 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Secure Retrieval-Augmented Generation: A Comprehensive Review of Threats, Defenses and Benchmarks
Mar 23, 2026Retrieval-Augmented Generation (RAG) significantly mitigates the hallucinations and domain knowledge deficiency in large language models by incorporating external knowledge bases. However, the multi-module architecture of RAG introduces complex system-level security vulnerabilities. Guided by the RAG workflow, this paper analyzes the underlying vulnerability mechanisms and systematically categorizes core threat vectors such as data poisoning, adversarial attacks, and membership inference attacks. Based on this threat assessment, we construct a taxonomy of RAG defense technologies from a dual perspective encompassing both input and output stages. The input-side analysis reviews data protection mechanisms including dynamic access control, homomorphic encryption retrieval, and adversarial pre-filtering. The output-side examination summarizes advanced leakage prevention techniques such as federated learning isolation, differential privacy perturbation, and lightweight data sanitization. To establish a unified benchmark for future experimental design, we consolidate authoritative test datasets, security standards, and evaluation frameworks. To the best of our knowledge, this paper presents the first end-to-end survey dedicated to the security of RAG systems. Distinct from existing literature that isolates specific vulnerabilities, we systematically map the entire pipeline-providing a unified analysis of threat models, defense mechanisms, and evaluation benchmarks. By enabling deep insights into potential risks, this work seeks to foster the development of highly robust and trustworthy next-generation RAG systems.
Diversified Scaling Inference in Time Series Foundation Models
Jan 24, 2026The advancement of Time Series Foundation Models (TSFMs) has been driven primarily by large-scale pre-training, but inference-time compute potential remains largely untapped. This work systematically investigates two questions: how do TSFMs behave under standard sampling-based inference scaling, and can controlled sampling diversity enhance performance? We first examine the properties of TSFMs under standard sampling often fail to adhere to scaling laws due to insufficient exploration of the solution space. Building on this, we then delve into diversified inference scaling via tailored time series perturbations to expand the generative distribution's support. We theoretically analyze the diversity-fidelity trade-off and derive a critical sample threshold for diversified sampling to outperform standard sampling. Extensive experiments across various TSFMs and datasets show proper diversified inference scaling yields substantial performance gains without parameter updates, establishing inference design as a critical, compute-efficient dimension of TSFM optimization. As an application, we propose RobustMSE, a rigorous metric to quantify the headroom performance of TSFM under a fixed budget. Overall, our findings clarify these factor interactions, enabling reliable performance via diverse large-scale inference time series in parallel environments without re-training TSFMs.
ThinkRL-Edit: Thinking in Reinforcement Learning for Reasoning-Centric Image Editing
Jan 06, 2026Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
InstructMoLE: Instruction-Guided Mixture of Low-rank Experts for Multi-Conditional Image Generation
Dec 25, 2025Parameter-Efficient Fine-Tuning of Diffusion Transformers (DiTs) for diverse, multi-conditional tasks often suffers from task interference when using monolithic adapters like LoRA. The Mixture of Low-rank Experts (MoLE) architecture offers a modular solution, but its potential is usually limited by routing policies that operate at a token level. Such local routing can conflict with the global nature of user instructions, leading to artifacts like spatial fragmentation and semantic drift in complex image generation tasks. To address these limitations, we introduce InstructMoLE, a novel framework that employs an Instruction-Guided Mixture of Low-Rank Experts. Instead of per-token routing, InstructMoLE utilizes a global routing signal, Instruction-Guided Routing (IGR), derived from the user's comprehensive instruction. This ensures that a single, coherently chosen expert council is applied uniformly across all input tokens, preserving the global semantics and structural integrity of the generation process. To complement this, we introduce an output-space orthogonality loss, which promotes expert functional diversity and mitigates representational collapse. Extensive experiments demonstrate that InstructMoLE significantly outperforms existing LoRA adapters and MoLE variants across challenging multi-conditional generation benchmarks. Our work presents a robust and generalizable framework for instruction-driven fine-tuning of generative models, enabling superior compositional control and fidelity to user intent.
