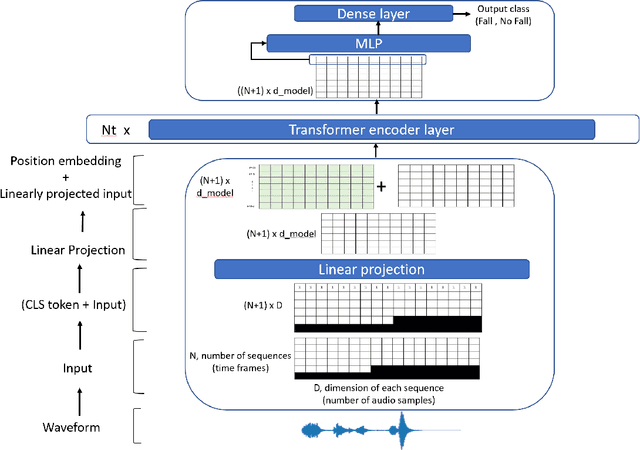
Fall detection for the elderly is a well-researched problem with several proposed solutions, including wearable and non-wearable techniques. While the existing techniques have excellent detection rates, their adoption by the target population is lacking due to the need for wearing devices and user privacy concerns. Our paper provides a novel, non-wearable, non-intrusive, and scalable solution for fall detection, deployed on an autonomous mobile robot equipped with a microphone. The proposed method uses ambient sound input recorded in people's homes. We specifically target the bathroom environment as it is highly prone to falls and where existing techniques cannot be deployed without jeopardizing user privacy. The present work develops a solution based on a Transformer architecture that takes noisy sound input from bathrooms and classifies it into fall/no-fall class with an accuracy of 0.8673. Further, the proposed approach is extendable to other indoor environments, besides bathrooms and is suitable for deploying in elderly homes, hospitals, and rehabilitation facilities without requiring the user to wear any device or be constantly "watched" by the sensors.
Simulators for Mobile Social Robots:State-of-the-Art and Challenges
Feb 08, 2022


The future robots are expected to work in a shared physical space with humans [1], however, the presence of humans leads to a dynamic environment that is challenging for mobile robots to navigate. The path planning algorithms designed to navigate a collision free path in complex human environments are often tested in real environments due to the lack of simulation frameworks. This paper identifies key requirements for an ideal simulator for this task, evaluates existing simulation frameworks and most importantly, it identifies the challenges and limitations of the existing simulation techniques. First and foremost, we recognize that the simulators needed for the purpose of testing mobile robots designed for human environments are unique as they must model realistic pedestrian behavior in addition to the modelling of mobile robots. Our study finds that Pedsim_ros [2] and a more recent SocNavBench framework [3] are the only two 3D simulation frameworks that meet most of the key requirements defined in our paper. In summary, we identify the need for developing more simulators that offer an ability to create realistic 3D pedestrian rich virtual environments along with the flexibility of designing complex robots and their sensor models from scratch.
