 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π_\texttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
Oct 29, 2025



Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying large-scale RL to flow-based VLAs (e.g., $\pi_0$, $\pi_{0.5}$) remains challenging due to intractable action log-likelihoods from iterative denoising. We address this challenge with $\pi_{\text{RL}}$, an open-source framework for training flow-based VLAs in parallel simulation. $\pi_{\text{RL}}$ implements two RL algorithms: (1) {Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) {Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $\pi_{\text{RL}}$ on LIBERO and ManiSkill benchmarks. On LIBERO, $\pi_{\text{RL}}$ boosts few-shot SFT models $\pi_0$ and $\pi_{0.5}$ from 57.6% to 97.6% and from 77.1% to 98.3%, respectively. In ManiSkill, we train $\pi_{\text{RL}}$ in 320 parallel environments, improving $\pi_0$ from 41.6% to 85.7% and $\pi_{0.5}$ from 40.0% to 84.8% across 4352 pick-and-place tasks, demonstrating scalable multitask RL under heterogeneous simulation. Overall, $\pi_{\text{RL}}$ achieves significant performance gains and stronger generalization over SFT-models, validating the effectiveness of online RL for flow-based VLAs.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
Module-Aware Parameter-Efficient Machine Unlearning on Transformers
Aug 24, 2025Transformer has become fundamental to a vast series of pre-trained large models that have achieved remarkable success across diverse applications. Machine unlearning, which focuses on efficiently removing specific data influences to comply with privacy regulations, shows promise in restricting updates to influence-critical parameters. However, existing parameter-efficient unlearning methods are largely devised in a module-oblivious manner, which tends to inaccurately identify these parameters and leads to inferior unlearning performance for Transformers. In this paper, we propose {\tt MAPE-Unlearn}, a module-aware parameter-efficient machine unlearning approach that uses a learnable pair of masks to pinpoint influence-critical parameters in the heads and filters of Transformers. The learning objective of these masks is derived by desiderata of unlearning and optimized through an efficient algorithm featured by a greedy search with a warm start. Extensive experiments on various Transformer models and datasets demonstrate the effectiveness and robustness of {\tt MAPE-Unlearn} for unlearning.
Autoregressive Meta-Actions for Unified Controllable Trajectory Generation
May 29, 2025