Sample-efficient LLM Optimization with Reset Replay
Aug 08, 2025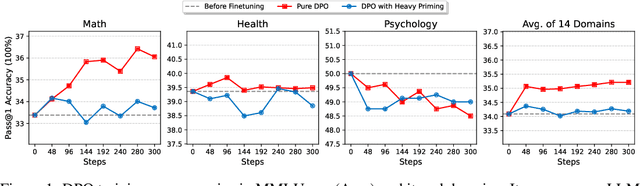
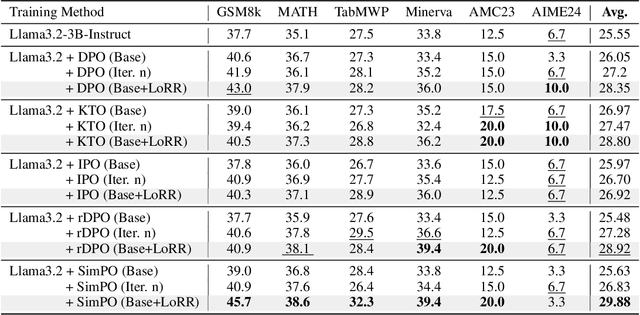
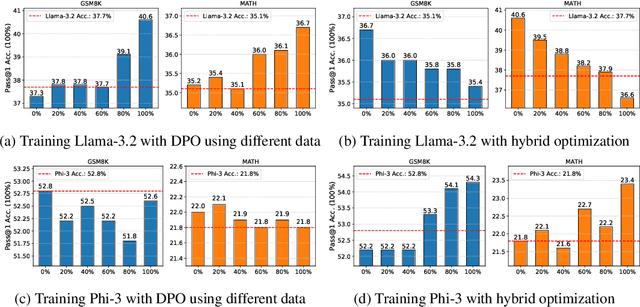
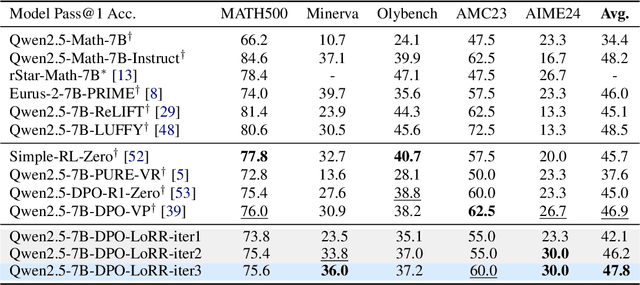
Recent advancements in post-training Large Language Models (LLMs), particularly through Reinforcement Learning (RL) and preference optimization methods, are key drivers for enhancing their reasoning capabilities. However, these methods are often plagued by low sample efficiency and a susceptibility to primacy bias, where overfitting to initial experiences degrades policy quality and damages the learning process. To address these challenges, we introduce LLM optimization with Reset Replay (LoRR), a general and powerful plugin designed to enhance sample efficiency in any preference-based optimization framework. LoRR core mechanism enables training at a high replay number, maximizing the utility of each collected data batch. To counteract the risk of overfitting inherent in high-replay training, LoRR incorporates a periodic reset strategy with reusing initial data, which preserves network plasticity. Furthermore, it leverages a hybrid optimization objective, combining supervised fine-tuning (SFT) and preference-based losses to further bolster data exploitation. Our extensive experiments demonstrate that LoRR significantly boosts the performance of various preference optimization methods on both mathematical and general reasoning benchmarks. Notably, an iterative DPO approach augmented with LoRR achieves comparable performance on challenging math tasks, outperforming some complex and computationally intensive RL-based algorithms. These findings highlight that LoRR offers a practical, sample-efficient, and highly effective paradigm for LLM finetuning, unlocking greater performance from limited data.
Learning Joint ID-Textual Representation for ID-Preserving Image Synthesis
Apr 19, 2025We propose a novel framework for ID-preserving generation using a multi-modal encoding strategy rather than injecting identity features via adapters into pre-trained models. Our method treats identity and text as a unified conditioning input. To achieve this, we introduce FaceCLIP, a multi-modal encoder that learns a joint embedding space for both identity and textual semantics. Given a reference face and a text prompt, FaceCLIP produces a unified representation that encodes both identity and text, which conditions a base diffusion model to generate images that are identity-consistent and text-aligned. We also present a multi-modal alignment algorithm to train FaceCLIP, using a loss that aligns its joint representation with face, text, and image embedding spaces. We then build FaceCLIP-SDXL, an ID-preserving image synthesis pipeline by integrating FaceCLIP with Stable Diffusion XL (SDXL). Compared to prior methods, FaceCLIP-SDXL enables photorealistic portrait generation with better identity preservation and textual relevance. Extensive experiments demonstrate its quantitative and qualitative superiority.