A Survey on Simulators for Testing Self-Driving Cars
Jan 13, 2021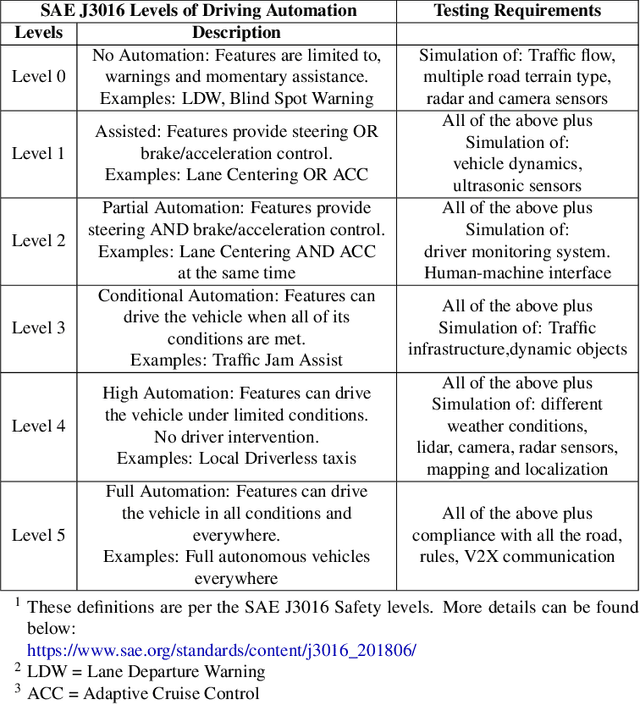
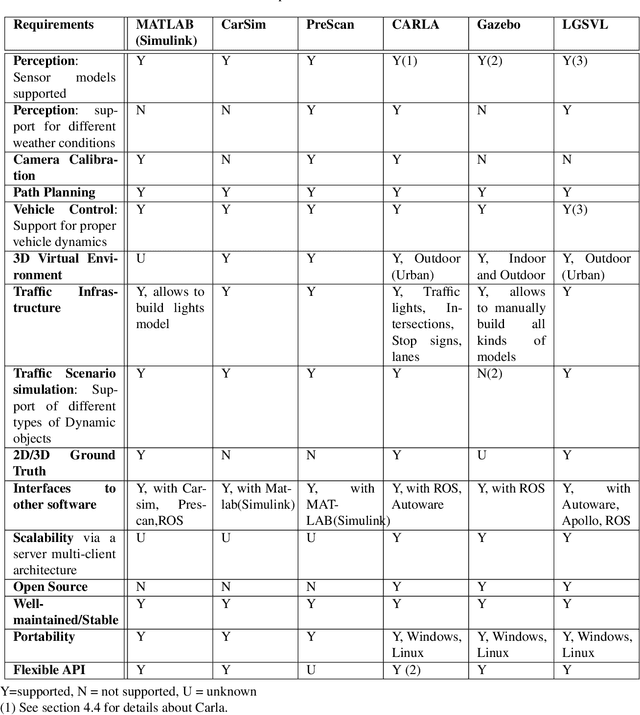
A rigorous and comprehensive testing plays a key role in training self-driving cars to handle variety of situations that they are expected to see on public roads. The physical testing on public roads is unsafe, costly, and not always reproducible. This is where testing in simulation helps fill the gap, however, the problem with simulation testing is that it is only as good as the simulator used for testing and how representative the simulated scenarios are of the real environment. In this paper, we identify key requirements that a good simulator must have. Further, we provide a comparison of commonly used simulators. Our analysis shows that CARLA and LGSVL simulators are the current state-of-the-art simulators for end to end testing of self-driving cars for the reasons mentioned in this paper. Finally, we also present current challenges that simulation testing continues to face as we march towards building fully autonomous cars.
Semantic Features Aided Multi-Scale Reconstruction of Inter-Modality Magnetic Resonance Images
Jun 22, 2020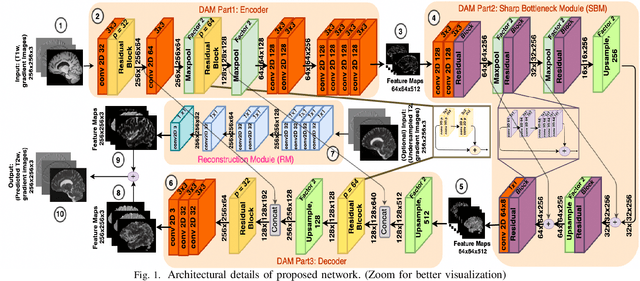
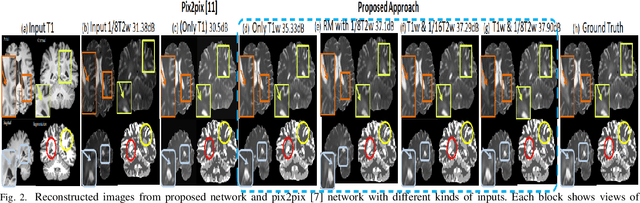
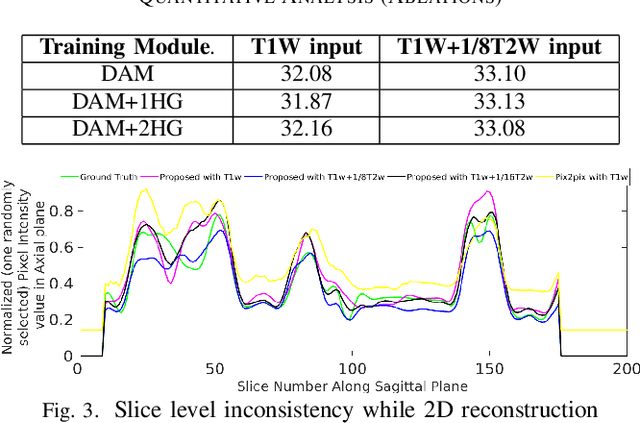

Long acquisition time (AQT) due to series acquisition of multi-modality MR images (especially T2 weighted images (T2WI) with longer AQT), though beneficial for disease diagnosis, is practically undesirable. We propose a novel deep network based solution to reconstruct T2W images from T1W images (T1WI) using an encoder-decoder architecture. The proposed learning is aided with semantic features by using multi-channel input with intensity values and gradient of image in two orthogonal directions. A reconstruction module (RM) augmenting the network along with a domain adaptation module (DAM) which is an encoder-decoder model built-in with sharp bottleneck module (SBM) is trained via modular training. The proposed network significantly reduces the total AQT with negligible qualitative artifacts and quantitative loss (reconstructs one volume in approximately 1 second). The testing is done on publicly available dataset with real MR images, and the proposed network shows (approximately 1dB) increase in PSNR over SOTA.
