 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoldout-Loss-Based Data Selection for LLM Finetuning via In-Context Learning
Oct 16, 2025Fine-tuning large pretrained language models is a common approach for aligning them with human preferences, but noisy or off-target examples can dilute supervision. While small, well-chosen datasets often match the performance of much larger ones, systematic and efficient ways to identify high-value training data remain underexplored. Many current methods rely on heuristics or expensive retraining. We present a theoretically grounded, resource-efficient framework for data selection and reweighting. At its core is an In-Context Approximation (ICA) that estimates the holdout loss a model would incur after training on a candidate example by conditioning on a small, curated holdout set in context. ICA requires no reference model and no additional finetuning. Under a local linearization, ICA is equivalent to a first-order update toward the holdout optimum, motivating its use as a proxy for data value. We derive per-example weights from ICA scores, dynamically reweighting gradient updates as model parameters evolve. Across SFT, DPO, and SimPO, and over diverse backbones and datasets, ICA-based reweighting consistently improves model alignment with minimal overhead. We analyze sensitivity to score update frequency and the choice of $k$ holdout examples for in-context demonstrations, and note limitations for rapidly drifting on-policy updates, highlighting directions for future work. Code and prompts will be released.
HeurAgenix: Leveraging LLMs for Solving Complex Combinatorial Optimization Challenges
Jun 18, 2025Heuristic algorithms play a vital role in solving combinatorial optimization (CO) problems, yet traditional designs depend heavily on manual expertise and struggle to generalize across diverse instances. We introduce \textbf{HeurAgenix}, a two-stage hyper-heuristic framework powered by large language models (LLMs) that first evolves heuristics and then selects among them automatically. In the heuristic evolution phase, HeurAgenix leverages an LLM to compare seed heuristic solutions with higher-quality solutions and extract reusable evolution strategies. During problem solving, it dynamically picks the most promising heuristic for each problem state, guided by the LLM's perception ability. For flexibility, this selector can be either a state-of-the-art LLM or a fine-tuned lightweight model with lower inference cost. To mitigate the scarcity of reliable supervision caused by CO complexity, we fine-tune the lightweight heuristic selector with a dual-reward mechanism that jointly exploits singals from selection preferences and state perception, enabling robust selection under noisy annotations. Extensive experiments on canonical benchmarks show that HeurAgenix not only outperforms existing LLM-based hyper-heuristics but also matches or exceeds specialized solvers. Code is available at https://github.com/microsoft/HeurAgenix.
Position: Rethinking Post-Hoc Search-Based Neural Approaches for Solving Large-Scale Traveling Salesman Problems
Jun 02, 2024



Recent advancements in solving large-scale traveling salesman problems (TSP) utilize the heatmap-guided Monte Carlo tree search (MCTS) paradigm, where machine learning (ML) models generate heatmaps, indicating the probability distribution of each edge being part of the optimal solution, to guide MCTS in solution finding. However, our theoretical and experimental analysis raises doubts about the effectiveness of ML-based heatmap generation. In support of this, we demonstrate that a simple baseline method can outperform complex ML approaches in heatmap generation. Furthermore, we question the practical value of the heatmap-guided MCTS paradigm. To substantiate this, our findings show its inferiority to the LKH-3 heuristic despite the paradigm's reliance on problem-specific, hand-crafted strategies. For the future, we suggest research directions focused on developing more theoretically sound heatmap generation methods and exploring autonomous, generalizable ML approaches for combinatorial problems. The code is available for review: https://github.com/xyfffff/rethink_mcts_for_tsp.
A Versatile Multi-Agent Reinforcement Learning Benchmark for Inventory Management
Jun 13, 2023
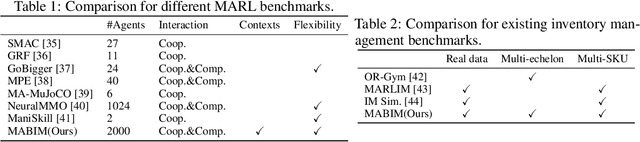

Multi-agent reinforcement learning (MARL) models multiple agents that interact and learn within a shared environment. This paradigm is applicable to various industrial scenarios such as autonomous driving, quantitative trading, and inventory management. However, applying MARL to these real-world scenarios is impeded by many challenges such as scaling up, complex agent interactions, and non-stationary dynamics. To incentivize the research of MARL on these challenges, we develop MABIM (Multi-Agent Benchmark for Inventory Management) which is a multi-echelon, multi-commodity inventory management simulator that can generate versatile tasks with these different challenging properties. Based on MABIM, we evaluate the performance of classic operations research (OR) methods and popular MARL algorithms on these challenging tasks to highlight their weaknesses and potential.