Flux Already Knows - Activating Subject-Driven Image Generation without Training
Apr 12, 2025We propose a simple yet effective zero-shot framework for subject-driven image generation using a vanilla Flux model. By framing the task as grid-based image completion and simply replicating the subject image(s) in a mosaic layout, we activate strong identity-preserving capabilities without any additional data, training, or inference-time fine-tuning. This "free lunch" approach is further strengthened by a novel cascade attention design and meta prompting technique, boosting fidelity and versatility. Experimental results show that our method outperforms baselines across multiple key metrics in benchmarks and human preference studies, with trade-offs in certain aspects. Additionally, it supports diverse edits, including logo insertion, virtual try-on, and subject replacement or insertion. These results demonstrate that a pre-trained foundational text-to-image model can enable high-quality, resource-efficient subject-driven generation, opening new possibilities for lightweight customization in downstream applications.
InfiniteYou: Flexible Photo Recrafting While Preserving Your Identity
Mar 20, 2025Achieving flexible and high-fidelity identity-preserved image generation remains formidable, particularly with advanced Diffusion Transformers (DiTs) like FLUX. We introduce InfiniteYou (InfU), one of the earliest robust frameworks leveraging DiTs for this task. InfU addresses significant issues of existing methods, such as insufficient identity similarity, poor text-image alignment, and low generation quality and aesthetics. Central to InfU is InfuseNet, a component that injects identity features into the DiT base model via residual connections, enhancing identity similarity while maintaining generation capabilities. A multi-stage training strategy, including pretraining and supervised fine-tuning (SFT) with synthetic single-person-multiple-sample (SPMS) data, further improves text-image alignment, ameliorates image quality, and alleviates face copy-pasting. Extensive experiments demonstrate that InfU achieves state-of-the-art performance, surpassing existing baselines. In addition, the plug-and-play design of InfU ensures compatibility with various existing methods, offering a valuable contribution to the broader community.
Humanizing the Machine: Proxy Attacks to Mislead LLM Detectors
Oct 25, 2024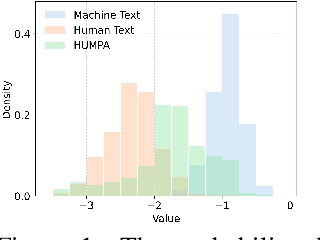
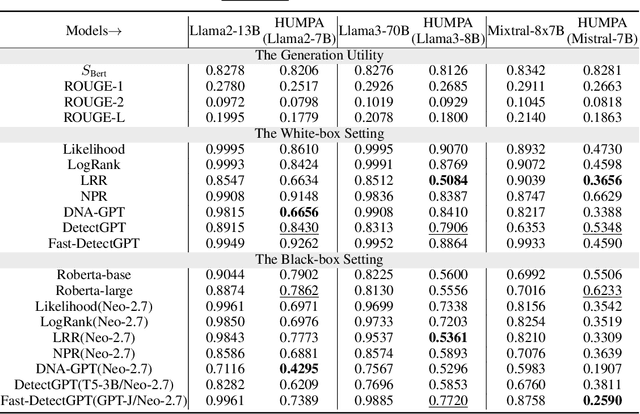
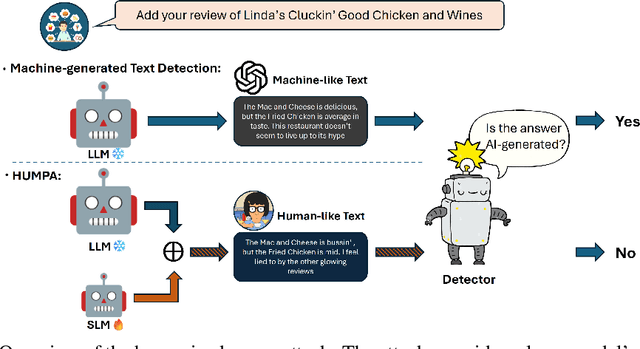
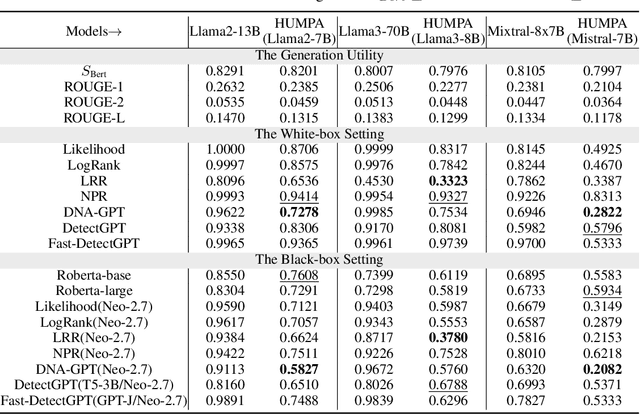
The advent of large language models (LLMs) has revolutionized the field of text generation, producing outputs that closely mimic human-like writing. Although academic and industrial institutions have developed detectors to prevent the malicious usage of LLM-generated texts, other research has doubt about the robustness of these systems. To stress test these detectors, we introduce a proxy-attack strategy that effortlessly compromises LLMs, causing them to produce outputs that align with human-written text and mislead detection