Learning to Decode 7T-like MR Image Reconstruction from 3T MR Images
Jun 18, 2018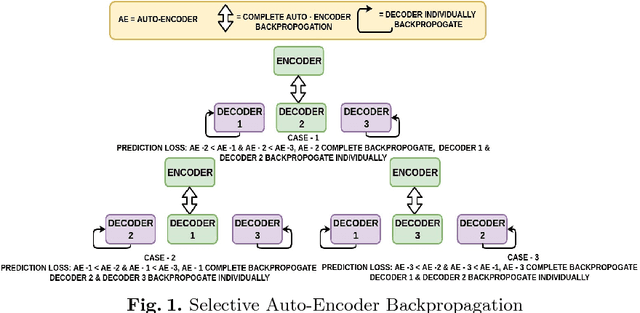
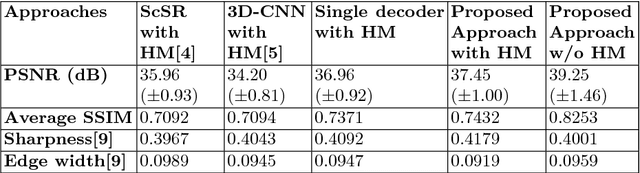
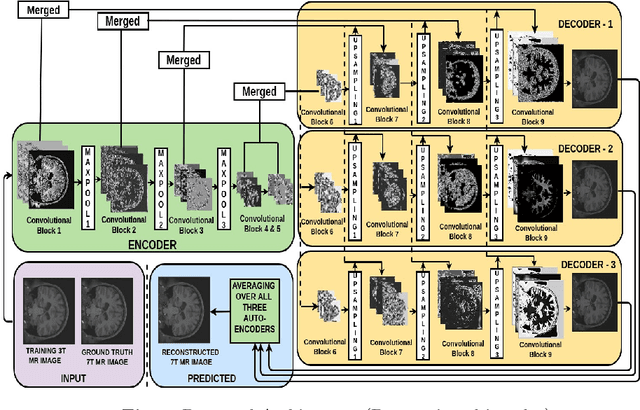
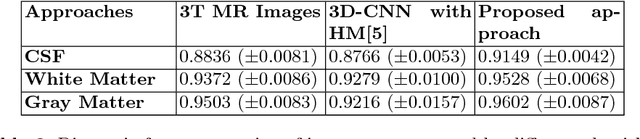
Increasing demand for high field magnetic resonance (MR) scanner indicates the need for high-quality MR images for accurate medical diagnosis. However, cost constraints, instead, motivate a need for algorithms to enhance images from low field scanners. We propose an approach to process the given low field (3T) MR image slices to reconstruct the corresponding high field (7T-like) slices. Our framework involves a novel architecture of a merged convolutional autoencoder with a single encoder and multiple decoders. Specifically, we employ three decoders with random initializations, and the proposed training approach involves selection of a particular decoder in each weight-update iteration for back propagation. We demonstrate that the proposed algorithm outperforms some related contemporary methods in terms of performance and reconstruction time.