Controllable trajectory generation guided by high-level semantic decisions, termed meta-actions, is crucial for autonomous driving systems. A significant limitation of existing frameworks is their reliance on invariant meta-actions assigned over fixed future time intervals, causing temporal misalignment with the actual behavior trajectories. This misalignment leads to irrelevant associations between the prescribed meta-actions and the resulting trajectories, disrupting task coherence and limiting model performance. To address this challenge, we introduce Autoregressive Meta-Actions, an approach integrated into autoregressive trajectory generation frameworks that provides a unified and precise definition for meta-action-conditioned trajectory prediction. Specifically, We decompose traditional long-interval meta-actions into frame-level meta-actions, enabling a sequential interplay between autoregressive meta-action prediction and meta-action-conditioned trajectory generation. This decomposition ensures strict alignment between each trajectory segment and its corresponding meta-action, achieving a consistent and unified task formulation across the entire trajectory span and significantly reducing complexity. Moreover, we propose a staged pre-training process to decouple the learning of basic motion dynamics from the integration of high-level decision control, which offers flexibility, stability, and modularity. Experimental results validate our framework's effectiveness, demonstrating improved trajectory adaptivity and responsiveness to dynamic decision-making scenarios. We provide the video document and dataset, which are available at https://arma-traj.github.io/.
DisasterM3: A Remote Sensing Vision-Language Dataset for Disaster Damage Assessment and Response
May 27, 2025Large vision-language models (VLMs) have made great achievements in Earth vision. However, complex disaster scenes with diverse disaster types, geographic regions, and satellite sensors have posed new challenges for VLM applications. To fill this gap, we curate a remote sensing vision-language dataset (DisasterM3) for global-scale disaster assessment and response. DisasterM3 includes 26,988 bi-temporal satellite images and 123k instruction pairs across 5 continents, with three characteristics: 1) Multi-hazard: DisasterM3 involves 36 historical disaster events with significant impacts, which are categorized into 10 common natural and man-made disasters. 2)Multi-sensor: Extreme weather during disasters often hinders optical sensor imaging, making it necessary to combine Synthetic Aperture Radar (SAR) imagery for post-disaster scenes. 3) Multi-task: Based on real-world scenarios, DisasterM3 includes 9 disaster-related visual perception and reasoning tasks, harnessing the full potential of VLM's reasoning ability with progressing from disaster-bearing body recognition to structural damage assessment and object relational reasoning, culminating in the generation of long-form disaster reports. We extensively evaluated 14 generic and remote sensing VLMs on our benchmark, revealing that state-of-the-art models struggle with the disaster tasks, largely due to the lack of a disaster-specific corpus, cross-sensor gap, and damage object counting insensitivity. Focusing on these issues, we fine-tune four VLMs using our dataset and achieve stable improvements across all tasks, with robust cross-sensor and cross-disaster generalization capabilities.
DRoPE: Directional Rotary Position Embedding for Efficient Agent Interaction Modeling
Mar 19, 2025Accurate and efficient modeling of agent interactions is essential for trajectory generation, the core of autonomous driving systems. Existing methods, scene-centric, agent-centric, and query-centric frameworks, each present distinct advantages and drawbacks, creating an impossible triangle among accuracy, computational time, and memory efficiency. To break this limitation, we propose Directional Rotary Position Embedding (DRoPE), a novel adaptation of Rotary Position Embedding (RoPE), originally developed in natural language processing. Unlike traditional relative position embedding (RPE), which introduces significant space complexity, RoPE efficiently encodes relative positions without explicitly increasing complexity but faces inherent limitations in handling angular information due to periodicity. DRoPE overcomes this limitation by introducing a uniform identity scalar into RoPE's 2D rotary transformation, aligning rotation angles with realistic agent headings to naturally encode relative angular information. We theoretically analyze DRoPE's correctness and efficiency, demonstrating its capability to simultaneously optimize trajectory generation accuracy, time complexity, and space complexity. Empirical evaluations compared with various state-of-the-art trajectory generation models, confirm DRoPE's good performance and significantly reduced space complexity, indicating both theoretical soundness and practical effectiveness. The video documentation is available at https://drope-traj.github.io/.
CFSafety: Comprehensive Fine-grained Safety Assessment for LLMs
Oct 29, 2024As large language models (LLMs) rapidly evolve, they bring significant conveniences to our work and daily lives, but also introduce considerable safety risks. These models can generate texts with social biases or unethical content, and under specific adversarial instructions, may even incite illegal activities. Therefore, rigorous safety assessments of LLMs are crucial. In this work, we introduce a safety assessment benchmark, CFSafety, which integrates 5 classic safety scenarios and 5 types of instruction attacks, totaling 10 categories of safety questions, to form a test set with 25k prompts. This test set was used to evaluate the natural language generation (NLG) capabilities of LLMs, employing a combination of simple moral judgment and a 1-5 safety rating scale for scoring. Using this benchmark, we tested eight popular LLMs, including the GPT series. The results indicate that while GPT-4 demonstrated superior safety performance, the safety effectiveness of LLMs, including this model, still requires improvement. The data and code associated with this study are available on GitHub.
Retrieving snow depth distribution by downscaling ERA5 Reanalysis with ICESat-2 laser altimetry
Oct 23, 2024Estimating the variability of seasonal snow cover, in particular snow depth in remote areas, poses significant challenges due to limited spatial and temporal data availability. This study uses snow depth measurements from the ICESat-2 satellite laser altimeter, which are sparse in both space and time, and incorporates them with climate reanalysis data into a downscaling-calibration scheme to produce monthly gridded snow depth maps at microscale (10 m). Snow surface elevation measurements from ICESat-2 along profiles are compared to a digital elevation model to determine snow depth at each point. To efficiently turn sparse measurements into snow depth maps, a regression model is fitted to establish a relationship between the retrieved snow depth and the corresponding ERA5 Land snow depth. This relationship, referred to as subgrid variability, is then applied to downscale the monthly ERA5 Land snow depth data. The method can provide timeseries of monthly snow depth maps for the entire ERA5 time range (since 1950). The validation of downscaled snow depth data was performed at an intermediate scale (100 m x 500 m) using datasets from airborne laser scanning (ALS) in the Hardangervidda region of southern Norway. Results show that snow depth prediction achieved R2 values ranging from 0.74 to 0.88 (post-calibration). The method relies on globally available data and is applicable to other snow regions above the treeline. Though requiring area-specific calibration, our approach has the potential to provide snow depth maps in areas where no such data exist and can be used to extrapolate existing snow surveys in time and over larger areas. With this, it can offer valuable input data for hydrological, ecological or permafrost modeling tasks.
Position: Rethinking Post-Hoc Search-Based Neural Approaches for Solving Large-Scale Traveling Salesman Problems
Jun 02, 2024



Recent advancements in solving large-scale traveling salesman problems (TSP) utilize the heatmap-guided Monte Carlo tree search (MCTS) paradigm, where machine learning (ML) models generate heatmaps, indicating the probability distribution of each edge being part of the optimal solution, to guide MCTS in solution finding. However, our theoretical and experimental analysis raises doubts about the effectiveness of ML-based heatmap generation. In support of this, we demonstrate that a simple baseline method can outperform complex ML approaches in heatmap generation. Furthermore, we question the practical value of the heatmap-guided MCTS paradigm. To substantiate this, our findings show its inferiority to the LKH-3 heuristic despite the paradigm's reliance on problem-specific, hand-crafted strategies. For the future, we suggest research directions focused on developing more theoretically sound heatmap generation methods and exploring autonomous, generalizable ML approaches for combinatorial problems. The code is available for review: https://github.com/xyfffff/rethink_mcts_for_tsp.
A Versatile Multi-Agent Reinforcement Learning Benchmark for Inventory Management
Jun 13, 2023
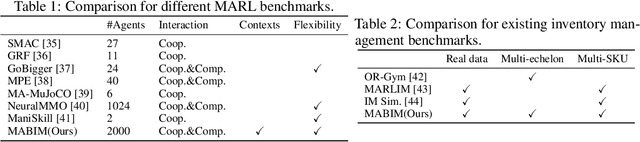

Multi-agent reinforcement learning (MARL) models multiple agents that interact and learn within a shared environment. This paradigm is applicable to various industrial scenarios such as autonomous driving, quantitative trading, and inventory management. However, applying MARL to these real-world scenarios is impeded by many challenges such as scaling up, complex agent interactions, and non-stationary dynamics. To incentivize the research of MARL on these challenges, we develop MABIM (Multi-Agent Benchmark for Inventory Management) which is a multi-echelon, multi-commodity inventory management simulator that can generate versatile tasks with these different challenging properties. Based on MABIM, we evaluate the performance of classic operations research (OR) methods and popular MARL algorithms on these challenging tasks to highlight their weaknesses and potential.