systems. Our method attacks the source model by leveraging a reinforcement learning (RL) fine-tuned humanized small language model (SLM) in the decoding phase. Through an in-depth analysis, we demonstrate that our attack strategy is capable of generating responses that are indistinguishable to detectors, preventing them from differentiating between machine-generated and human-written text. We conduct systematic evaluations on extensive datasets using proxy-attacked open-source models, including Llama2-13B, Llama3-70B, and Mixtral-8*7B in both white- and black-box settings. Our findings show that the proxy-attack strategy effectively deceives the leading detectors, resulting in an average AUROC drop of 70.4% across multiple datasets, with a maximum drop of 90.3% on a single dataset. Furthermore, in cross-discipline scenarios, our strategy also bypasses these detectors, leading to a significant relative decrease of up to 90.9%, while in cross-language scenario, the drop reaches 91.3%. Despite our proxy-attack strategy successfully bypassing the detectors with such significant relative drops, we find that the generation quality of the attacked models remains preserved, even within a modest utility budget, when compared to the text produced by the original, unattacked source model.
TraceNet: Segment one thing efficiently
Jun 21, 2024
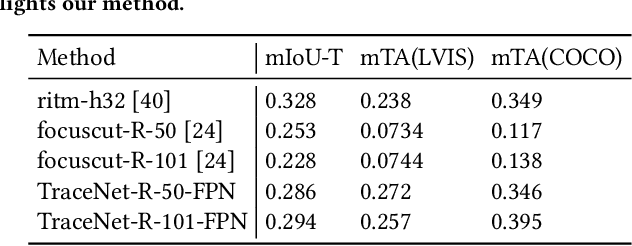
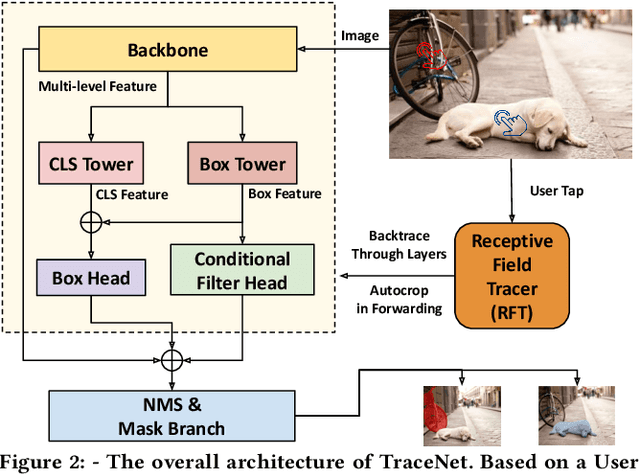

Efficient single instance segmentation is essential for unlocking features in the mobile imaging applications, such as capture or editing. Existing on-the-fly mobile imaging applications scope the segmentation task to portraits or the salient subject due to the computational constraints. Instance segmentation, despite its recent developments towards efficient networks, is still heavy due to the cost of computation on the entire image to identify all instances. To address this, we propose and formulate a one tap driven single instance segmentation task that segments a single instance selected by a user via a positive tap. This task, in contrast to the broader task of segmenting anything as suggested in the Segment Anything Model \cite{sam}, focuses on efficient segmentation of a single instance specified by the user. To solve this problem, we present TraceNet, which explicitly locates the selected instance by way of receptive field tracing. TraceNet identifies image regions that are related to the user tap and heavy computations are only performed on selected regions of the image. Therefore overall computation cost and memory consumption are reduced during inference. We evaluate the performance of TraceNet on instance IoU average over taps and the proportion of the region that a user tap can fall into for a high-quality single-instance mask. Experimental results on MS-COCO and LVIS demonstrate the effectiveness and efficiency of the proposed approach. TraceNet can jointly achieve the efficiency and interactivity, filling in the gap between needs for efficient mobile inference and recent research trend towards multimodal and interactive segmentation models.